Descargar como PDF, PPTX

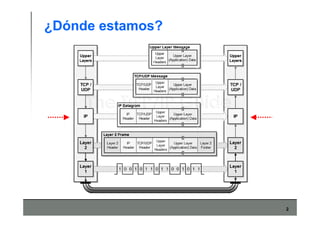





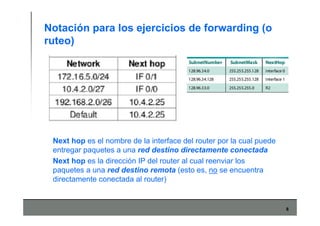
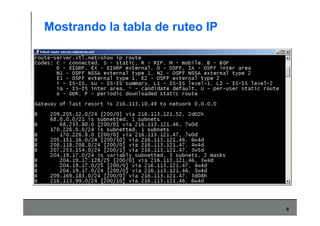
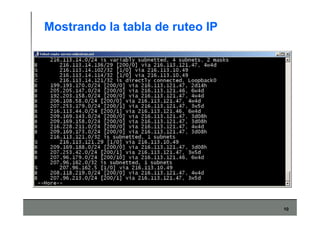
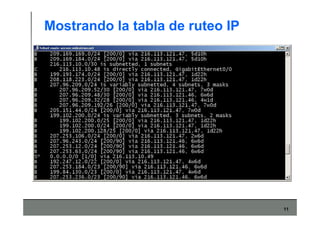
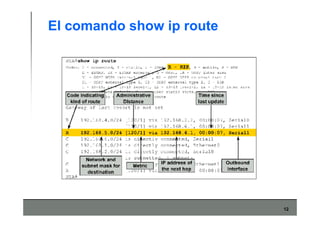


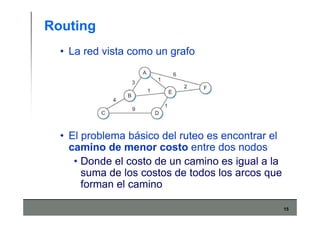
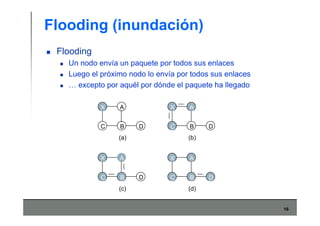



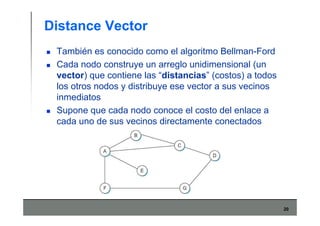
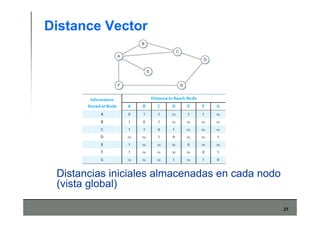
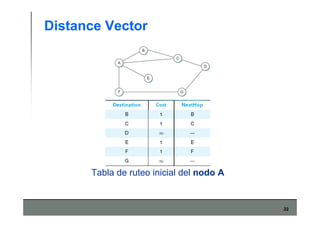

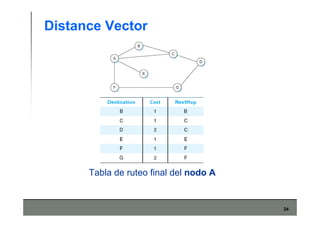
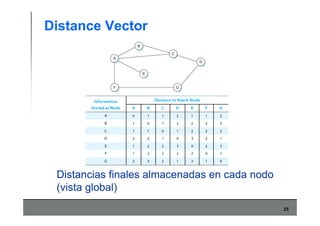
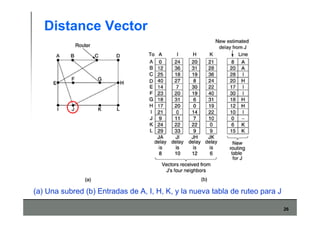

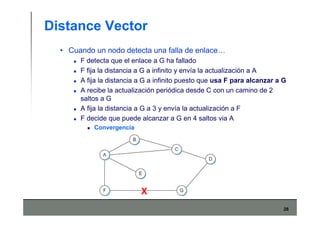
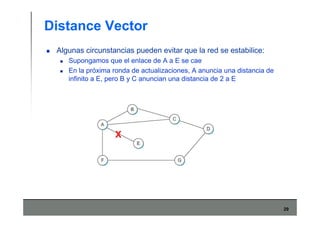
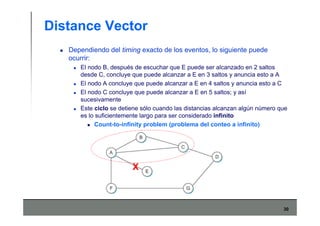

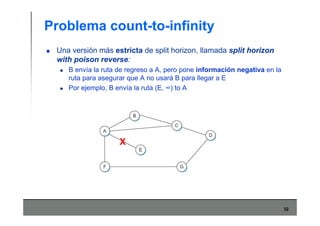

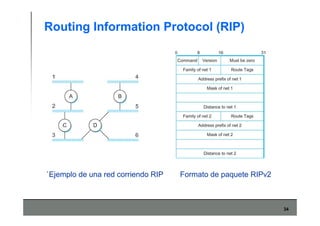





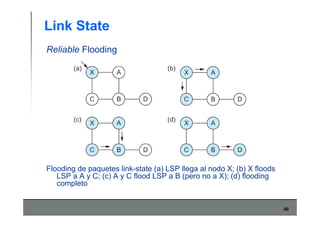



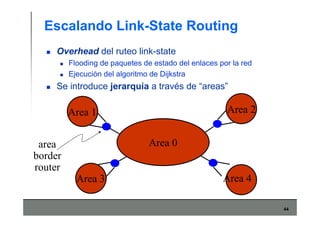


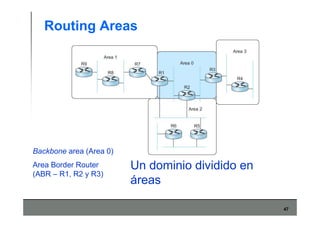

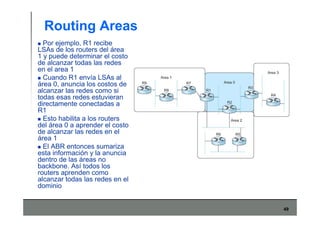
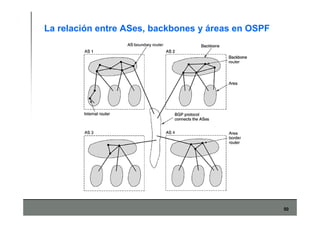
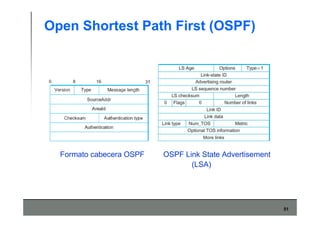










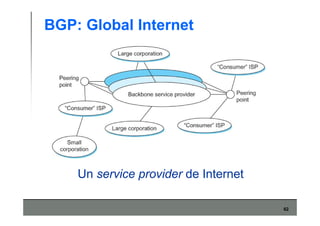

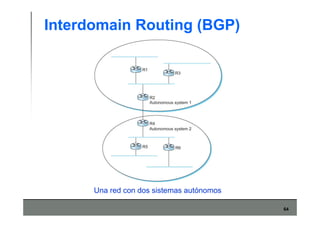


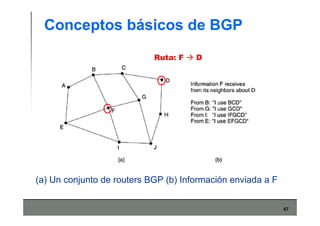



Este documento describe los conceptos básicos de routing en redes de computadoras. Explica que el routing implica construir tablas de ruteo dinámicas que indican cómo llegar a destinos remotos, y que existen dos enfoques principales: distance vector y link state. Distance vector usa actualizaciones periódicas entre vecinos, mientras que link state difunde paquetes con la información de enlaces a toda la red para que cada nodo calcule rutas de forma independiente. También presenta ejemplos como RIP, OSPF e IS-IS.


























![E:\Vilma[1] [Reparado]](https://cdn.slidesharecdn.com/ss_thumbnails/evilma1reparado-100812100556-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































































