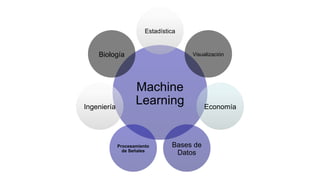
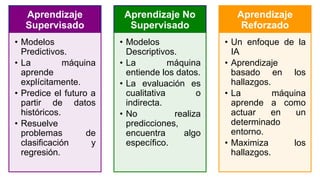
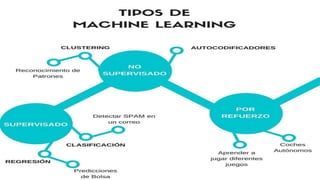
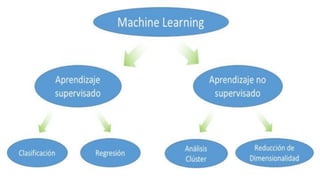
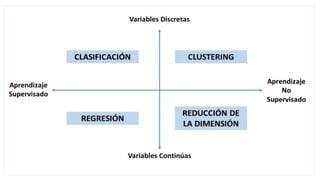
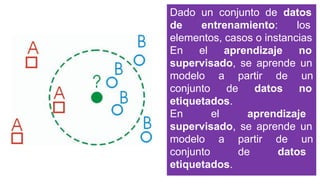
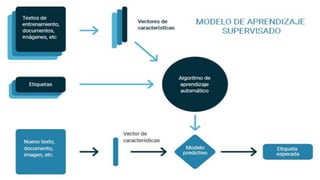
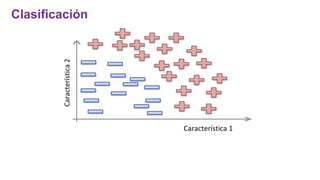
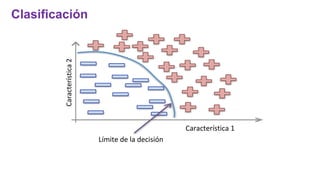
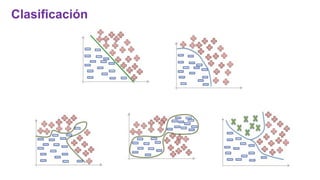
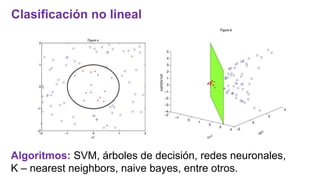
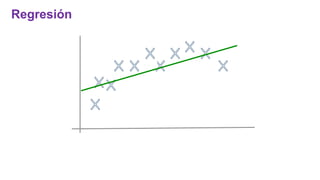
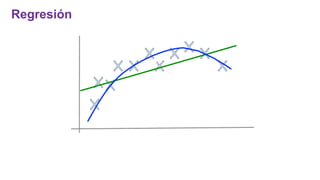
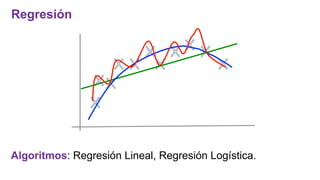
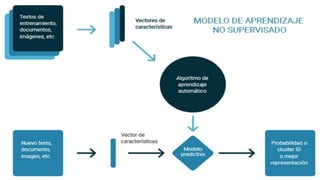
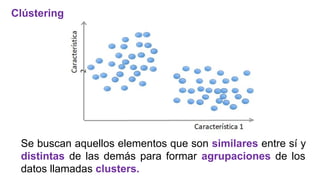
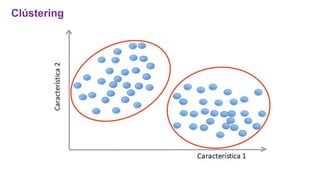
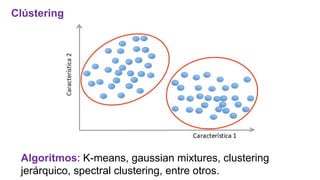
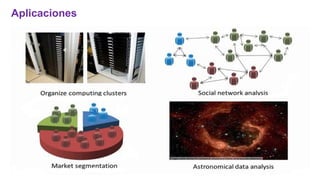
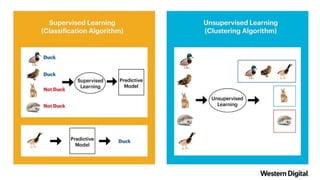
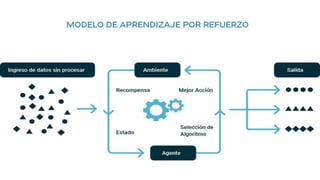
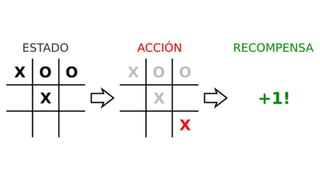
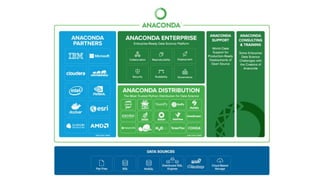
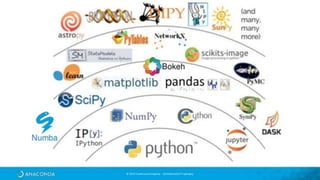
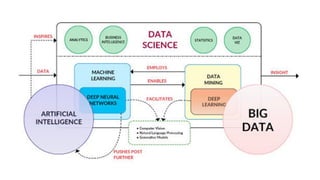
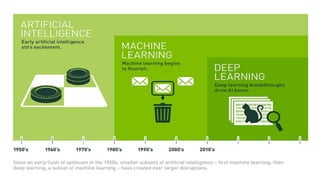
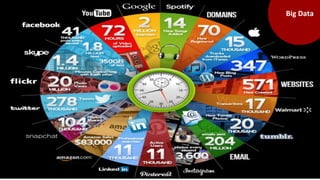
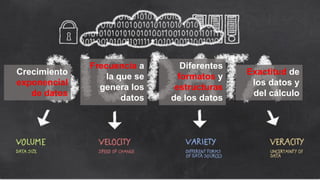
El documento proporciona una visión general del aprendizaje automático (machine learning), destacando su definición, tipos de aprendizaje (supervisado, no supervisado y reforzado) y sus aplicaciones. El aprendizaje supervisado se basa en datos etiquetados para hacer predicciones, el no supervisado no requiere etiquetas y busca patrones en los datos, mientras que el reforzado se centra en la toma de decisiones para maximizar resultados. Además, se menciona software relevante y el ecosistema del machine learning en relación con la ciencia de datos.