Descargar como PDF, PPTX

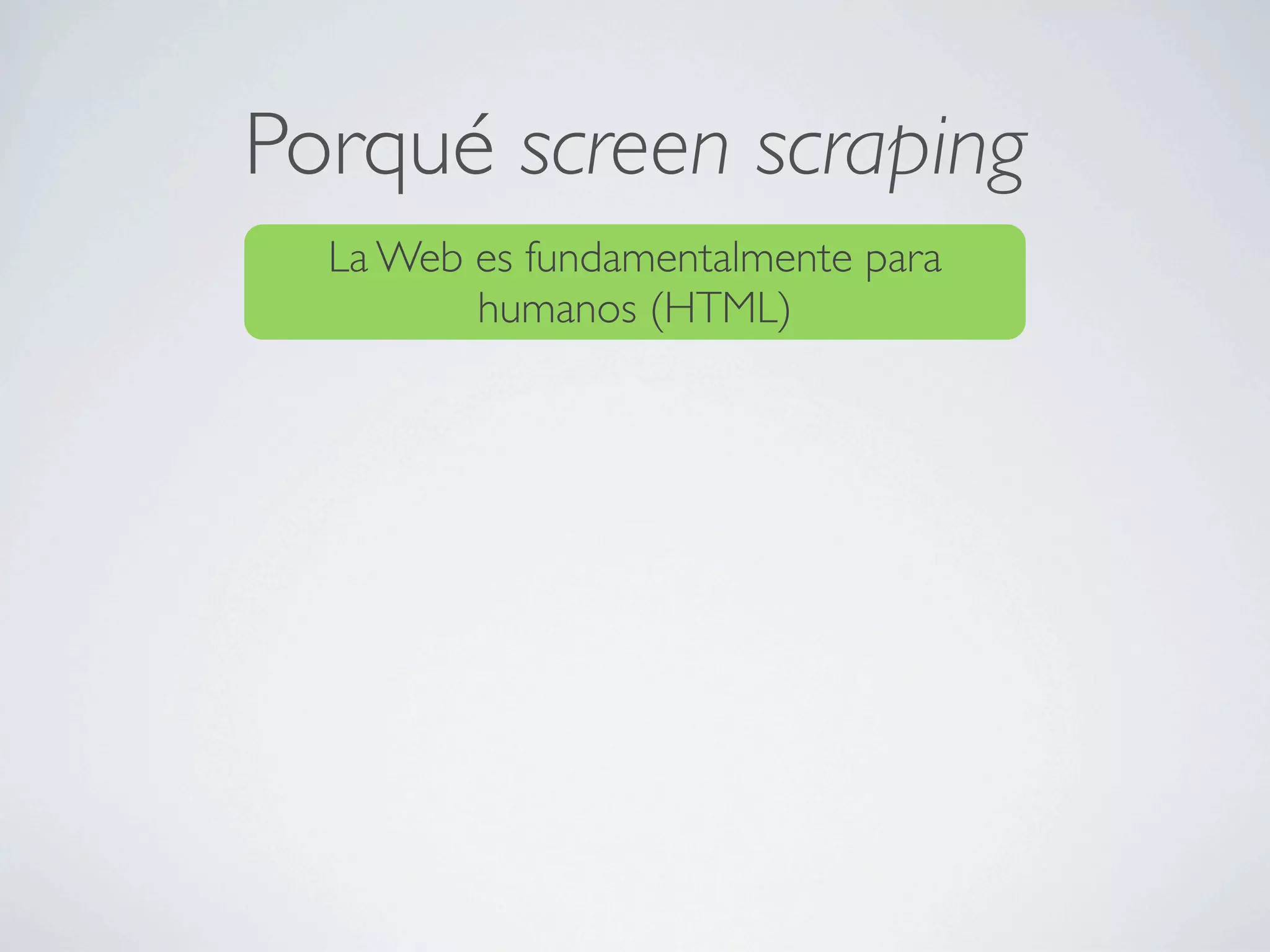

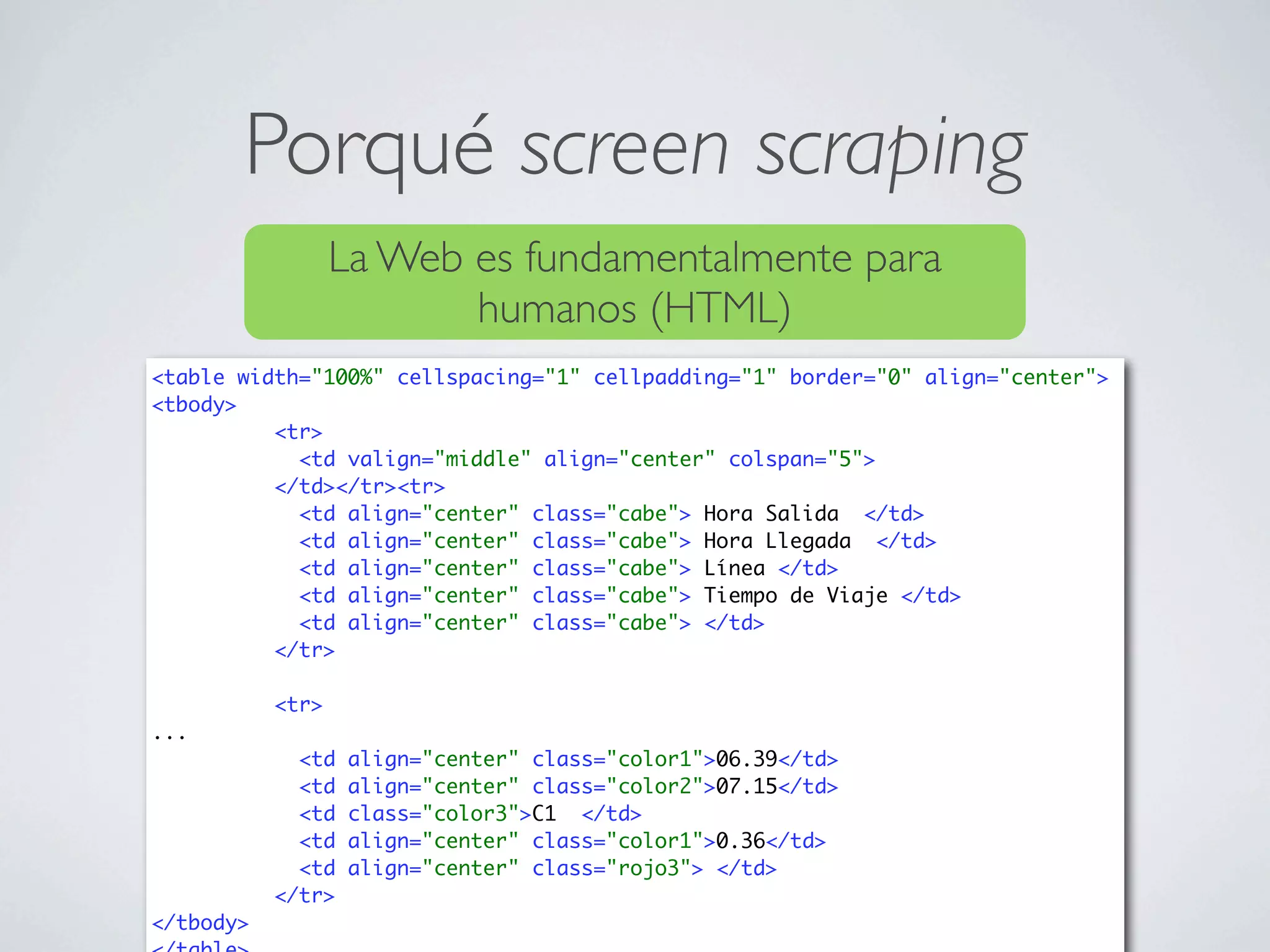
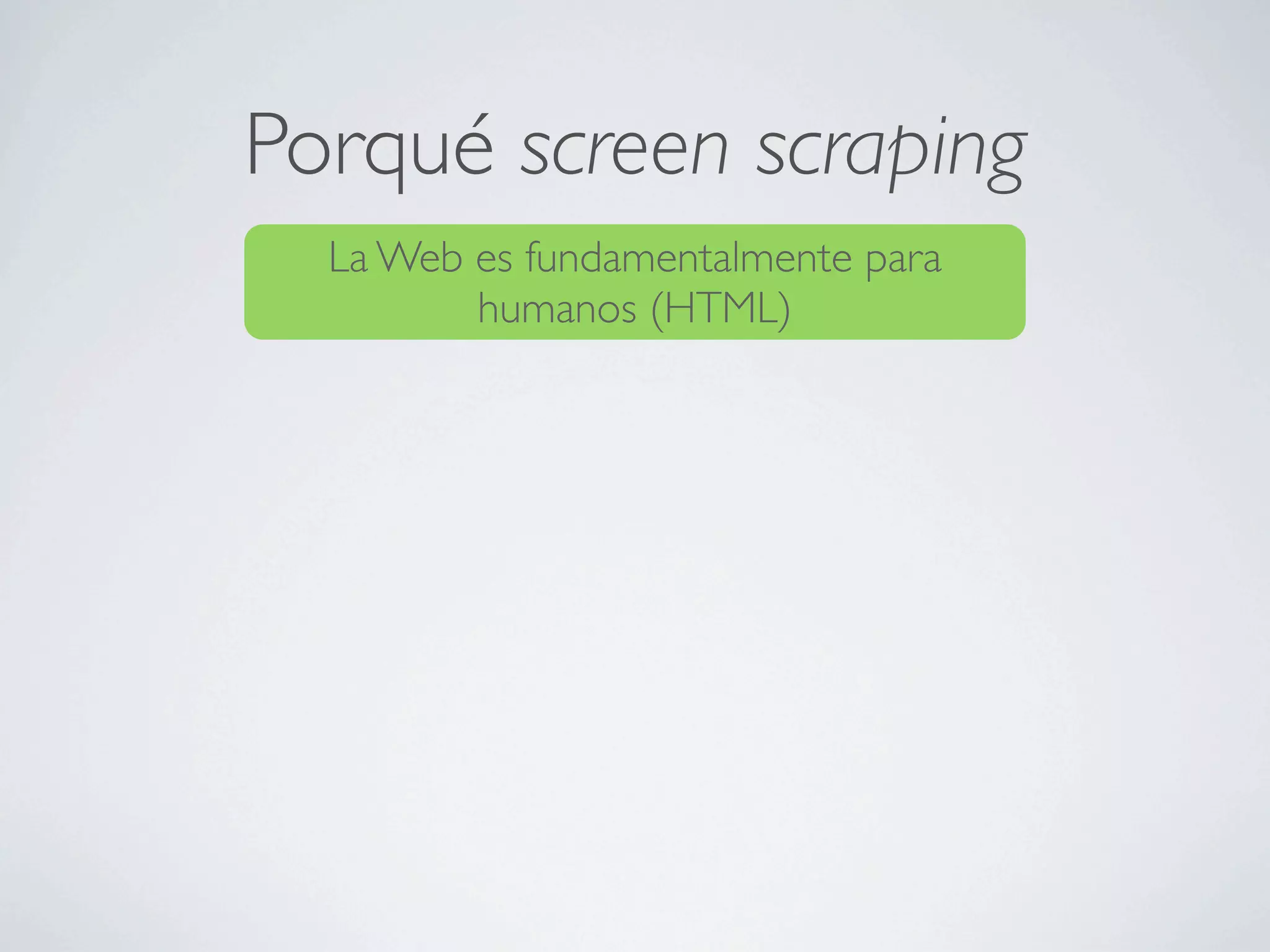




![Java
import javax.swing.text.html.*;
import javax.swing.text.Element;
import javax.swing.text.ElementIterator;
import java.net.URL;
import java.io.InputStreamReader;
import java.io.Reader;
public class HTMLParser
{
public static void main( String[] argv ) throws Exception
{
URL url = new URL( "http://java.sun.com" );
HTMLEditorKit kit = new HTMLEditorKit();
HTMLDocument doc = (HTMLDocument) kit.createDefaultDocument();
doc.putProperty("IgnoreCharsetDirective", Boolean.TRUE);
Reader HTMLReader = new InputStreamReader(url.openConnection().getInputStream());
kit.read(HTMLReader, doc, 0);
ElementIterator it = new ElementIterator(doc);
Element elem;
while( elem = it.next() != null )
{
if( elem.getName().equals( "img") )
{
String s = (String) elem.getAttributes().getAttribute(HTML.Attribute.SRC);
if( s != null )
System.out.println (s );
}
}
System.exit(0);
}
}](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-17-2048.jpg)



![HTree+REXML
require 'rubygems'
require 'open-uri'
require 'htree'
require 'rexml/document'
open("http://www.google.es/search?q=ruby",:proxy=>"http://localhost:8080") do |page|
page_content = page.read()
doc = HTree(page_content).to_rexml
doc.root.each_element('//a[@class=l]') {|elem| puts elem.attribute('href').value }
end
Runtime: 7.06s.](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-21-2048.jpg)

![HPricot
require 'rubygems'
require 'hpricot'
require 'open-uri'
doc = Hpricot(open('http://www.google.com/search?q=ruby',:proxy=>'http://localhost:8080'))
links = doc/"//a[@class=l]"
links.map.each {|link| puts link.attributes['href']}
Runtime: 3.71s](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-23-2048.jpg)



![Rubyful Soup
require 'rubygems'
require 'rubyful_soup'
require 'open-uri'
open("http://www.google.com/search?q=ruby",:proxy=>"http://localhost:8080") do |page|
page_content = page.read()
soup = BeautifulSoup.new(page_content)
result = soup.find_all('a', :attrs => {'class' => 'l'})
result.each { |tag| puts tag['href'] }
end
Runtime: 4.71s](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-27-2048.jpg)





![WWW::Mechanize
require 'rubygems'
require 'mechanize'
agent = Mechanize.new
agent.set_proxy("localhost",8080)
page = agent.get('http://www.google.com')
search_form = page.forms.select{|f| f.name=="f"}.first
search_form.fields.select {|f| f.name=='q'}.first.value="ruby"
search_results = agent.submit(search_form)
search_results.links.each { |link| puts link.href if link.attributes["class"] == "l" }
Runtime: 5.23s](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-33-2048.jpg)




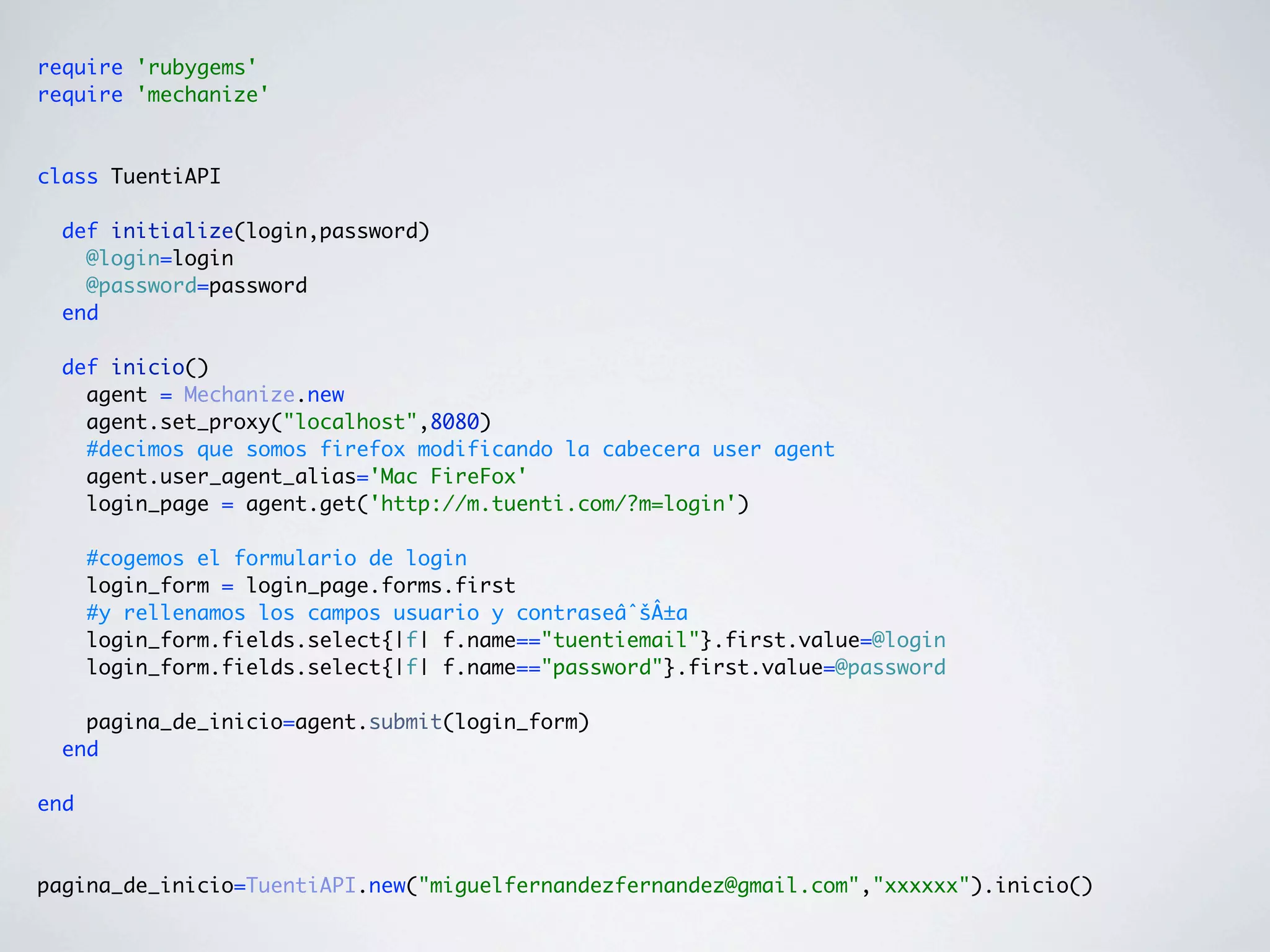

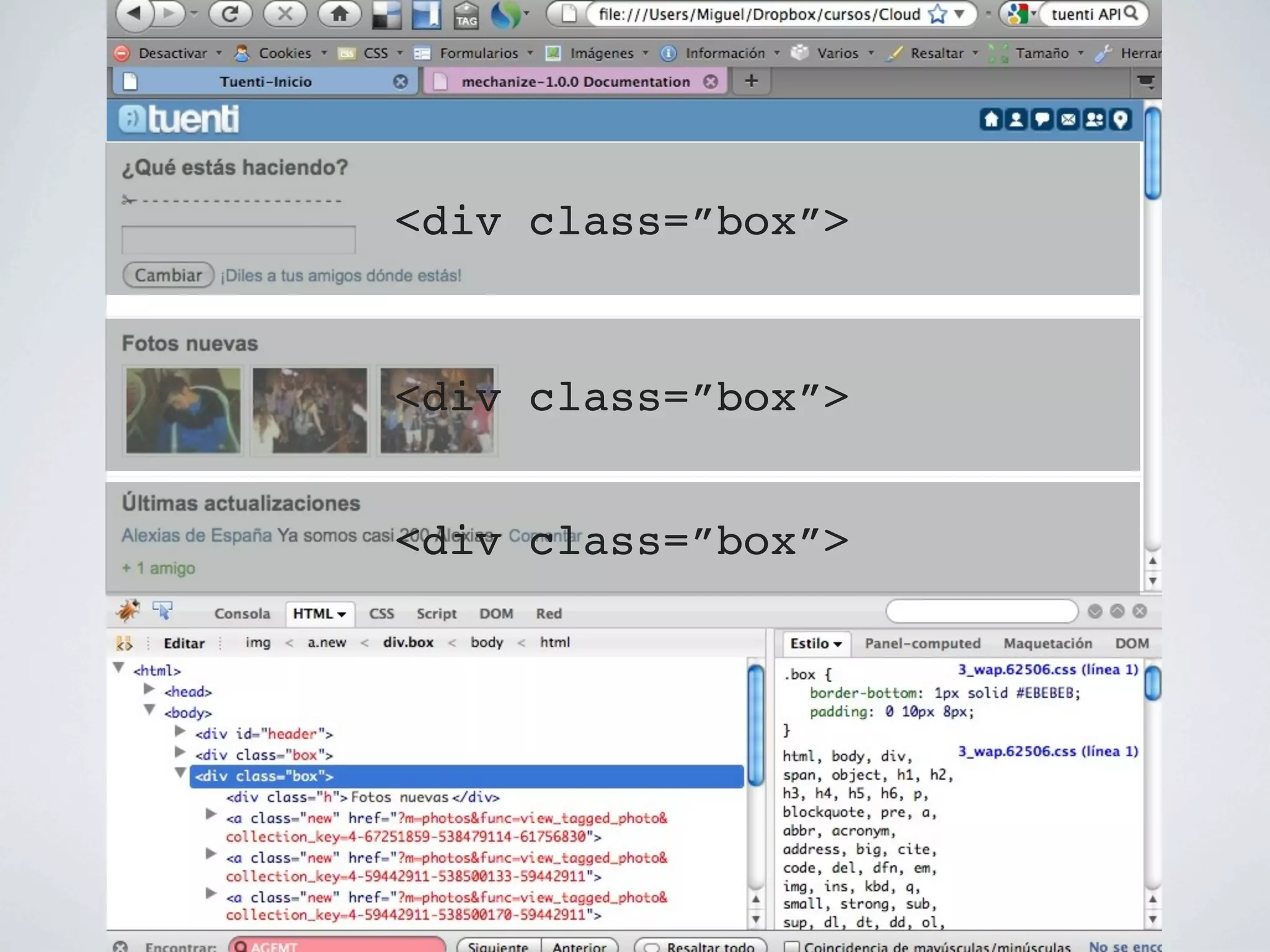
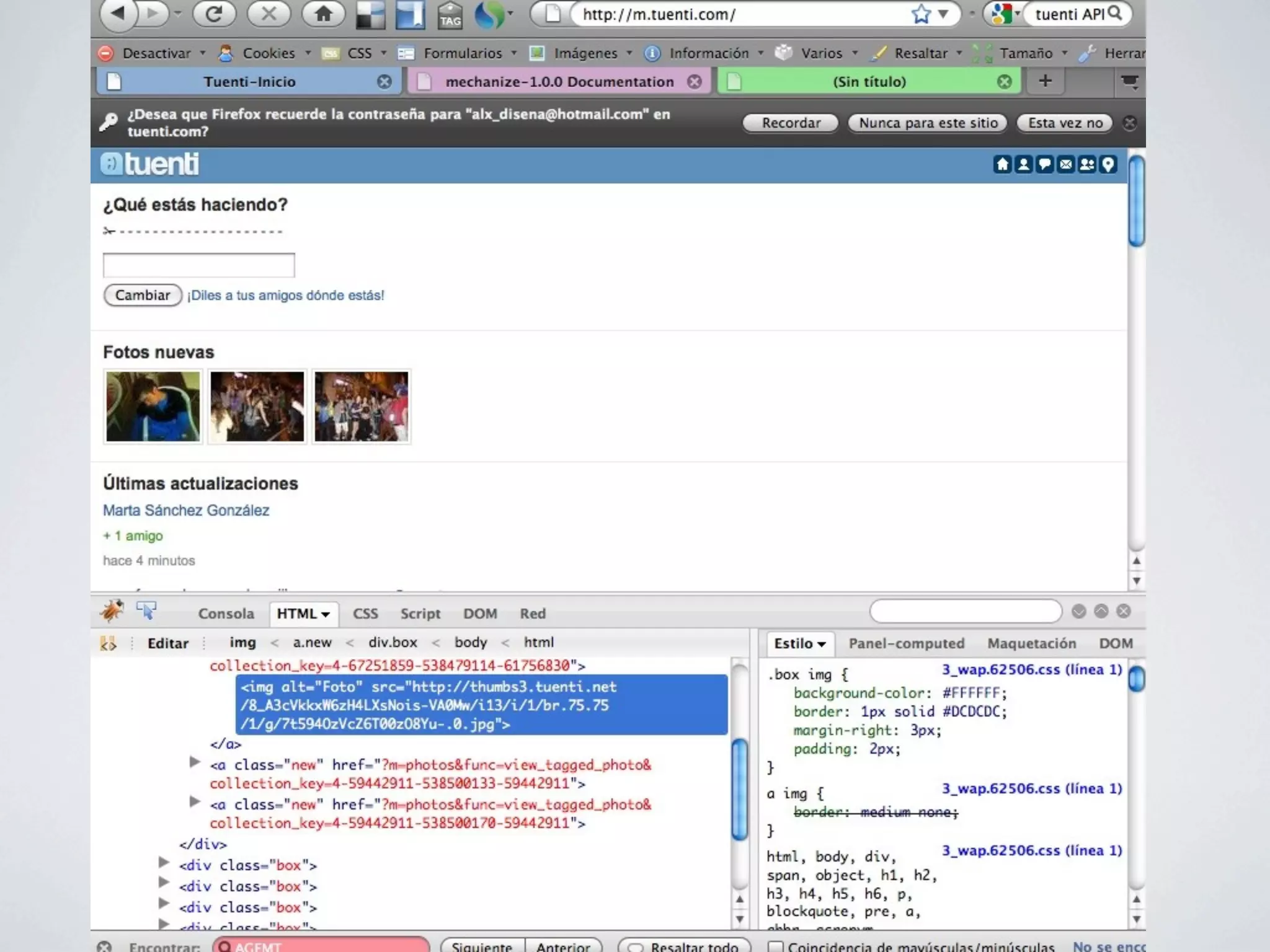
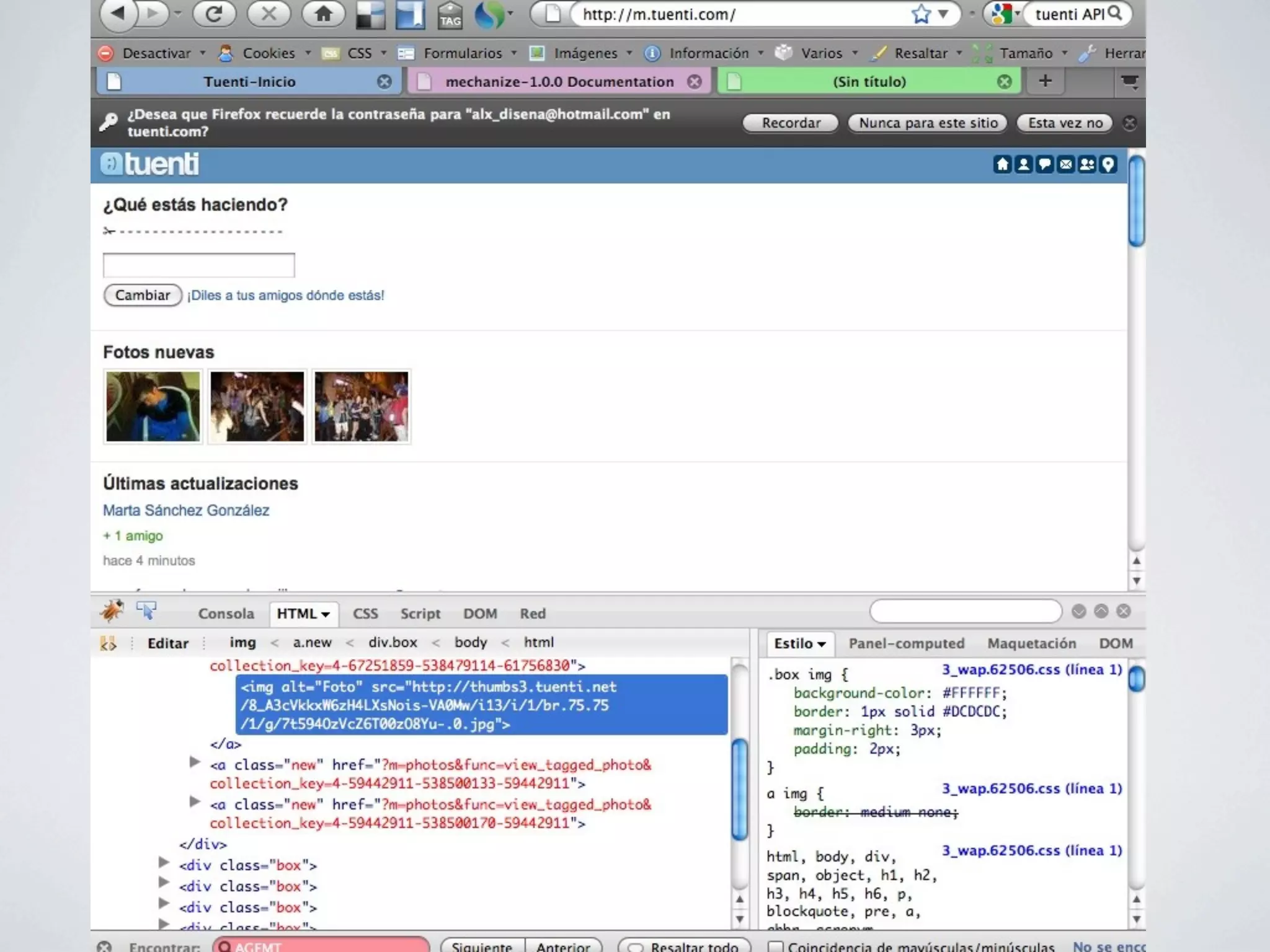
![Paso 2: Obtener las fotos
class TuentiAPI
...
def fotos_nuevas()
tree=Hpricot(inicio().content)
fotos = tree / "//a//img[@alt=Foto]"
fotos.map!{|foto| foto.attributes["src"]}
Set.new(fotos).to_a
end
private
def inicio()
...
end
end](https://image.slidesharecdn.com/screenscraping-110202115525-phpapp02/75/Screen-scraping-45-2048.jpg)


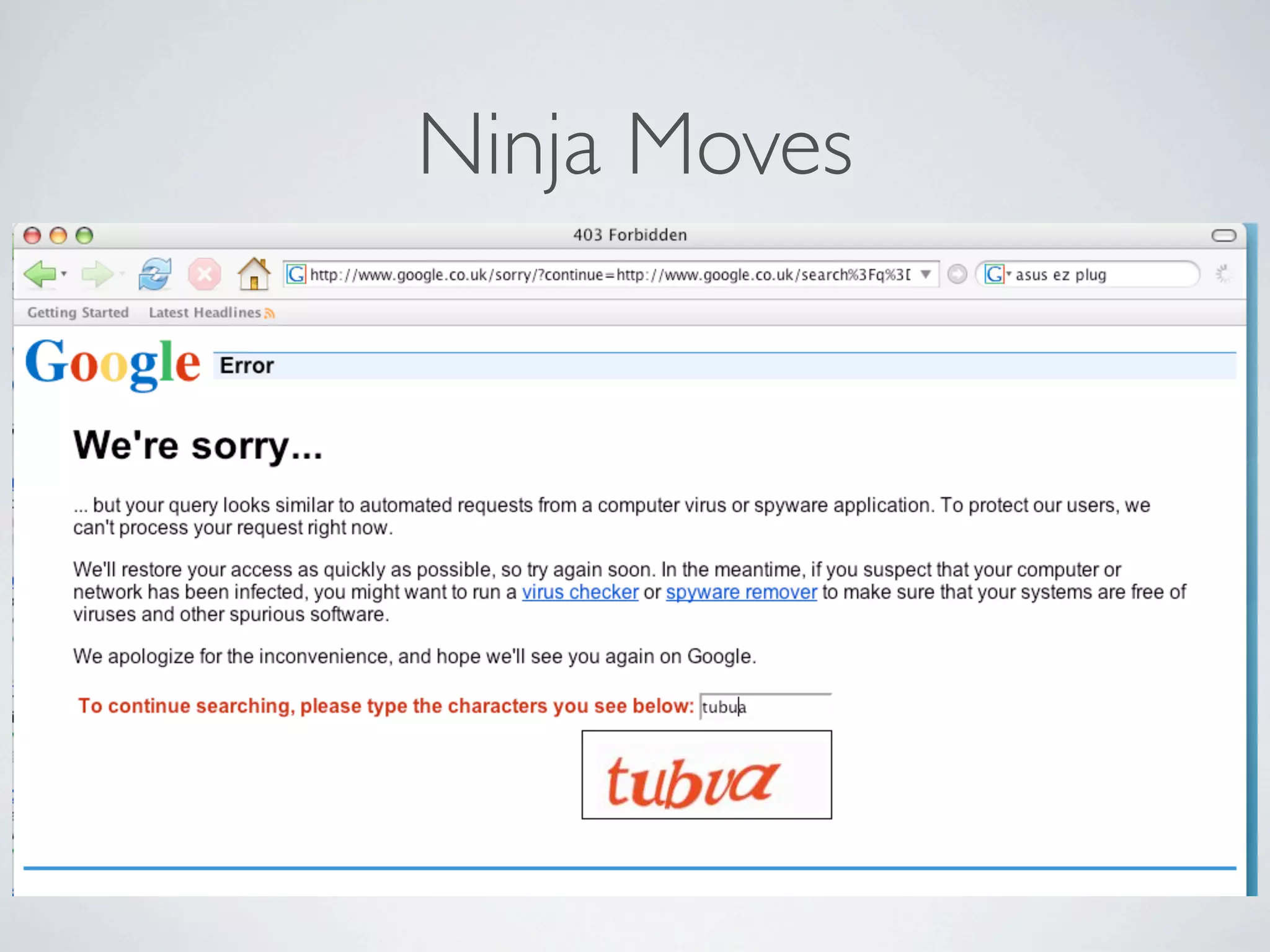




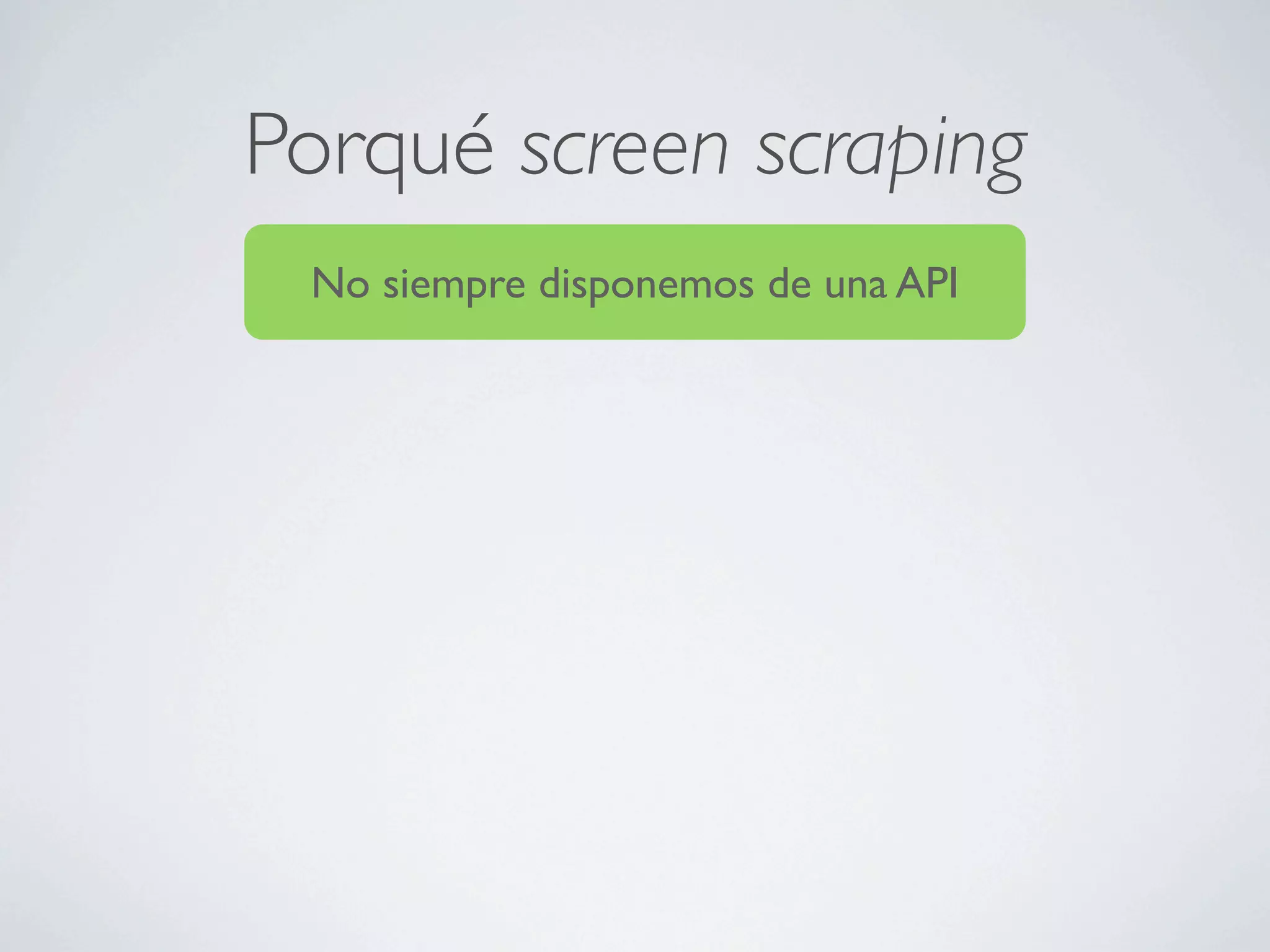
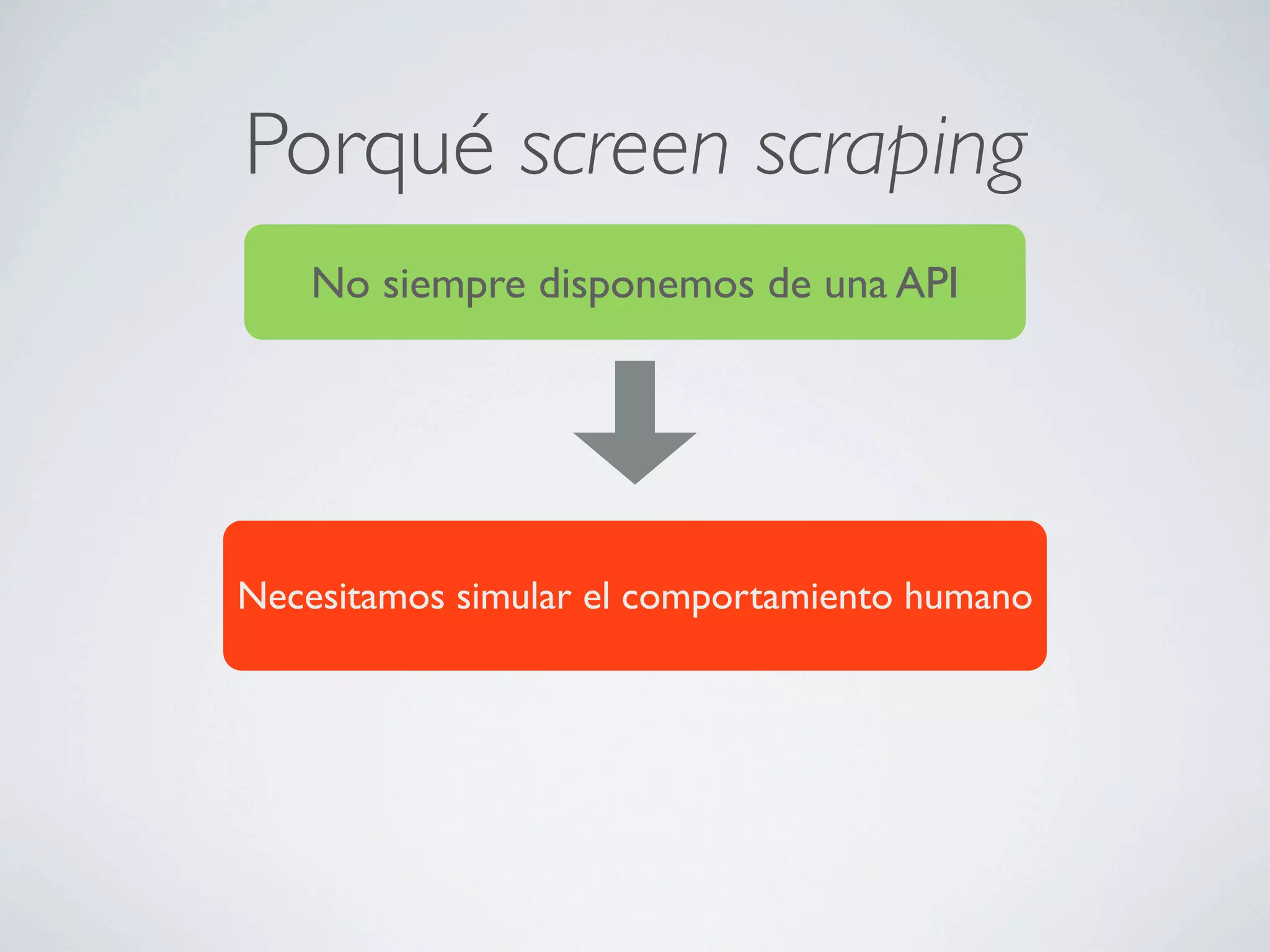
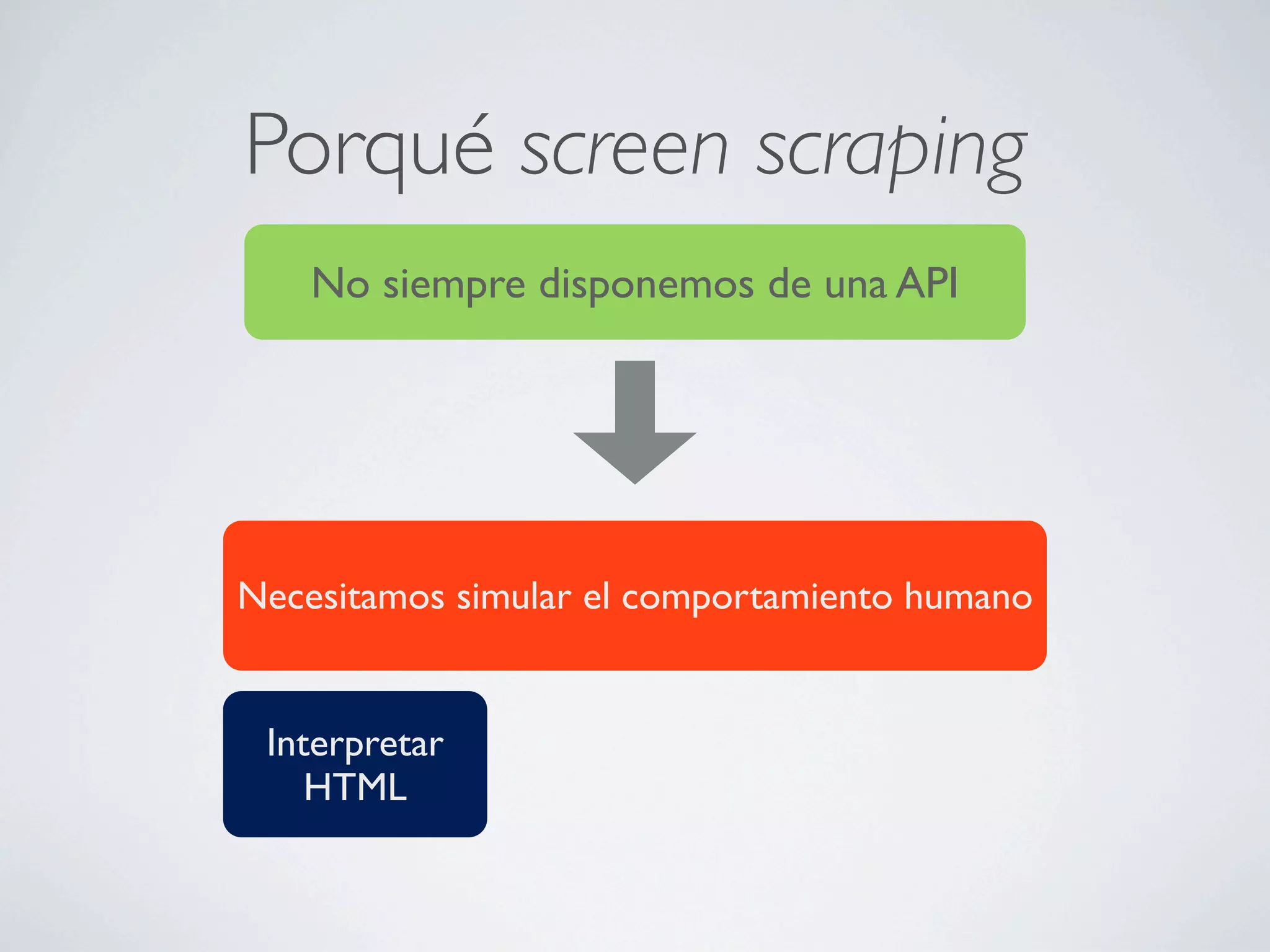
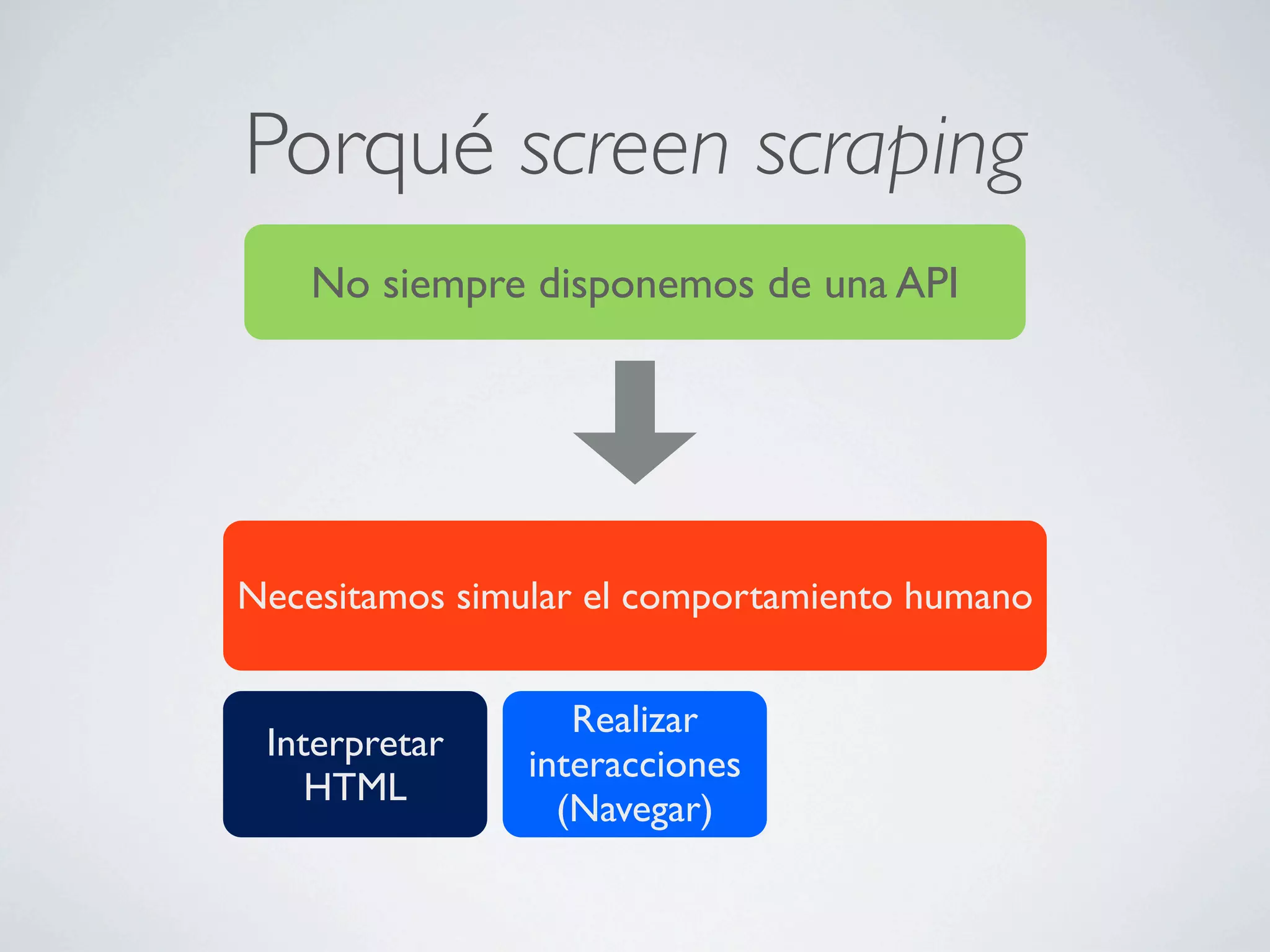
Este documento describe cómo extraer datos de páginas web mediante screen scraping utilizando diferentes lenguajes de programación como Ruby y Java. Explica las herramientas disponibles como HTree, REXML, Hpricot y Mechnize y cómo usarlas para simular el comportamiento humano al navegar por páginas y extraer datos de forma automatizada. También cubre técnicas como el uso de proxies y Tor para realizar peticiones de forma anónima.


































