Descargar para leer sin conexión










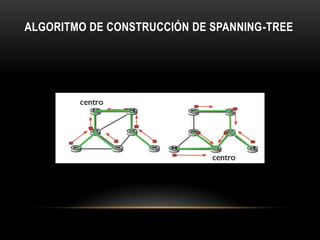



Este documento trata sobre diferentes métodos de enrutamiento en redes de computadoras. Describe enrutamiento por vector de distancia, en el cual cada nodo mantiene un vector con las distancias a otros nodos y lo distribuye; enrutamiento jerárquico, donde la red se divide en regiones para reducir la información que deben manejar los routers; y enrutamiento por difusión para enviar mensajes a todos los nodos, discutiendo métodos como inundación controlada y construcción de árboles de expansión.













![E:\Vilma[1] [Reparado]](https://cdn.slidesharecdn.com/ss_thumbnails/evilma1reparado-100812100556-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































































