Descargar como PDF, PPTX

















![SPLIT_PERC = 0.6
train_size = int(len(data_samples.data)*SPLIT_PERC)
data_train = data_samples.data[:train_size]
data_test = data_samples.data[train_size:]
y_train = data_samples.target[:train_size]
y_test = data_samples.target[train_size:]](https://image.slidesharecdn.com/aprendizajeautomaticopython-130826110306-phpapp02/85/Aprendizaje-Automatico-con-Python-19-320.jpg)






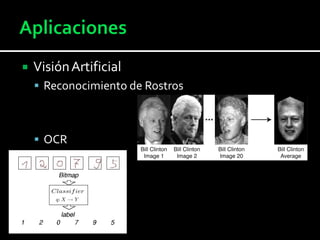
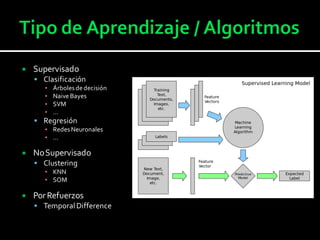
Este documento presenta una introducción al aprendizaje automático (AA). Explica que el AA permite resolver tareas complejas mediante el aprendizaje a partir de la experiencia. Luego describe algunas aplicaciones como procesamiento de lenguaje natural, detección de spam, visión artificial y sistemas de recomendación. Finalmente, presenta herramientas de AA en Python y los pasos para implementar un filtro de spam utilizando Scikit-learn.



























