








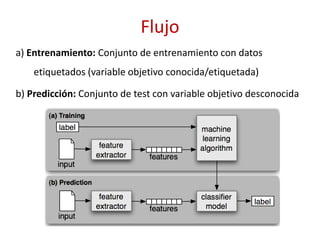

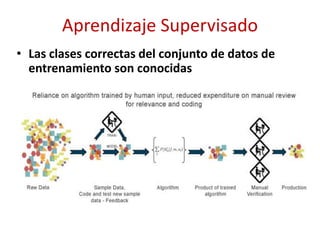
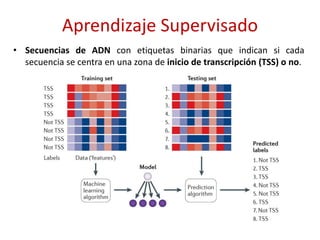
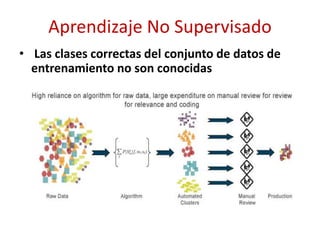














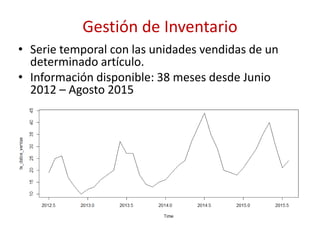
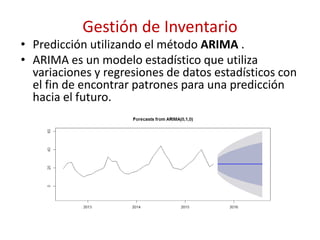
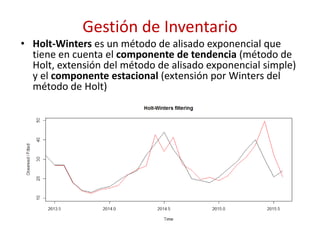
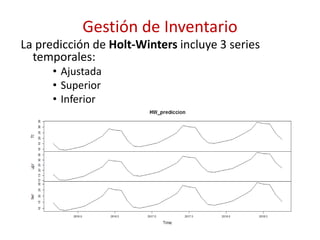
![Gestión de Inventario
• Descomponemos la serie original en componentes Y[t] = T[t] + S[t] + e[t]
– Componente estacional (S[t]) Oscilaciones con periodicidad anual o
submúltiplos del año
– Componente Tendencial (T[t]) Recoge la parte de la variable vinculada
principalmente con factores de largo plazo.
– Componente de Irregular/Error (e[t]) Se determina al quitar los
componentes estacional y el tendencial de la serie original](https://image.slidesharecdn.com/introduccionamachinelearning-160606134936/85/Introduccion-a-Machine-Learning-35-320.jpg)
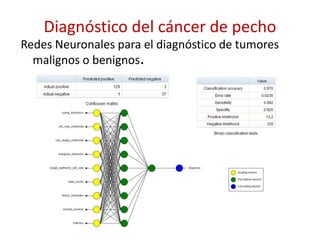



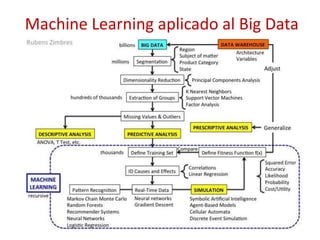





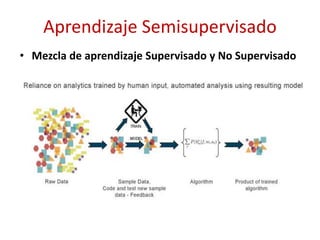
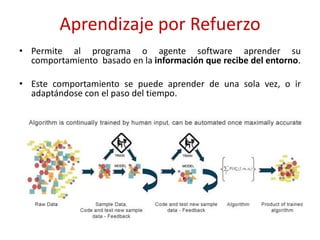
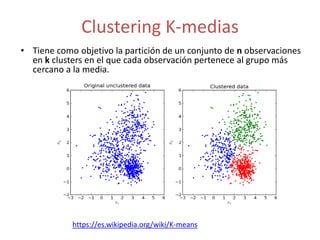
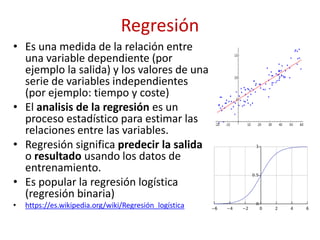
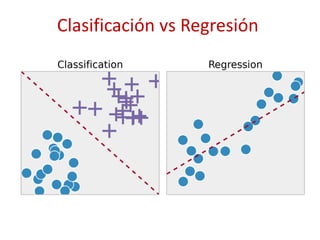
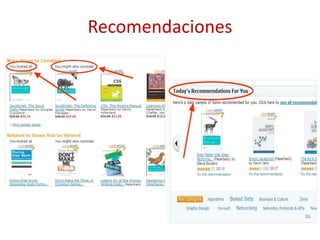
Este documento presenta una introducción al machine learning o aprendizaje automático. Explica que es un campo de la inteligencia artificial que trata de construir sistemas que aprenden de los datos. Describe las principales técnicas de machine learning como clasificación, clustering y regresión. También menciona algunos casos de uso como detección de spam, traducción automática y recomendaciones.










































































