



























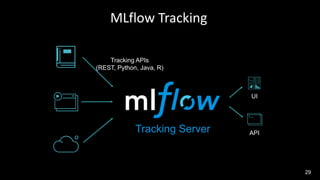
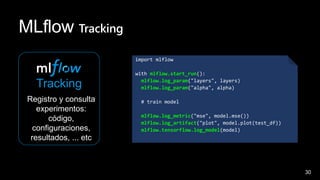


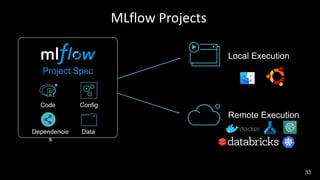





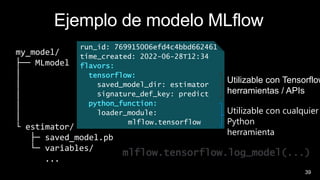









Este documento describe cómo integrar Azure Synapse con MLflow para habilitar el seguimiento de experimentos de aprendizaje automático y el registro y despliegue de modelos en Azure Machine Learning. Explica cómo configurar los cuadernos de Azure Synapse para usar MLflow conectado a un área de trabajo de Azure Machine Learning, registrar modelos entrenados en Synapse en el registro de modelos de Azure ML y desplegarlos para su uso.















































