Descargado 39 veces




![• Seguridad
• Heterogeneidad
• Errores.
• Etc.
URIs (Universal Resource Identifier. RFC 2396)
– Dirección de los recursos disponibles en la Web. Normalmente se componen de tres
partes:
• El esquema de nombres del mecanismo usado para acceder al recurso.
• El nombre de la máquina que aloja al recurso.
• El nombre del recurso en forma de ruta de acceso (path).
<esquema>://<máquina>[:puerto]/<ruta>
<esquema>://<máquina>[:puerto]/<ruta>;<param>?<query>#<fragmento>
– Esquemas
• ftp File Transfer protocol
• http Hypertext Transfer Protocol
• mailto Electronic mail address
• newsUSENET news
• nntp USENET news mediante NNTP
• file Nombre de archivo
URIs relativos
Página - 3 -](https://image.slidesharecdn.com/12protocolohttp-130822122736-phpapp02/85/Protocolo-http-y-WWW-4-320.jpg)














![Peticiones en HTTP: GET y POST
Las peticiones en HTTP pueden realizarse usando dos métodos.
- El método GET, que se utiliza para recoger cualquier tipo de información del servidor (realizar
peticiones) en caso de enviar parámetros junto a la petición, las enviaría codificadas en la
URL. Se utiliza siempre que se pulsa sobre un enlace o se teclea directamente una URL.
Como resultado, el servidor HTTP envía el documento correspondiente a la URL
seleccionada, o bien activa un módulo CGI, que generará a su vez la información de retorno.
- Por su parte, el método POST, en caso de enviarlos, lo haría como parte del cuerpo de la
petición. (p.e., los datos contenidos en un formulario). El servidor pasará esta información a
un proceso encargado de su tratamiento (generalmente una aplicación CGI). La operación
que se realiza con la información proporcionada depende de la URL utilizada.
Una petición GET sigue el siguiente formato:
GET /index.html HTTP/1.1
Host: www.ejemplo.com
User-Agent: Mozilla/4.5 [en]
Accept: image/gif, image/jpeg, text/html
Accept-language: en
Accept-Charset: iso-8859-1
Página - 19 -](https://image.slidesharecdn.com/12protocolohttp-130822122736-phpapp02/85/Protocolo-http-y-WWW-20-320.jpg)


![antes de &, + y ?, así como los caracteres no imprimibles, etc.) se representan con %xx, donde xx
representa al código ASCII en hexadecimal del carácter.
Por ejemplo:
http://www.ejemplo.com/indice.jsp?nombre=Perico+Palotes&OK=1
que en la petición HTTP quedaría:
GET /indice.jsp?nombre=Perico+Palotes&OK=1 HTTP/1.0
Host: www.ejemplo.com
User-Agent: Mozilla/4.5 [en]
Accept: image/gif, image/jpeg, text/html
Accept-language: en
Accept-Charset: iso-8859-1
Para pasar los parámetros como datos extra de la petición, éstos se envían al servidor como cuerpo
de mensaje en la petición.
Por ejemplo, la petición anterior quedaría:
POST /indice.jsp HTTP/1.0
Host: www.ejemplo.com
User-Agent: Mozilla/4.5 [en]
Accept: image/gif, image/jpeg, text/html
Accept-language: en
Accept-Charset: iso-8859-1
Página - 22 -](https://image.slidesharecdn.com/12protocolohttp-130822122736-phpapp02/85/Protocolo-http-y-WWW-23-320.jpg)

![La petición anterior en formato multiparte sería:
POST /indice.jsp HTTP/1.0
Host: www.ejemplo.com
User-Agent: Mozilla/4.5 [en]
Accept: image/gif, image/jpeg, text/html
Accept-language: en
Accept-Charset: iso-8859-1
Content-Type: multipart/form-data,
delimiter=“----ALEATORIO----”
----ALEATORIO----
Content-Disposition: form-data; name=“nombre”
Perico Palotes
----ALEATORIO----
Content-Disposition: form-data; name=“OK”
1
----ALEATORIO------
Esta codificación es exclusiva del método POST. Se emplea para enviar ficheros al servidor.
Respuestas en HTTP
Página - 24 -](https://image.slidesharecdn.com/12protocolohttp-130822122736-phpapp02/85/Protocolo-http-y-WWW-25-320.jpg)













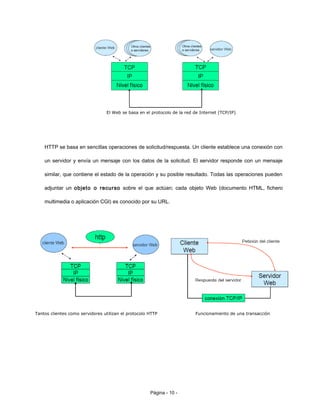
1) El protocolo HTTP es el protocolo base de la World Wide Web y permite la transferencia de hipertextos entre clientes web y servidores HTTP de forma sencilla. 2) HTTP es un protocolo simple, sin estado, orientado a conexión que utiliza TCP para establecer canales de comunicación entre clientes y servidores. 3) El protocolo HTTPS es una variante de HTTP que utiliza SSL para cifrar la comunicación entre clientes y servidores, usándose comúnmente en sitios de comercio electrónico y que contienen información personal.



































































