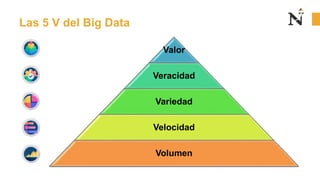
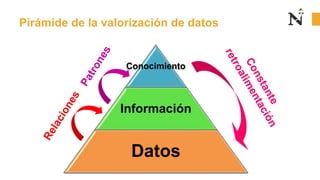
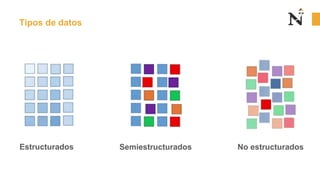
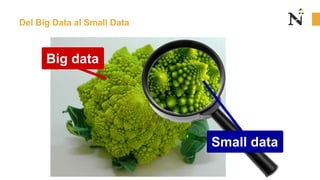
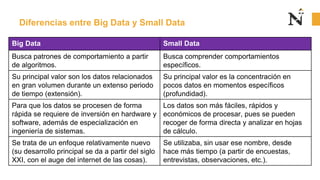
Este documento presenta una sesión introductoria sobre los fundamentos del Big Data. Explica que el Big Data implica grandes cantidades de datos de diversas fuentes que superan la capacidad del software convencional. Define las 5 V del Big Data: volumen, velocidad, variedad, veracidad y valor. Describe cada una de estas dimensiones y los tipos de datos estructurados, semiestructurados y no estructurados. Finalmente, contrasta el enfoque del Big Data con el Small Data, enfocado en detalles específicos.