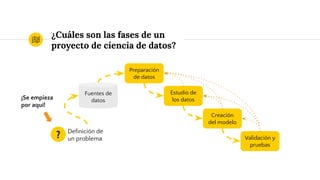
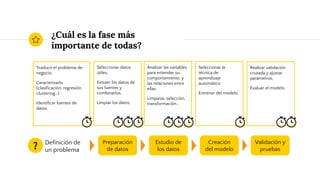
Este documento presenta una charla sobre las lecciones aprendidas en proyectos de ciencia de datos. Explica brevemente conceptos clave como aprendizaje automático, fases típicas de un proyecto y desafíos comunes como definir claramente el problema, limpiar y entender los datos, seleccionar adecuadamente los algoritmos y métricas de evaluación, y utilizar correctamente conjuntos de entrenamiento, validación y prueba. También menciona cómo el contexto de Big Data introduce nuevos retos tecnológicos.