R
´
Taller de Introduccion
Blanca A. Vargas Govea
blanca.vg@gmail.com
cenidet
Cuernavaca, Mor., 11 de Noviembre de 2011
2.
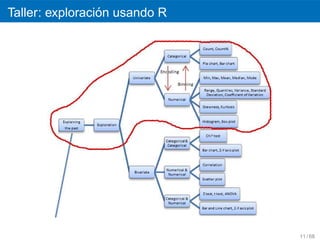
Contenido
´
1 Introduccion
´
2 Tipos de datos y funciones basicas
´
3 Analisis descriptivo
´
4 Graficas
´ ´
Graficas estandar
ggplot2
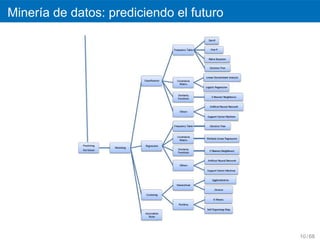
5 Miner´a de datos
ı
6 Otros recursos
2 / 68
3.
R y yo
´ ´
Evaluacion de sistemas de recomendacion.
´
Analisis descriptivo de datos.
´ ´
Manipulacion de datos: construccion de archivos.
Usuario-item-rating.
Contexto.
´
Seleccion de atributos.
´
Scripts para evaluacion.
´
Graficas.
R es parte de las herramientas, otras: Weka, scripts en Python, Excel.
3 / 68
4.
´
¿Que es R?
Lenguaje.
´
Manipulacion de datos.
´
Tecnicas estad´sticas.
ı
´
Graficas.
´
Entorno para proceso estad´stico y visualizacion.
ı
Software libre.
4 / 68
5.
´ ´
¿Por que R?: Satisfaccion
http://www.rexeranalytics.com/
5 / 68
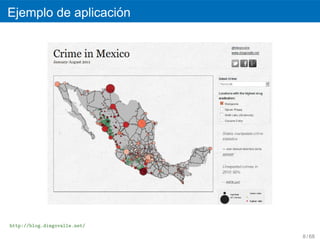
´
¿Por que esimportante?
´ ´
Describe los datos mediante tecnicas estad´sticas y graficas.
ı
Da un primer acercamiento a los datos y extrae caracter´sticas
ı
´ ´
importantes que se utilizaran para analisis posteriores.
´
Util para encontrar errores, ver patrones en los datos, encontrar y
´
generar hipotesis.
12 / 68
´
Instalacion
Instalar R [R Development Core Team, 2010] . Disponible para
Linux, MacOS X y Windows:
en http://cran.r-project.org/mirrors.html.
Puede usarse en consola o instalar un IDE.
Sugerencia: RStudio http://www.rstudio.org/.
´
El conjunto de datos que se usara es credit-g.csv [Hofmann, 1994].
En modo consola:
$ R
14 / 68
15.
´
Como obtener ayuda
help.start() # ayuda general
help(nombrefuncion) # detalles sobre la func.
?funcion # igual que el anterior
apropos("solve") # lista funciones que contienen "solve"
example(solve) # muestra un ejemplo del uso de "solve"
help("*")
vignette()
vignette("foo")
data() # muestra los datos disponibles
help(datasetname) # detalles de los datos
15 / 68
16.
Espacio de trabajo
´
Es el entorno de tu sesion actual en R e incluye cualquier objeto:
vectores, matrices, dataframes, listas, funciones.
´
Al finalizar la sesion se puede guardar el actual espacio de
´
trabajo para que automaticamente se cargue en la siguiente.
´
Algunos comandos estandar para definir el espacio de trabajo son los
siguientes:
getwd() # muestra el directorio actual
ls() # lista los objetos en el espacio de trabajo
setwd(mydirectory) # cambia el path a mydirectory
setwd("c:/docs/mydir") # notar / en vez de en Windows
setwd("/usr/rob/mydir") # en Linux
history() # despliega los 25 comandos recientes
history(max.show=Inf) # despliega los comandos previos
q() # quit R.
16 / 68
17.
Paquetes
.libPaths() # obtieneel path
library() # muestra los paquetes instalados
search() # muestra los paquetes cargados
# descarga e instala paquetes del repositorio CRAN
install.packages("nombredelpaquete")
library(package) # carga el paquete
17 / 68
18.
Scripts
# en Linux
RCMD BATCH [options] my_script.R [outfile]
# en ms windows (ajustar el path a R.exe)
"C:Program FilesRR-2.5.0binR.exe" CMD BATCH
--vanilla --slave "c:my projectsmy_script.R"
source("myfile")
sink("record.lis") # la salida va al archivo record.lis
18 / 68
Despliegue de objetos
ls()# lista de objetos
names(credit) # variables de credit
str(credit) # estructura de credit
levels(credit$foreign_worker) # niveles(valores de variable)
dim(credit) # dimensiones (ren x cols)
class(credit) # clase del objeto
credit # objeto
head(credit, n=10)
tail(credit, n=10)
credit$purpose
#purpose
attach(credit) # coloca la bd en el path
purpose
24 / 68
25.
´
Renglones, columnas, m´nimoy maximo
ı
# Explorando conteo
ren <- nrow(credit) # raw row count
col <- ncol(credit)
# Min y Max
agemin <- min(age,na.rm = TRUE) # min sin NULLS en age
agemax <- max(age,na.rm = TRUE)
ammin <- min(credit_amount,na.rm = TRUE)
ammax <- max(credit_amount,na.rm = TRUE)
25 / 68
´
Conceptos basicos
´
Poblacion
´
Es el conjunto completo de elementos de nuestro interes.
´
Las caracter´sticas de una poblacion son las medidas
ı
estad´sticas de cada uno de sus elementos.
ı
32 / 68
34.
´
Conceptos basicos
´
Poblacion
´
Es el conjunto completo de elementos de nuestro interes.
´
Las caracter´sticas de una poblacion son las medidas
ı
estad´sticas de cada uno de sus elementos.
ı
Muestra
´ ´
Es una proporcion de la poblacion. Una muestra posee
´
las mismas caracter´sticas de la poblacion si se obtiene
ı
aleatoriamente.
32 / 68
35.
´
Conceptos basicos
´
Poblacion
´
Es el conjunto completo de elementos de nuestro interes.
´
Las caracter´sticas de una poblacion son las medidas
ı
estad´sticas de cada uno de sus elementos.
ı
Muestra
´ ´
Es una proporcion de la poblacion. Una muestra posee
´
las mismas caracter´sticas de la poblacion si se obtiene
ı
aleatoriamente.
[Bartlein, 2009, Trochim, 2006, Quick, 2009, Wackerly et al., 2002]
32 / 68
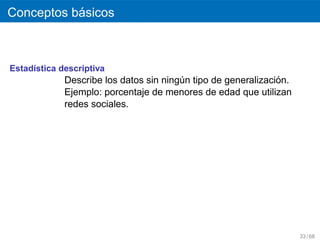
´
Conceptos basicos
Estad´stica descriptiva
ı
´
Describe los datos sin ningun tipo de generalizacion.
´
Ejemplo: porcentaje de menores de edad que utilizan
redes sociales.
33 / 68
38.
´
Conceptos basicos
Estad´stica descriptiva
ı
´
Describe los datos sin ningun tipo de generalizacion.
´
Ejemplo: porcentaje de menores de edad que utilizan
redes sociales.
Inferencia estad´stica
ı
Generaliza o induce algunas propiedades de la poblacion ´
a partir de la cual los datos se tomaron. Ejemplo: ¿es la
´
satisfaccion del usuario de sistemas de recomendacion ´
significativamente diferente entre hombres y mujeres?
33 / 68
39.
´
Conceptos basicos
´
Variables categoricas
´
No aparecen de forma numerica y tienen dos o mas ´
categor´as o valores. Pueden ser nominales y ordinales.
ı
Una variable nominal no tiene un orden (e.g., rojo,
amarillo, suave), mientras que la ordinal designa un orden
(e.g., primer lugar, segundo lugar).
34 / 68
40.
´
Conceptos basicos
´
Variables categoricas
´
No aparecen de forma numerica y tienen dos o mas ´
categor´as o valores. Pueden ser nominales y ordinales.
ı
Una variable nominal no tiene un orden (e.g., rojo,
amarillo, suave), mientras que la ordinal designa un orden
(e.g., primer lugar, segundo lugar).
´
Variables numericas
Son aquellas que pueden tomar cualquier valor dentro de
un intervalo finito o infinito.
34 / 68
41.
´
Tipos de analisis
Univariable
en el cual se exploran las variables o atributos uno por
uno.
Bivariable
´
en el cual simultaneamente se analizan dos variables
´
para conocer la relacion entre ellas, su fuerza o si hay
´
diferencias entre ellas y el significado de las mismas. El
´
analisis bivariable puede ser entre dos variables
´ ´ ´
numericas, dos variables categoricas y una variable
´ ´
numerica y una categorica.
35 / 68
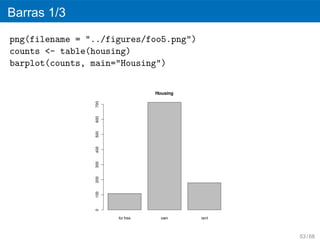
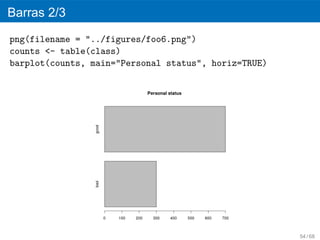
42.
´
Analisis univariable
´
Variables categoricas
´ ´
el analisis exploratorio basicamente es un conteo del
numero de valores de la variable especificada y el
´
porcentaje de valores de la variable espec´fica. Se
ı
´
utilizan las graficas de barras y de pay.
´
Variables numericas
´
se analizan calculando el m´nimo, maximo, media,
ı
mediana, moda, rango, los cuantiles, la varianza, la
´ ´ ´
desviacion estandar, el coeficiente de variacion, la
asimetr´a y la curtosis. Se visualizan mediante
ı
´
histogramas y graficas de bigotes.
36 / 68
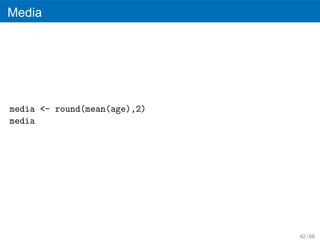
43.
Medidas
Min, max Cuantiles (25,50,75)
Media Varianza
Mediana ´ ´
Desviacion estandar
Moda Asimetr´a
ı
Rango Curtosis
37 / 68
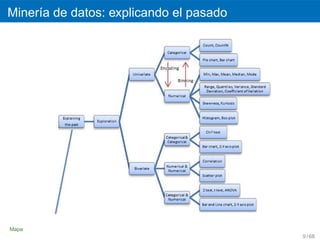
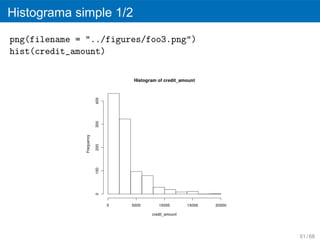
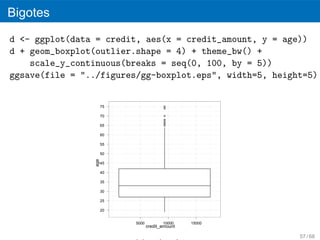
Bigotes
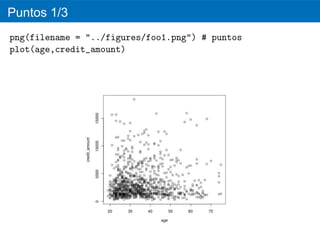
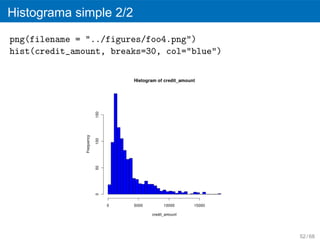
png(filename = "../figures/foo2.png")
boxplot(age)
´ ´
Un valor at´pico es una observacion numericamente distante del resto de los
ı
´
datos y puede representar datos erroneos. Se considera un valor at´pico el
ı
que se encuentra 1,5 veces esa distancia de uno de esos cuartiles (at´pico
ı
leve) o a 3 veces esa distancia (at´pico extremo).
ı
50 / 68
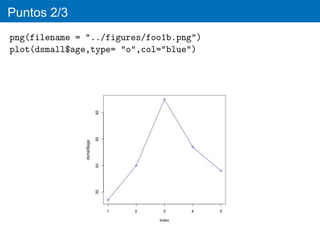
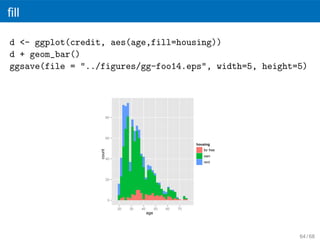
fill
d <- ggplot(credit,aes(age,fill=housing))
d + geom_bar()
ggsave(file = "../figures/gg-foo14.eps", width=5, height=5)
80
60
housing
for free
count
own
40
rent
20
0
20 30 40 50 60 70
age
64 / 68
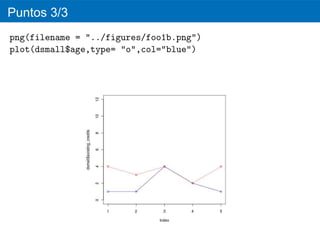
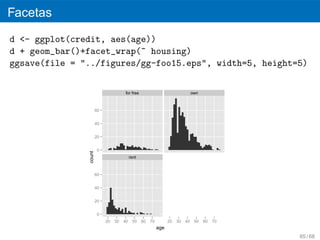
71.
Facetas
d <- ggplot(credit,aes(age))
d + geom_bar()+facet_wrap(~ housing)
ggsave(file = "../figures/gg-foo15.eps", width=5, height=5)
for free own
60
40
20
0
count
rent
60
40
20
0
20 30 40 50 60 70 20 30 40 50 60 70
age
65 / 68
72.
Miner´a de datos:librer´as
ı ı
´
Clasificacion.
´
Regresion lineal en R.
´ ´
Particionamiento recursivo y arboles de regresion
´ ´ ´
Clasificacion y arboles de regresion
nnet: redes neuronales feed-forward
´
Agrupacion.
´
Agrupacion en R
´
Reglas de asociacion.
´
arules: Reglas de asociacion
´
Seleccion de atributos.
FSelector: Selecting attributes
Caret: librer´as diversas
ı
Miner´a de textos.
ı
tm: librer´a para miner´a de texto
ı ı
66 / 68
73.
Otros recursos
Machine learning
R with Python
´
Comparacion
Libro
67 / 68
74.
´
R Taller de Introduccion is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
68 / 68
75.
Bartlein, P. (2009).
Dataanalysis and visualization.
http://geography.uoregon.edu/bartlein/old_courses/geog414f03/lectures/lec04.htm.
Hofmann, H. (1994).
UCI machine learning repository.
http://bit.ly/laDAFC.
Quick, J. M. (2009).
R tutorial series: Summary and descriptive statistics.
http://www.r-bloggers.com/r-tutorial-series-summary-and-descriptive-statistics/.
R Development Core Team (2010).
R: A language and environment for statistical computing.
http://www.R-project.org.
Trochim, W. M. (2006).
Research methods knowledge base.
http://geography.uoregon.edu/bartlein/old_courses/geog414f03/lectures/lec04.htm.
Wackerly, D. D., Scheaffer, R. L., & Mendenhall, W. (2002).
´
Estad´stica matematica con aplicaciones.
ı
´
Mexico, 6 edition.
68 / 68











![´
Instalacion
Instalar R [R Development Core Team, 2010] . Disponible para
Linux, MacOS X y Windows:
en http://cran.r-project.org/mirrors.html.
Puede usarse en consola o instalar un IDE.
Sugerencia: RStudio http://www.rstudio.org/.
´
El conjunto de datos que se usara es credit-g.csv [Hofmann, 1994].
En modo consola:
$ R
14 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-14-320.jpg)



![Scripts
# en Linux
R CMD BATCH [options] my_script.R [outfile]
# en ms windows (ajustar el path a R.exe)
"C:Program FilesRR-2.5.0binR.exe" CMD BATCH
--vanilla --slave "c:my projectsmy_script.R"
source("myfile")
sink("record.lis") # la salida va al archivo record.lis
18 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-18-320.jpg)


![Vectores
vector <- c(1,2,3,4,5)
vector[0]
vector[1]
cadena <- "uno"
cadena
lcadena <- c("casa","manzana","uva")
lcadena
vlogico <- c(TRUE,FALSE,TRUE,TRUE,FALSE)
vlogico
21 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-21-320.jpg)





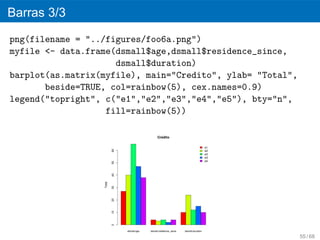
![Muestra aleatoria
set.seed(32)
dsmall <- credit[sample(nrow(credit), 10), ]
dsmall
27 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-27-320.jpg)







![´
Conceptos basicos
´
Poblacion
´
Es el conjunto completo de elementos de nuestro interes.
´
Las caracter´sticas de una poblacion son las medidas
ı
estad´sticas de cada uno de sus elementos.
ı
Muestra
´ ´
Es una proporcion de la poblacion. Una muestra posee
´
las mismas caracter´sticas de la poblacion si se obtiene
ı
aleatoriamente.
[Bartlein, 2009, Trochim, 2006, Quick, 2009, Wackerly et al., 2002]
32 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-35-320.jpg)








![Moda
Mode <- function (x) {
cngtable <- table(x)
n <- length(cngtable)
mode <- as.double(names(sort(cngtable)[n]))
mode
}
moda <- Mode(age)
moda
39 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-45-320.jpg)





![Cargando datos
setwd("path")
credit <- read.csv(file = "../data/credit-g.csv", sep = ",",
na.strings = "NULL")
attach(credit)
set.seed(32) # Muestra
dsmall <- credit[sample(nrow(credit), 5), ]
dsmall
46 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-52-320.jpg)


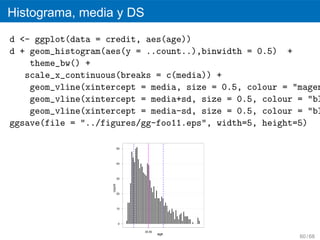
![Cuts
agebin = cut(age,breaks = c(18,30,40,50,60,70,80))
agebinfile <- data.frame(purpose,credit_amount,personal_
status,housing,job,age=agebin,class)
agebinfile
d <- ggplot(data = agebinfile, aes(age))
d + stat_bin(aes(ymax = ..count..), geom = "bar") + theme_bw()
ggsave(file = "../figures/gg-foo12.eps", width=5, height=5)
400
300
count
200
100
0
(18,30] (30,40] (40,50]
age
(50,60] (60,70] (70,80] 61 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-67-320.jpg)
![Cuts - theme bw()
agebin = cut(age,breaks = c(18,30,40,50,60,70,80))
agebinfile <- data.frame(purpose,credit_amount,personal_
status,housing,job,age=agebin,class)
agebinfile
d <- ggplot(data = agebinfile, aes(age))
d + stat_bin(aes(ymax = ..count..), geom = "bar") + theme_bw()
ggsave(file = "../figures/gg-foo12.eps", width=5, height=5)
400
300
count
200
100
0
(18,30] (30,40] (40,50]
age
(50,60] (60,70] (70,80] 62 / 68](https://image.slidesharecdn.com/rslides-111112200337-phpapp01/85/R-Taller-de-Introduccion-68-320.jpg)






















![El telefono[2]](https://cdn.slidesharecdn.com/ss_thumbnails/eltelefono2-130214204210-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)