Descargado 27 veces




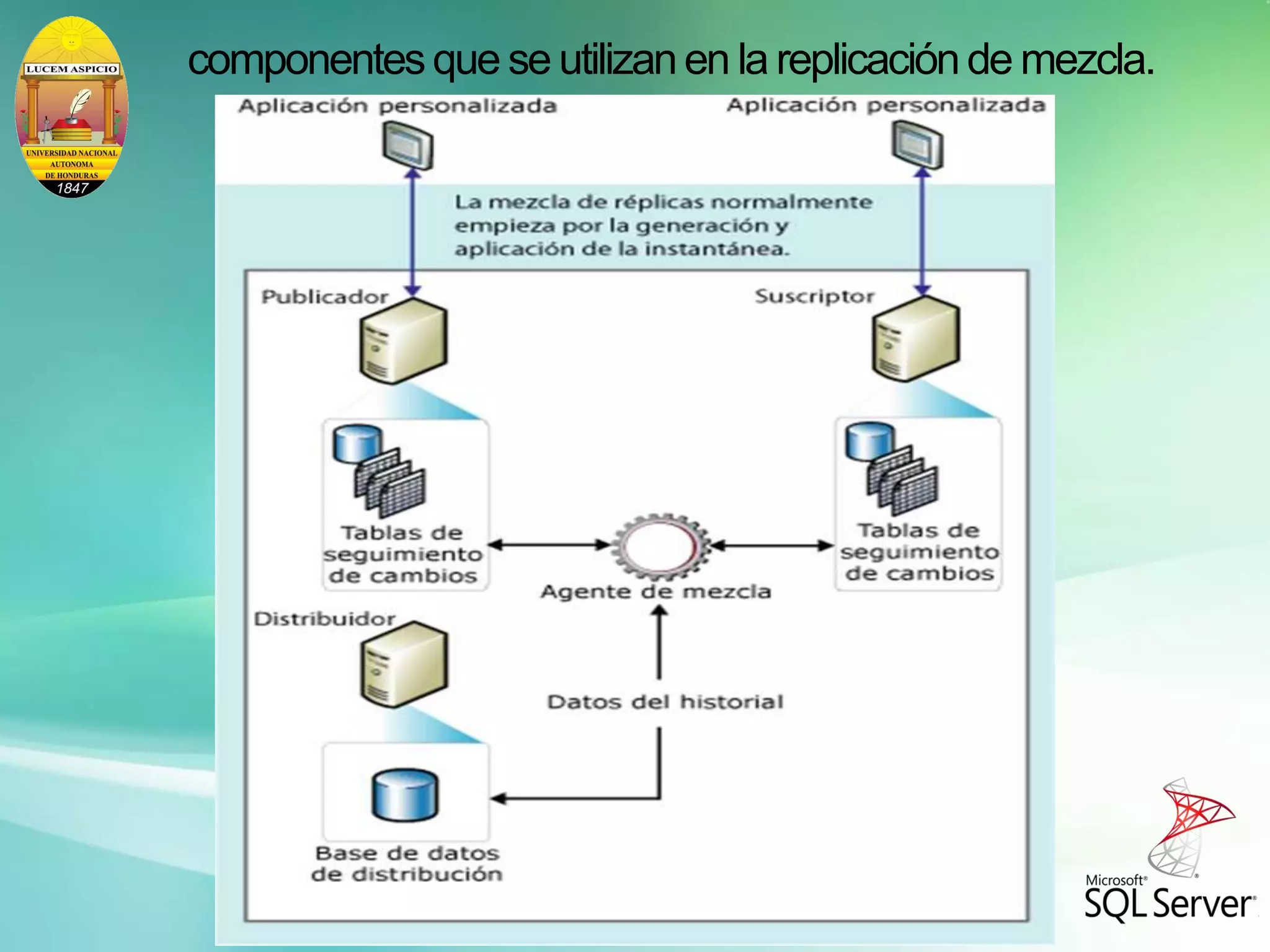






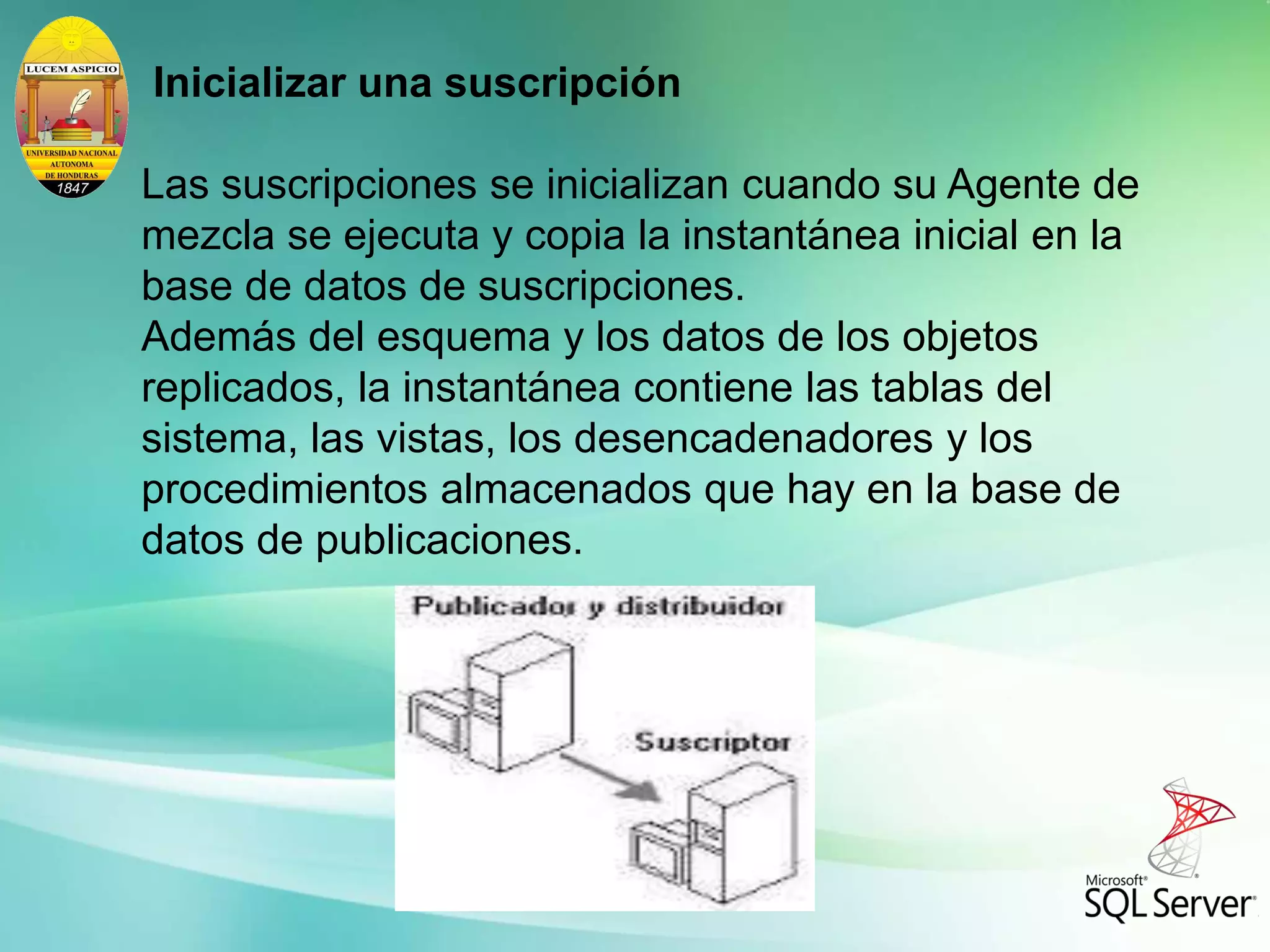








La replicación de mezcla permite que múltiples suscriptores actualicen los mismos datos de forma independiente y luego sincronicen los cambios. Los cambios se rastrean mediante desencadenadores y tablas del sistema, y los conflictos se detectan y resuelven según reglas configuradas. La replicación de mezcla es adecuada cuando los suscriptores necesitan trabajar sin conexión y sincronizar más tarde los cambios con otros nodos.





































