Descargar para leer sin conexión


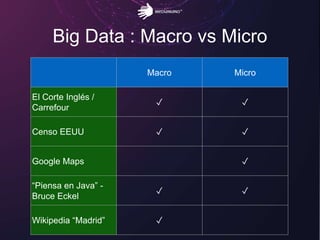
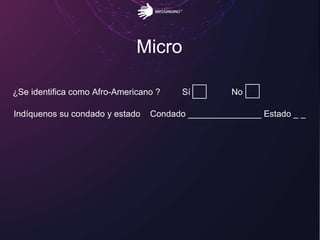
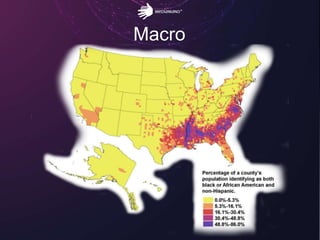





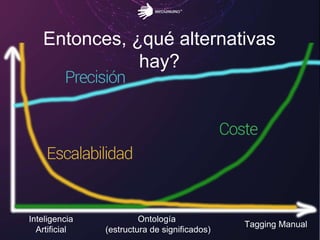

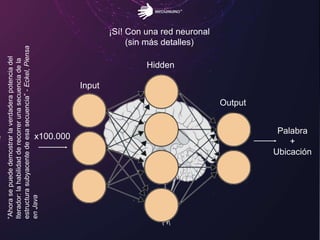
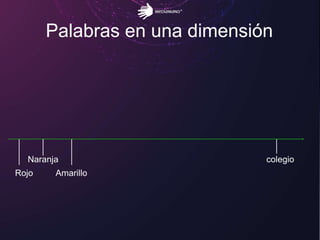




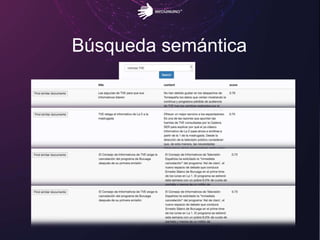
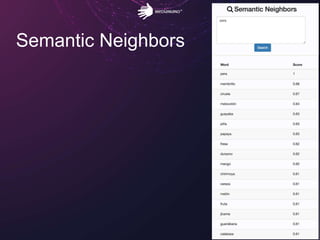

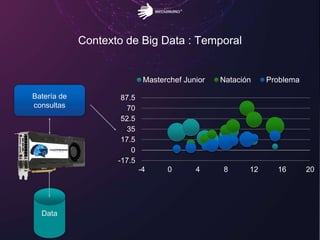
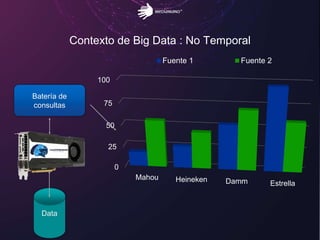



El documento aborda los retos del big data en el análisis de fuentes de datos textuales, diferenciando entre enfoques macro y micro. Se discuten métodos como la lógica de Boole, el tagging manual, y la inteligencia artificial para mejorar el análisis. Además, se concluye que es posible realizar big data con texto, permitiendo la medición y descubrimiento de información oculta.
















































