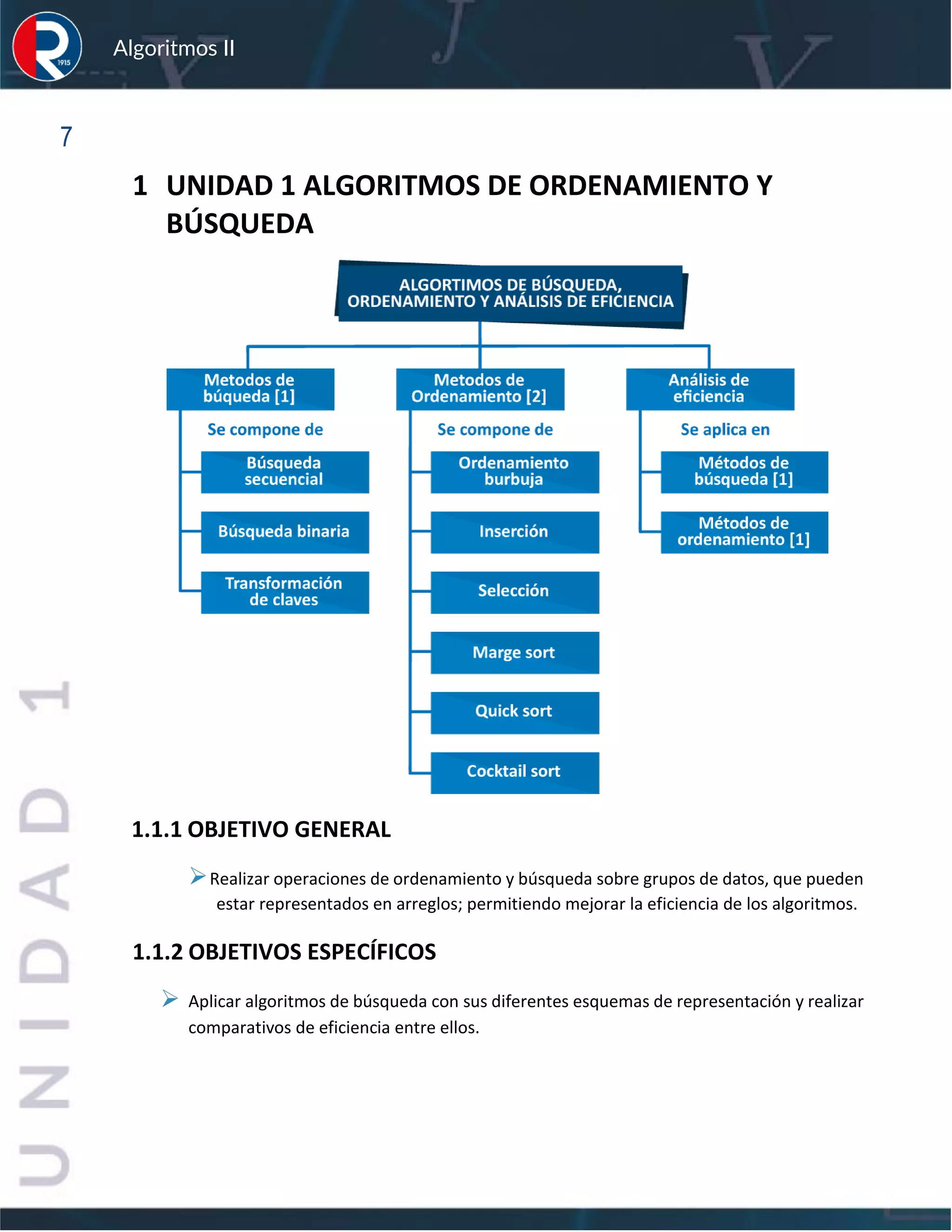
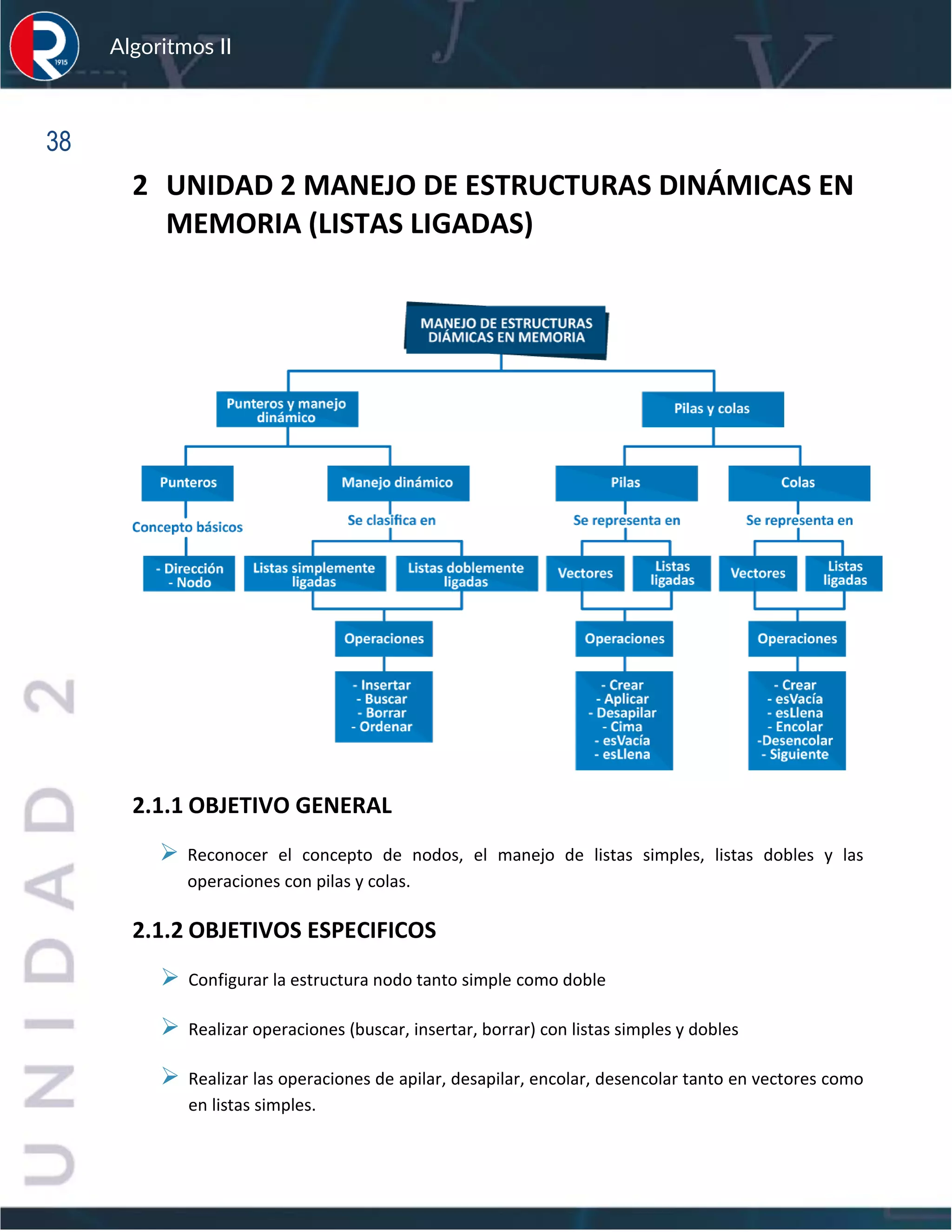
Este documento presenta los conceptos y algoritmos fundamentales de ordenamiento y búsqueda. En la Unidad 1, se explican algoritmos de búsqueda secuencial, binaria y por transformación de claves. También se describen métodos de ordenamiento como burbuja, inserción y selección, así como análisis de eficiencia. La Unidad 2 trata sobre estructuras dinámicas como listas ligadas, pilas y colas. Finalmente, la Unidad 3 cubre recursividad, árboles y grafos.







![sfs
Algoritmos II
9
1. i = 1 1
2. While ((i <= n) and (V[j] <> x) do n + 1
3. i = i - 1 n
4. End (while) n
5. If (i <= n) then return i 1
6. Else write(“el dato” , x , “no existe”) 1
Contador de frecuencia = 3(n + 4)
Y el orden de magnitud es O(n)
Sea el siguiente vector de tamaño 10, que contiene los preciso de 10 artículos distintos (el vector
no se encuentra ordenado). Si el administrador necesita determinar si existe dentro del vector
un producto con un valor igual a 80.000 pesos como se podría ilustrar este proceso de búsqueda:
D=80000](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-9-2048.jpg)

![sfs
Algoritmos II
11
1. PUBLICO ESTATICO ENTERO BusquedaBinaria (V, n, d)
2. VARIABLES: li, ls, m (ENTEROS)
3. li = 1
4. ls = n
5. MQ (li <= ls)
6. m = (li + ls) / 2
7. SI (V[m] == d)
8. RETORNE (m)
9. SINO
10. SI (V[m] < d)
11. li = m + 1
12. SINO
13. ls = m – 1
14. FINSI
15. FINSI
16. FINMQ
17. RETORNE (n + 1)
18. FIN(Método)
En la instrucción 1 se define el método BúsquedaBinaria, cuyos parámetros son: V, en el cual hay
que efectuar la búsqueda; n, el tamaño del vector; y d, el dato a buscar.
En la instrucción 2 se definen las variables de trabajo: li, para guardar el límite inferior del rango
en el cual hay que efectuar la búsqueda; ls, para guardar el límite superior del rango en el que se
efectuará la búsqueda; y m, para guardar la posición de la mitad del rango entre li y ls.
En las instrucciones 3 y 4 se asignan los valores iníciales a las variables li y ls. Estos valores iníciales
son 1 y n, respectivamente, ya que la primera vez el rango sobre el cual hay que efectuar la
búsqueda es desde la primera posición hasta la última del vector.
En la instrucción 5 se plantea el ciclo MIENTRAS_QUE (MQ), con la condición de que li sea menor
o igual que ls. Es decir, si el límite inferior (li) es mayor o igual que el límite superior (ls), aún
existen posibilidades de que el dato que se está buscando se encuentre en el vector. Cuando li
sea mayor que ls significa que el dato no está en el vector y retornara n+1.
Cuando la condición de la instrucción 5 sea verdadera se ejecutan las instrucciones del ciclo.
En la instrucción 6 se calcula la posición de la mitad entre li y ls, llamamos a esta posición m.
En la instrucción 7 se compara el dato de la posición m con el dato d. si el dato de la posición m
es igual al dato d que se está buscando (V[m] == d), ejecuta la instrucción 8: termina el proceso
de búsqueda retornando m, la posición en la cual se halla el dato d en el vector.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-11-2048.jpg)

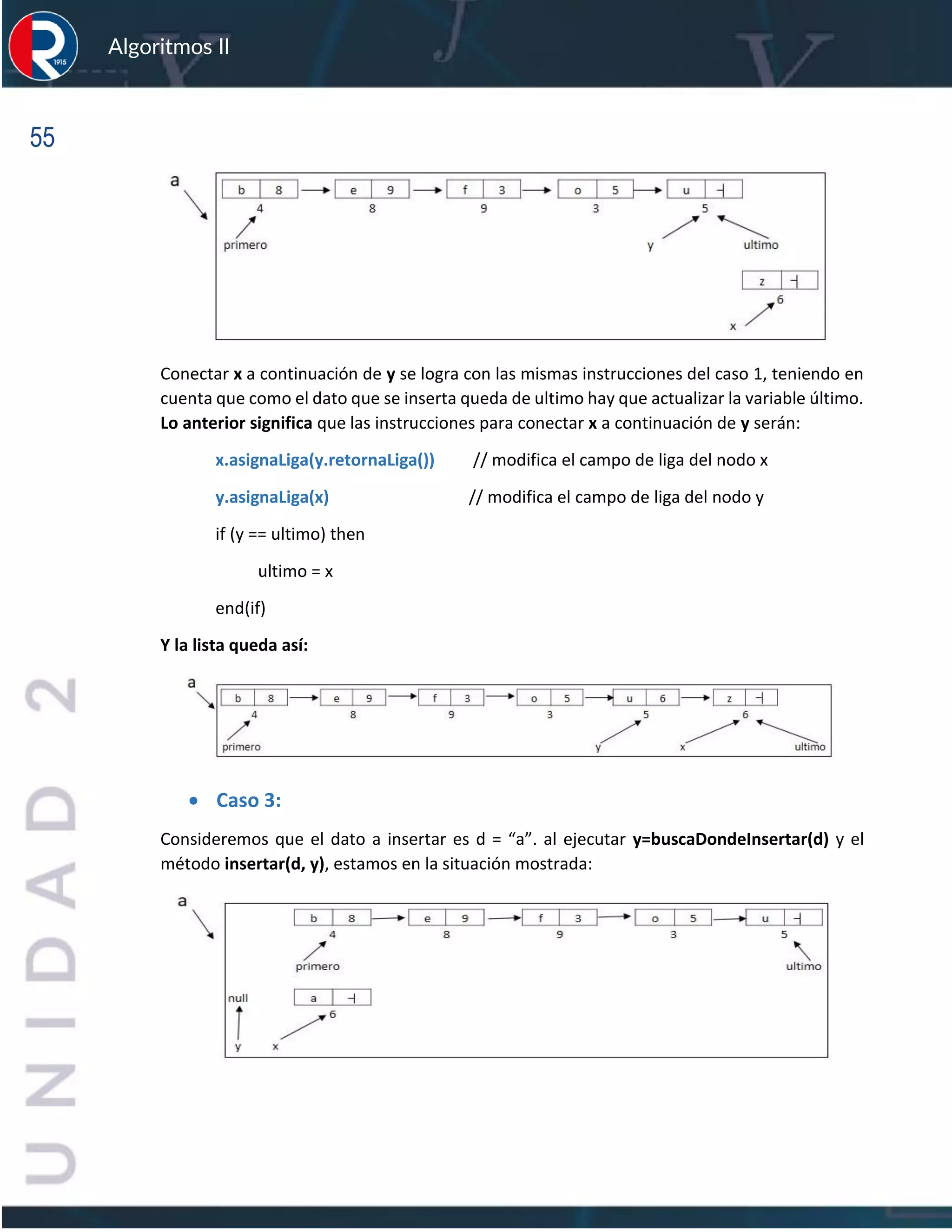
![sfs
Algoritmos II
13
cual hay que efectuar la búsqueda es 9, por lo tanto, el rango sobre el cual hay que efectuar dicha
búsqueda es entre 9 y 15.
Al ejecutar el ciclo por segunda vez el valor de m será 12, como muestra la figura siguiente:
Luego, al comparar d (38) con V[m] (52), se determina que el dato que se está buscando, si está
en el vector, debe hallarse a la izquierda de m, es decir, entre las posiciones 9 y 11, por
consiguiente, el valor de j será 11 (j = m – 1).
Al ejecutar el ciclo por tercera vez, las variables quedarán de la siguiente forma:
li m ls
n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V 3 6 7 10 12 18 22 28 31 37 45 52 60 69 73
En esta pasada se detecta que el dato debe estar a la derecha de m, por consiguiente el valor de
li deberá ser 11, y en consecuencia el valor de m también. La situación en el vector queda así:
En este punto la comparación de d con V[m] indica que si el dato d está en el vector, debe estar
a la izquierda de m, por tanto el valor de ls será 10, y al regresar a la instrucción 5 y evaluar la
condición del ciclo (li <= ls), esta será falsa, por consiguiente termina el ciclo y retorna como
posición el valor de 16 (n+1), indicando que el 38 no se encuentra en dicho vector.
li m ls
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V 3 6 7 10 12 18 22 28 31 37 45 52 60 69 73
li m Ls
n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V 3 6 7 10 12 18 22 28 31 37 45 52 60 69 73](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-13-2048.jpg)


![sfs
Algoritmos II
16
1.3 TEMA 2 ORDENAMIENTO POR BURBUJA, INSERCIÓN Y
SELECCIÓN (MARGE SORT, QUICK SORT, COCKTAIL SORT)
➢Video: ” ALGORITMOS - METODOS DE ORDENAMIENTO”
➢” Ver Video”: https://www.youtube.com/watch?v=VJ_EUuURRg4 ”
1.3.1 ORDENAMIENTO ASCENDENTE POR MÉTODO BURBUJA
El método de ordenamiento por burbuja consiste en comparar dos datos consecutivos y
ordenarlos ascendentemente, es decir, si el primer dato es mayor que el segundo se intercambia
dichos datos, de lo contrario se dejan tal cual están. Cualquiera de las dos situaciones que se
hubiera presentado se avanza en el vector para comparar los siguientes dos datos consecutivos.
En general, el proceso de comparaciones es: el primer dato con el segundo, el segundo dato con
el tercero, el tercer dato con el cuarto, el cuarto con el dato quinto, y así sucesivamente, hasta
comparar el penúltimo dato con el último. Como resultado de estas comparaciones, y los
intercambios que se hagan, el resultado es que en la última posición quedara el mayor dato en el
vector. La segunda vez se compara nuevamente los datos consecutivos, desde el primero con el
segundo, hasta que se comparan el antepenúltimo dato con el penúltimo, obteniendo como
resultado que el segundo dato mayor queda de penúltimo. Es decir, en cada pasada de
comparaciones, de los datos que faltan por ordenar, se ubica el mayor dato en la posición que le
corresponde, o sea de ultimo en el conjunto de datos que faltan por ordenar. Veamos el método
que efectúa dicha tarea
1. PUBLICO ESTATICO VOID OrdenamientoAscendenteBurbuja (V, n)
2. VARIABLES: i, j (ENTEROS
3. PARA (i= 1, n-1, 1)
4. PARA (j= 1, n-i, 1)
5. SI (V[j] > V[j+1])
6. INTERCAMBIAR (V, j, j+1)
7. FINSI
8. FINPARA
9. FINPARA
10. FIN(Método)
Como ejemplo vamos a considerar el siguiente vector:](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-16-2048.jpg)



![sfs
Algoritmos II
20
variable auxiliar. Al terminar el ciclo interno averiguamos cual es el contenido de dicha variable
auxiliar. Si es el mismo que se le asigno inicialmente, significa que no hubo intercambios en el
ciclo interno, por consiguiente, los datos del vector ya están ordenados y no hay necesidad de
hacer más comparaciones. Para nuestro ejemplo llamaremos a esa variable auxiliar sw.
Nuestro algoritmo queda:
1. PUBLICO ESTATICO VOID OrdenamientoAscendenteBurbujaSW (V, n)
2. VARIABLES: i, j, sw (ENTEROS)
3. PARA (i= 1, n-1, 1)
4. Sw = 0
5. PARA (j= 1, n-i, 1)
6. SI (V[j] > V[j+1])
7. INTERCAMBIAR (V, j, j+1)
8. sw = 1
9. FINSI
10. FINPARA
11. SI (sw == 0)
12. i = n
13. FINSI
14. FINPARA
15. FIN(Método)
El algoritmo anterior es similar al primero que hicimos de ordenamiento ascendente con el
método de burbuja, la diferencia está en que agregamos una variable llamada sw con la cual
sabremos si el vector está completamente ordenado sin haber hecho todos los recorridos.
Cuando la variable sw no cambie de valor significa que el vector ya está ordenado y asignaremos
a la variable i el valor de n para salir del ciclo externo.
1.3.2 PROCESO DE INSERCIÓN EN UN VECTOR ORDENADO
ASCENDENTEMENTE
Si queremos insertar un dato en un vector ordenado ascendentemente, sin dañar su
ordenamiento, primero debemos buscar la posición en la que debemos insertar. Para buscar la
posición donde vamos a insertar un nuevo dato en el vector ordenado ascendentemente
debemos recorrer el vector e ir comparando el dato de cada posición con el dato a insertar. Como
los datos están ordenados ascendentemente, cuando se encuentre en el vector un dato mayor
que el que se va a insertar esa es la posición en la cual deberá quedar el nuevo dato.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-20-2048.jpg)
![sfs
Algoritmos II
21
Si el dato a insertar es mayor que todos los datos del vector, entonces el dato a insertar quedara
de último.
El método siguiente ejecuta esta tarea y retorna en la variable i La posición en la cual debe
quedar el dato a insertar:
1. PUBLICO ESTATICO ENTERO BuscarDondeInsertar (V, m, d)
2. VARIABLES: i (ENTERO)
3. i = 1
4. MQ ((i <= m) ^ (V[i] < d))
5. i = i + 1
6. FINMQ
7. RETORNE (i)
8. FIN(Método)
En la instrucción 1 se define el nombre del programa con sus parámetros: V, variable que contiene
el nombre del vector en el cual hay que efectuar el proceso de búsqueda; m, variable que contiene
el número de posiciones utilizadas en el vector; y d, variable que contiene el dato a insertar.
En la instrucción 2 se define la variable i, que es la variable con la que recorre el vector y se va
comparando el dato de la posición i del vector (V[i]) con el dato a insertar (d).
En la instrucción 3 se inicializa la variable i en 1, ya que esta es la posición a partir de la cual se
comienza a almacenar la posición donde se va a insertar el dato.
En la instrucción 4, la instrucción del ciclo, se controlan dos situaciones: una, que no se haya
terminado de comparar los datos del vector, (i <= m), y dos, que el dato de la posición i sea mayor
que d (V[i] < d).
Si ambas condiciones son verdaderas se ejecutan las construcciones 5 y 6, es decir, se incrementa
la i en 1 y se regresa a la instrucción 4 a evaluar nuevamente las condiciones.
Cuando una de las condiciones sea falsa (i>m o V[i]>=d), se sale del ciclo y ejecuta la instrucción
7, es decir, retorna al programa llamante el valor de i: la posición en la cual hay que insertar el
dato d.
Como ejemplo, consideremos el vector de la siguiente figura, y que se desea insertar el número
10 (d==10).](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-21-2048.jpg)
![sfs
Algoritmos II
22
Al ejecutar el método
BuscarDondeInsertar, este retorna i valiendo 4, es decir, en la posición 4 del vector V debe quedar
el dato 10.
Ahora veamos Conocimos que el dato debe quedar en una posición i, veamos cómo se efectúa
este proceso. Si el vector no está lleno (m == n), debemos mover todos los datos desde la posición
i del vector hacia la derecha.
1. PUBLICO ESTATICO VOID Insertar (V, m, n, i, d)
2. VARIABLES: j (ENTERO)
3. SI (m == n)
4. IMPRIMA (“vector lleno”)
5. RETORNE
6. SINO
7. PARA (j= m, i, -1)
8. V[j+1] = V[j]
9. FINPARA
10. V[i] = d
11. m = m + 1
12. FINSI
13. FIN(Método)
Es la instrucción 1 se define el método con sus parámetros: V, variable que contiene el nombre
del vector en el cual hay que efectuar el proceso de inserción; m, variable que contiene el número
de posiciones utilizadas en el vector; n, tamaño del vector; i, variable que contiene la posición en
la cual se debe insertar el dato contenido en d; y d, variable que contiene el dato a insertar. Es
bueno resaltar que los parámetros V y m deben ser parámetros por referencia, mientras que n, i
y d son por valor.
En la instrucción 2 se define la variable j, la cual se utilizará para mover los datos del vector en
caso de que sea necesario.
m n
1 2 3 4 5 6 7 8 9 10
V 3 5 7 11 18 23 36](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-22-2048.jpg)

![sfs
Algoritmos II
24
Con base en este enunciado se presenta el método:
1. PUBLICO ESTATICO VOID OrdenamientoAscendenteSeleccion (V, m)
2. VARIABLES: i, j, k (ENTEROS)
3. PARA (i= 1, m-1, 1)
4. k = i
5. PARA (j= i+1, m, 1)
6. SI (V[j] < V[k])
7. k = j
8. FINSI
9. FINPARA
10. OrdenamientoAscendenteSeleccion .Intercambiar (V, k, i)
11. FINPARA
12. FIN(Método)
• En la instrucción 1 se define el método con sus parámetros: V, variable en la cual se
almacena el vector que desea ordenar, y m, el número de elementos a ordenar. V es un
parámetro por referencia, ya que se modificará al cambiar de posición los datos dentro
del vector.
• En la instrucción 2 se define las variables necesarias para efectuar el proceso de
ordenamiento. La variable i se utiliza para identificar a partir de cual posición es que faltan
datos por ordenar. Inicialmente el valor de i es 1, ya que inicialmente faltan todos los datos
por ordenar y los datos comienzan en la posición 1. Cuando el contenido de la variable i
sea 2, significa que faltan por ordenar los datos que hay a partir de la posición 2 del vector;
cuando el contenido de la variable i sea 4, significa que faltan por ordenar los datos que
hay a partir de la posición 4; cuando el contenido de la variable i sea m, significa que
estamos en el último elemento del vector, el cual obviamente estará en su sitio, pues no
hay más datos con los cuales se puede comparar. Esta es la razón por la cual en la
instrucción 3 se pone a variar la i desde 1 hasta m–1.
NOTA: Si deseamos ordenar el vector de forma descendente, simplemente
cambiamos el símbolo menor que (<) por el de mayor que (>) en la instrucción
6.descubre el valor propio de las cosas.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-24-2048.jpg)




![sfs
Algoritmos II
29
siguientes serán todos mayores que ese dato. Luego de efectuar esta operación se procede a
ordenar los datos que quedaron antes y los que quedaron después usando la misma técnica.
Algoritmo Quicksort
Void quickSort (entero m, entero n)
Entero i, j
If (m<n) then
i=m
j=j+1
while (i<j) do
do
i=i+1
while ((i<=n) and (V[i]>=V[m]))
do
j=j-1
while ((j!=m) and (V[j]>=V[m]))
if (i<j) then
intercambia(i,j)
end(if)
end(while)
intercambia(j,m)
Quicksort(m,j-1)
quicksort (j+1, n)
end(if)
End(quinksort)
Método de ordenamiento MERGE SORT
Este método de ordenamiento no busca ubicar inicialmente un dato en la posición que le
corresponde. Simplemente divide el vector en dos subvectores de igual tamaño, los ordena por
separado y luego los intercala. Este método tiene la inconveniencia de que requiere memoria
adicional para ejecutarse.
El algoritmo para sortMerge se escribe a continuación:](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-29-2048.jpg)
![sfs
Algoritmos II
30
Void sortMerge(entero primero, entero ultimo)
entero mitad
if (primero < ultimo) then
mitad=(primero+ultimo)/2
sortMerge(primero, mitad)
sortMerge(mitad + 1, ultimo)
intercalar(primero, mitad,ultimo)
end(if)
End(sortMerge)
El algoritmo para el método intercalar es:
Void intercalar(entero primero, entero mitad, entero ultimo)
Entero i, j, k, b[]
B=new entero[V[0]]
If (primero > mitad) or (mitad + 1 > ulimo) then return
For (k=primero; k <= ultimo; k++) do
b.asigneDato(V[k], k)
end(for)
i=primero
j=mitad + 1
k=primero – 1
while ((i<=mitad) and (j<=ultimo)) do
k=+1
if (b.datoEnPosicion(i)<=b.datoEnPosicion(j)) then
V[k]=b.datoEnPosicion(i)
i=i+1
else
V[k]=b.datoEnPosicion(j)
j=j+1
end(if)
end(while)
while (i<=mitad) do
k=k+1
V[k]=b.datoEnPosicion(i)
i=i+1](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-30-2048.jpg)
![sfs
Algoritmos II
31
end(while)
while (j<=ultimo) do
k=k+1
V[k]=b.datoEnPosicion(j)
j=j+1
end(while)
Fin(intercalar)
Ordenam
Método de ordenamiento COCKTAIL SORT
Es un algoritmo de ordenamiento que surge como una mejora al algoritmo de ordenamiento de
burbuja. Funciona observando que los números grandes se están moviendo rápidamente hasta
el final de la lista (estas son las liebres), pero que los números pequeños (las tortugas) se mueven
solo muy lentamente al inicio de la lista.
La solución plantea ordenar por el método de burbuja y cuando llegamos al final de la primera
iteración, no volver a realizar el cálculo desde el principio, sino, que empecemos desde el final
hasta el inicio. De esa manera siempre se consigue que tanto los números pequeños como los
grandes se desplacen a los extremos de la lista lo más rápido posible
1.3.5 EJERCICIO DE APRENDIZAJE
1. PROCEDIMIENTO cocktail_sort ( VECTOR a[1:n])
2. dirección ← 'frontal', comienzo ← 1, fin ← n-1, actual ← 1
3. REPETIR
4. permut ← FALSO
5. REPETIR
6. SI a[actual] > a[actual + 1] ENTONCES
7. intercambiar a[actual] Y a[actual + 1]
8. permut ← VERDADERO
9. FIN SI
10. SI (dirección='frontal') ENTONCES
11. actual ← actual + 1
12. SI NO
13. actual ←actual - 1
14. FIN SI](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-31-2048.jpg)
![sfs
Algoritmos II
32
15. MIENTRAS
QUE ((dirección='frontal') Y (actual<fin)) OU ((dirección='final) O (actual>comienzo))
16. SI (dirección='frontal') ENTONCES
17. dirección ← 'final'
18. fin ← fin - 1
19. SI NO
20. dirección ← 'frontal'
21. comienzo ← comienzo + 1
22. FIN SI
23. MIENTRAS permut = VERDADERO
24.
25. FIN PROCEDIMIENTO
1.3.6 TALLER DE ENTRENAMIENTO
Void quickSort (entero m, entero n)
Entero i, j
If (m<n) then
i=m
j=j+1
while (i<j) do
do
i=i+1
while ((i<=n) and (V[i]>=V[m]))
do
j=j-1
while ((j!=m) and (V[j]>=V[m]))
if (i<j) then
intercambia(i,j)
end(if)
end(while)
intercambia(j,m)
Quicksort(m,j-1)
quicksort (j+1, n)
end(if)
End(quinksort)](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-32-2048.jpg)
![sfs
Algoritmos II
33
1.4 TEMA 3 ANÁLISIS DE EFICIENCIA DE ORDENAMIENTO Y
BÚSQUEDA
➢Video: ” Análisis de Algoritmos , Complejidad de algoritmos (Actualizado)”
➢” Ver Video”: https://www.youtube.com/watch?v=Sibd8jSTdUQ&t=256s ”
A continuación de mostrara y se realzara un análisis de los algoritmos de ordenamiento y
búsqueda para encintar su contador de frecuencias y su respectivo orden de magnitud con el
objetivo de realizar un comparativo de cual algoritmo en búsqueda y en ordenamiento
respectivamente es el más eficiente:
Análisis del algoritmo Ordenamiento por selección
1. Void selección() 1
2. Entero i, j, k 1
3. For (i = 1; i < n; i++) do n
4. K = i n - 1
5. For (j= j+1; j<=n; j++) do n(n -1)/2 +(n – 1)
6. If v[j] < V[k] then n(n -1)/2
Nota: Realice una prueba de escritorio para un vector de 10 posiciones, la
información en el vector está inicialmente desordenada; después de realizar la
prueba, desde su punto de vista escriba que tan eficiente es el método.
TIPS
La implementación de los métodos de ordenamiento y búsqueda
permiten mejorar el rendimiento en colecciones de datos de grandes
volúmenes que requieren de esos procesos.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-33-2048.jpg)
![sfs
Algoritmos II
34
7. K= j n(n -1)/2
8. End (if) n(n -1)/2
9. End (for) n(n -1)/2
10. Intercambia(i,k) n - 1
11. End (for) n – 1
12. End (selección) 1
Contador de frecuencia = 5n(n – 1)/2 + 5n -1
Y el orden de magnitud es O(n2)
Análisis del algoritmo Ordenamiento por inserción
1. Void Inserción() 1
2. Entero i, j, d 1
3. For (i = 2; i < n; i++) do n
4. d = V[i] n - 1
5. j = i - 1 n(n -1)/2 +(n – 1)
6. While ((j > 0) and (d <[j])) do n(n -1)/2
7. V[j + 1] = V[j] n(n -1)/2
8. j = j - 1 n(n -1)/2
9. End (while) n(n -1)/2
10. V[j + 1] = d n - 1
11. End (for) n – 1
12. End (Inserción) 1
Contador de frecuencia = 4n(n – 1)/2 + 5n - 2
Y el orden de magnitud es O(n2)
Análisis del Algoritmo Búsqueda Binaria
1. primero = 1 1
2. ultimo = n 1
3. while (primero <= ultimo) do log2n + 1
4. Medio = (primero + ultimo) /2 log2n](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-34-2048.jpg)
![sfs
Algoritmos II
35
5. If (V[medio] == x) then return medio log2n
6. If (V[medio] > x) then ultimo = medio - 1 log2n
7. else primero = medio + 1 log2n
8. End (while) log2n
9. write(“el dato” , x , “no existe”) 1
Contador de frecuencia = 6(log2n) + 4
Y el orden de magnitud es O(log2n)
Análisis del algoritmo de Búsqueda Secuencial
1. i = 1 1
2. While ((i <= n) and (V[j] <> x) do n + 1
3. i = i - 1 n
4. End (while) n
5. If (i <= n) then return i 1
6. Else write(“el dato” , x , “no existe”) 1
Contador de frecuencia = 3(n + 4)
Y el orden de magnitud es O(n)
1.4.1 EJERCICIO DE APRENDIZAJE
Análisis del algoritmo Ordenamiento por burbuja
1. Void burbuja() 1
2. Entero i, j 1
3. For (i = 1; i < n; i++) do N
4. For (j= 1; j<=n-i; j++) do n(n -1)/2 +(n – 1)
5. If v[j] > V[j + 1] then n(n -1)/2
6. Intercambia(i, j + 1) n(n -1)/2
7. End (if) n(n -1)/2
8. End (for) n(n -1)/2
9. End (for) n – 1
10. End (burbuja) 1](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-35-2048.jpg)
![sfs
Algoritmos II
36
Contador de frecuencia = 5n(n – 1)/2 + 3n + 1
Y el orden de magnitud es O(n2)
1.4.2 TALLER DE ENTRENAMIENTO
Al siguiente algoritmo coloque al frente cada instrucción el número de veces que se ejecuta cada
una de ellas, además, hallar el contador de frecuencia y el orden de magnitud.
Análisis del algoritmo Ordenamiento por Burbuja mejorado
1. Void burbujaMejorado ()
2. Entero i, j, sw
3. For (i = 1; i < n; i++) do
4 Sw = 0
5. For (j= 1; j<=n-i; j++) do
6. If (V[j] > V[j + 1]) then
7. Intercambia(i, j + 1)
8. sw= 1
9. End (if)
10. End (for)
11. If (sw == 0) then return
12. End (for)
13. End (burbuja)
Contador de frecuencia = ¿?
Y el orden de magnitud es ¿?
TIPS
Los rendimientos de los algoritmos de ordenamiento y búsqueda
alcanzan a llegar a niveles de logarítmicos y semilogarítmicos,
mejorando los órdenes de los lineales y cuadráticos.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-36-2048.jpg)




































![77
Algoritmos II
Crear Crea una pila vacía.
Apilar Incluye el dato d en la pila.
Desapilar
Elimina el último elemento de la pila y deja una nueva pila, la cual queda con un
elemento menos.
Cima Retorna el dato que esta de último en la pila, sin eliminarlo.
esVacia Retorna verdadero si la pila está vacía: de lo contrario; retorna falso.
esLlena Retorna verdadero si la pila está llena; de lo contrario; retorna falso.
2.4.3.2 REPRESENTACIÓN DE PILAS EN UN VECTOR
La forma más simple es utilizar un arreglo de una dimensión y una variable, que llamaremos
tope, que indique la posición del arreglo en la cual se halla el último elemento de la pila. Por
consiguiente, vamos a definir la clase pila derivada de la clase vector. La variable m de nuestra
clase vector funciona coma la variable tope. Definamos entonces la clase pila.
1. CLASE Pila
2. Privado:
3. Object V[]
4. Entero tope, n
5. Publico:
6. pila(entero m) //constructor
7. boolean esVacia()
8. boolean esLlena()
9. void apilar(objeto d)
10. object desapilar()](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-77-2048.jpg)
![78
Algoritmos II
11. void desapilar(entero i)
12. objeto tope()
13. end(Clase)
Como hemos definido la clase pila derivada de la clase vector, veamos como son los algoritmos
correspondientes a estos métodos:
1. pila(entero m) //constructor
2. V = new array[m]
3. n = m
4. Tope = 0
5. end(pila)
1. boolean esVacia()
2. return tope == 0
3. end(esVacia)
1. boolean esLlena()
2. return tope == n
3. end(esLlena)
1. void Apilar(objeto d)
2. if (esLlena()) then
3. write(“pila llena”)
4. return](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-78-2048.jpg)
![79
Algoritmos II
5. end(if)
6. tope = tope + 1
7. V[tope] = d
8. end(Método)
Apilar consiste simplemente en sumarle 1 a tope y llevar el dato a esa posición del vector:
1. objeto desapilar()
2. if (esVacia()) then
3. write(“pila vacia”)
4. return null
5. end(if)
6. d = V[tope]
7. tope = tope -1
8. return d
9. end(desapilar)
Estrictamente hablando, desapilar consiste simplemente en eliminar el dato que se halla en el
tope de la pila. Sin embargo, es usual eliminarlo y retornarlo. Eso es lo que hace nuestro anterior
método para desapilar. El proceso de eliminación consiste simplemente en restarle 1 a tope.
Definamos, en forma polimórfica, otro método para desapilar. Este nuevo método tendrá un
parámetro i, el cual indicara cuantos elementos se deben eliminar de la pila:
1. void Desapilar(entero i )
2. if ((tope – 1) >= 0) then
3. tope = tope – i](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-79-2048.jpg)
![80
Algoritmos II
4. else
5. write(“no se pueden eliminar tantos elementos”)
6. end(if)
7. end(Método)
1. Objeto cima()
2. if (esVacia()) then
3. write(“pila vacia”)
4. return null
5. end(if)
6. return V[tope]
7. end(cima)
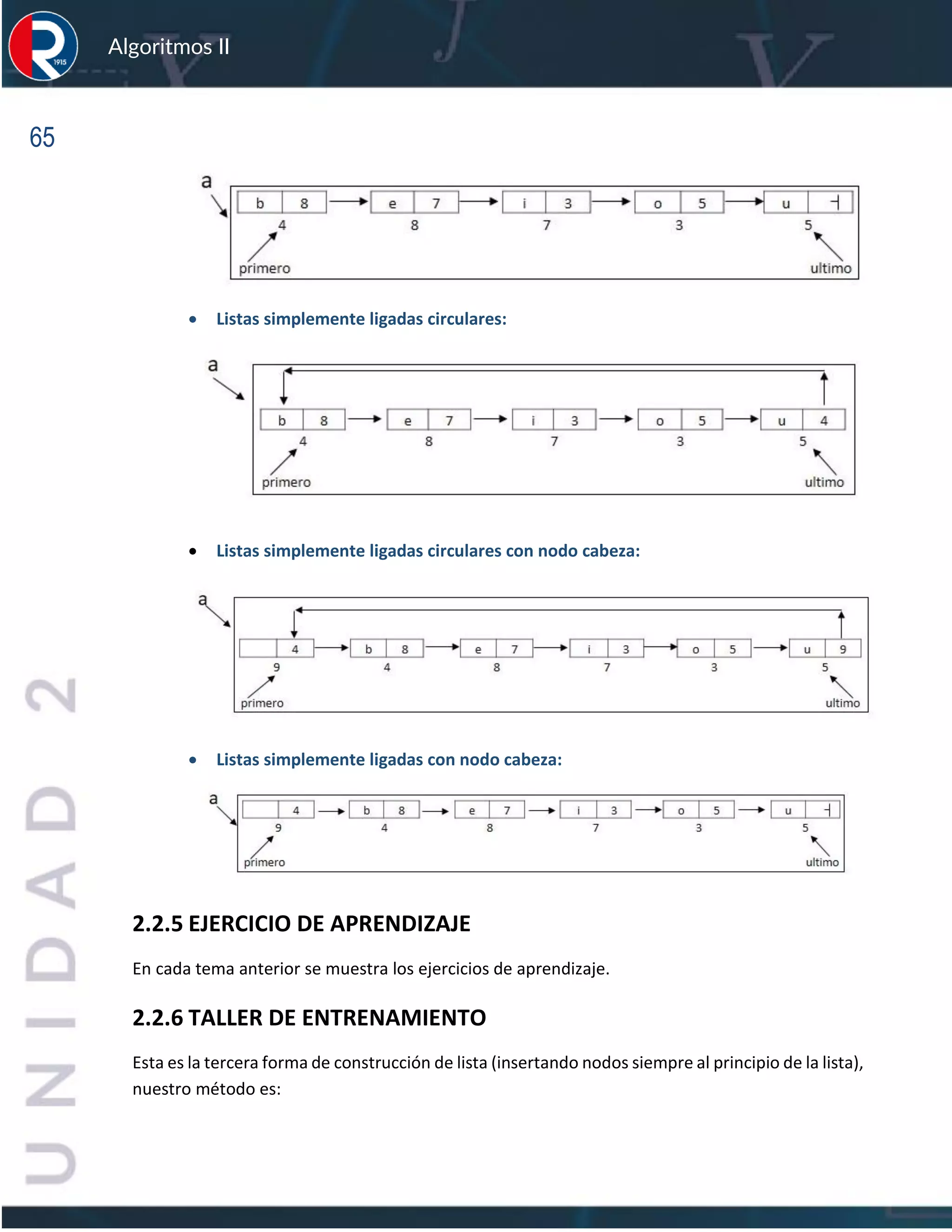
2.4.3.3 REPRESENTACIÓN DE PILAS COMO LISTAS LIGADAS
Para representar una pila como listas ligadas basta definir la clase pila derivada de la clase LSL.
Nuevamente, como estamos definiendo la clase pila derivada de la clase. LSL, podremos hacer
uso de todos los métodos que hemos definido para esta clase LSL. A modo de ejemplo,
representemos como listas ligadas la siguiente pila:
D
C
B
A](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-80-2048.jpg)


![83
Algoritmos II
Sea V el vector en el cual manejaremos las dos pilas. El valor de n es 16. Inicialmente, el valor de
m es 8 (la mitad de n):
• La variable tope1 variara de 1 hasta m
• La variable tope2 variara desde m + 1 hasta n
• La pila 1 estará vacía cuando tope1 sea igual a 0
• La pila 1 estará llena cuando tope1 sea igual a m
• La pila 2 estará vacía cuando tope2 sea igual a m
• La pila 2 estará llena cuando tope2 sea igual a n
Si definimos una clase denominada dosPilas cuyos datos privados son el vector V, m, n, tope1 y
tope2, veamos cómo serán los métodos para manipular dicha clase.
Consideremos primero un método para apilar un dato en alguna de las dos pilas. Habrá que
especificar en cual pila es que se desea apilar. Para ello utilizaremos una variable llamada pila, la
cual enviamos como parámetro del método. Si pila es igual a 1 hay que apilar en pila 1, y si pila
es igual a 2, hay que apilar en pila 2. Nuestro método será:
1. void Apilar(entero pila, objeto d)
2. If (pila == 1) then
3. If (tope == m) then
4. pilaLlena(pila)
5. end(if)
6. tope1 = tope1 + 1
7. V[tope] = d](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-83-2048.jpg)
![84
Algoritmos II
8. else
9. If (tope2 == n) then
10. pilaLlena(pila)
11. end(if)
12. tope2 = tope2 + 1
13. V[tope2] = d
14. end(if)
15. end(Método)
El método pilaLlena recibe como parámetro el valor pila.
La tarea de pilaLlena es: si el parámetro pila es 1 significa que la pila 1 es la que está llena, y por
lo tanto buscara espacio en la pila 2; en caso de que esta no esté llena, se moverán los datos de
la pila 2 una posición hacia la derecha, se actualizara m y se regresara al método apilar para apilar
en la pila 1. Si es la pila 2 la que está llena buscara si hay espacio en la pila 1, y en caso de haberlo
moverá los datos de la pila 2 una posición hacia la izquierda, actualizara m y regresara a apilar en
la pila 2. Un método que efectué esta tarea es:
1. void PilaLlena(entero pila)
2. entero i
3. if (pila == 1) then
4. if (tope2 < n) then //hay espacio en la pila 2
5. for (i = tope2; i > m; i--) do
6. V[i + 1] =V[i]
7. end(for)
8. tope2 = tope2 + 1
9. m = m + 1](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-84-2048.jpg)
![85
Algoritmos II
10. end(if)
11. else
12. if (tope1 < m) then
13. for (i = m; i < tope2; i++) do
14. V[i - 1] = V[i]
15. end(for)
16. tope2 = tope2 – 1
17. m = m – 1
18. end(if)
19. end(if)
20. write(“pilas llenas”)
21. stop
22. end(Método)
Como se podrá observar, la operación de apilar implica mover datos en el vector debido a que
una pila puede crecer más rápido que la otra. En otras palabras, este método tiene orden de
magnitud lineal, el cual se considera ineficiente. Una mejor alternativa de diseño es la siguiente:
La pila 1 se llenara de izquierda a derecha y la pila 2 de derecha a izquierda. Con este diseño no
hay que preocuparse por cual pila crezca más rápido. Las condiciones a controlar son:
• La pila 1 estará vacía cuanto tope1 sea igual a cero
• La pila 2 estará vacía cuando tope2 sea igual a n + 1 (n =16)
• Las pilas estarán llenas cuando tope1 + 1 sea igual a tope2](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-85-2048.jpg)
![86
Algoritmos II
El método apilar para este segundo diseño es:
1. void Apilar(entero pila, objeto d)
2. if (tope1 + 1 == tope2) then
3. pilaLlena
4. end(if)
5. if (pila == 1) then
6. tope1 = tope1 + 1
7. V[tope] = d
8. end(if)
9. end(Método)
2.4.4 TEMA 3 COLAS CON VECTORES Y LISTAS
Las cola como vectores son estructuras de almacenamiento de datos, donde se maneja de forma
estática, donde las operaciones de inserción se hace al final y las de borrado se hace al principio,
en otras palabras el primero que llega es el primero en salir, y el último en llegar será el último en
salir, de igual forma se maneja con las listas pero de forma dinámica.
2.4.4.1 DEFINICIÓN
Una cola es una lista ordenada en la cual las operaciones de inserción se efectúan en un extremo
llamado último y las operaciones de borrado se efectúan en el otro extremo llamado primero. Es
una estructura FIFO (First Input First Output).
Como podrá observar, con este diseño el proceso para pila llena no aparece; por lo
tanto, no hay que mover los datos del vector y nuestro método para apilar tiene
orden de magnitud constante.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-86-2048.jpg)


![89
Algoritmos II
Donde la variable primero valdrá 3 y la variable ultimo 5
Al desencolar nuevamente, la configuración del vector será:
Donde la variable primero vale 4 y la variable ultimo 5.
Si desencolamos de nuevo, la configuración del vector será:
Y la variable primero vale 5 y la variable ultimo 5.
En otras palabras; primero es igual a ultimo y la cola está vacía, o sea que la condición de la cola
vacía será primero == ultimo. Teniendo definidas las condiciones de la cola llena y cola vacía
procedamos a definir la clase cola:
1. CLASE Cola
2. Privado
3. Entero primero, n
4. Objeto V[ ]
5. Publico
6. Cola(n) //constructor
7. boolean esVacia()](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-89-2048.jpg)
![90
Algoritmos II
8. boolean esLlena()
9. void encolar(objeto d)
10. Objeto desencolar()
11. Objeto siguiente()
12. end(Clase)
1. Cola(entero m)
2. n = m
3. primero = ultimo = 0
4. V = new objeto[n]
5. end(cola)
1. Boolean esVacia()
2. Return primero == ultimo
3. end(esVacia)
1. Boolean esLlena()
2. return primero == 0 and ultimo == n
3. end(esLlena)
1. void encolar(objeto d)
2. if (esLlena()) then
3. write (“cola llena”)
4. return
5. end(if)
6. If (ultimo == n) then
7. for (i = primero + 1; i <=n; i ++)
8. V[I - primero] = V[i]
9. end(for)
10. ultimo = ultimo – primero
11. primero = 0
12. end(if)
13. ultimo = ultimo + 1
14. V[ultimo] = d
15. end(Método)
1. objeto desencolar()
2. If (esVacia()) then
3. write(“cola vacía”)](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-90-2048.jpg)
![91
Algoritmos II
4. return null
5. end(if)
6. primero = primero + 1
7. return V[primero]
8. end(desencolar)
Si consideramos una situación como la siguiente:
n vale 7, ultimo vale 6 y primero vale 1.
Si se desea encolar el dato h y aplicamos el método encolar definido, la acción que efectúa dicho
método es mover los elementos desde la posición 1 hasta la 6, una posición hacia la izquierda de
tal forma que quede espacio en el vector para incluir la h en la cola. El vector quedara así:
Con primero valiendo -1 y ultimo valiendo 5. De esta forma continua la ejecución del método
encolar y se incluye el dato h en la posición 6 del vector. El vector queda así:
Con primero valiendo -1 y ultimo valiendo 6.
Si en este momento se desencola, el vector queda así:
Con primero valiendo 0 y ultimo valiendo 6.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-91-2048.jpg)

![93
Algoritmos II
Al encolar el dato e el vector queda así:
Y las variables: primera y última valdrán 2 y 6 respectivamente. Al encolar de nuevo el dato f,
aplicamos el operador % y obtenemos el siguiente resultado:
Ultimo = (6 + 1) % 7
El cual es 0, ya que el residuo de dividir 7 por 7 es 0. Por consiguiente, la posición del vector a la
cual se llevara el dato f es la posición 0. El vector quedara con la siguiente conformación:
Con ultimo valiendo 0 y primero 2. De esta forma hemos podido encolar en el vector sin
necesidad de mover elementos en él.
Los métodos para encolar y desencolar quedan así:
1. void encolar(objeto d)
2. Ultimo = (ultimo + 1) % n
3. if (ultimo == primero) then
4. colaLlena()
5. end(if)
6. V[ultimo] = d
7. end(Método)
1. objeto desencolar()
2. if (primero == ultimo) then](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-93-2048.jpg)
![94
Algoritmos II
3. colaVacia
4. end(if)
5. primero = (primero + 1) % n
6. d = V[primero]
7. end(desencolar)
Es importante notar que la condición de cola llena y cola vacía es la misma, con la diferencia de
que en el método encolar se chequea la condición después de incrementar último. Si la condición
resulta verdadera invoca el método colaLlena, cuya función será dejar último con el valor que
tenía antes de incrementarla y detener el proceso, ya que no se puede encolar. Por consiguiente
habrá una posición del vector que no se utilizara, pero que facilita el manejo de las condiciones
de cola vacía y cola llena.
2.4.4.4 REPRESENTACIÓN DE COLAS COMO LISTAS LIGADAS
Definimos la cola como derivada de la clase LSL:
Encolar: consiste en insertar un registro al final de una lista ligada:
1. void encolar(objeto d)
2. Insertar(d, ultimoNodo())
3. end(Método)
Desencolar: consiste en borrar el primer registro de una lista ligada (exacto a desapilar). Habrá
que controlar si la cola está o no vacía](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-94-2048.jpg)





![101
Algoritmos II
3.3 TEMA 2 DEFINICIÓN, CONCEPTOS, REPRESENTACIÓN Y
RECORRIDOS DE ARBOLES
➢ Video: ” UTPL ÁRBOLES [(INFORMÁTICA)(ESTRUCTURA DE DATOS)]”
➢” Ver Video”: https://www.youtube.com/watch?v=DdCoaWzLw2g ”
3.3.1 RELACIÓN DE CONCEPTOS
La estructura árbol que es recursiva por definición es utilizada en diversos tipos de soluciones
como por ejemplo la estructura de almacenamiento en disco de los archivos y directorios a partir
el espacio particionado de disco en un sistema operativo.
3.3.2 ARBOLES
ARBOLES GENERALES Y SU REPRESENTACIÓN
La definición de árboles parte del concepto de árbol general que no incluye el árbol sin ningún
registro. Además, se definen los conceptos básicos asociados a los árboles.
3.3.2.1 DEFINICIÓN DE ARBOLES GENERALES
Un árbol es un conjunto de n registros(n>0), donde el árbol vacío no está definido, de tal manera
que hay un registro llamado raíz y los otros registros están partidos en conjuntos disjuntos cada
uno de los cuales tiene las mismas características de la definición del árbol (esta característica
hace comportar la estructura árbol como recursiva). Gráficamente:
TIPS
La recursividad optimiza el rendimiento de los algoritmos, eliminando
estructuras repetitivas.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-101-2048.jpg)















![117
Algoritmos II
3.4.1.2 CONSTRUCCIÓN DE UNA LISTA LIGADA QUE REPRESENTA UNA LISTA
GENERALIZADA (ESTILO, TÍTULO 4)
Se debe tener en cuenta la forma en que se define la hilera de entrada que representa la lista
generalizada así: paréntesis abierto, átomos, comas, paréntesis cerrado. El algoritmo recibe como
parámetro de entrada la hilera h que representa el conjunto:
Void conslg(string s)
Stack pila=new stack() //estructura pila para las sublistas
X=new nodolg(null) //consigue nuevo nodo de la lista a crear
L=x //inicialización de punteros de la lista
Ultimo =x
n=longitud(s) // n contiene el tamaño de la cadenas
for(i=2;i<n;i++) do //ciclo para recorrer la cadena
Casos para s[i] //casos para determinar que viene en la cadena
Átomo:
Ultimo.asignasw(0) //crea el átomo en la lista
Ultimo.asignadato(s[i])
“,” x=new nodolg(null) //crea otro nodo para lo que venga
Ultimo.asignaliga(x) //en la lista a continuación
Ultimo=x
“(“ pila.apilar(ultimo) //se debe construir una sublista
x=new nodolg(null)
Ultimo.asignasw(1)
Ultimo.asignadato(x)
Ultimo=x
“)” ultimo=pila.desapilar //se terminó de la construcción de la](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-117-2048.jpg)



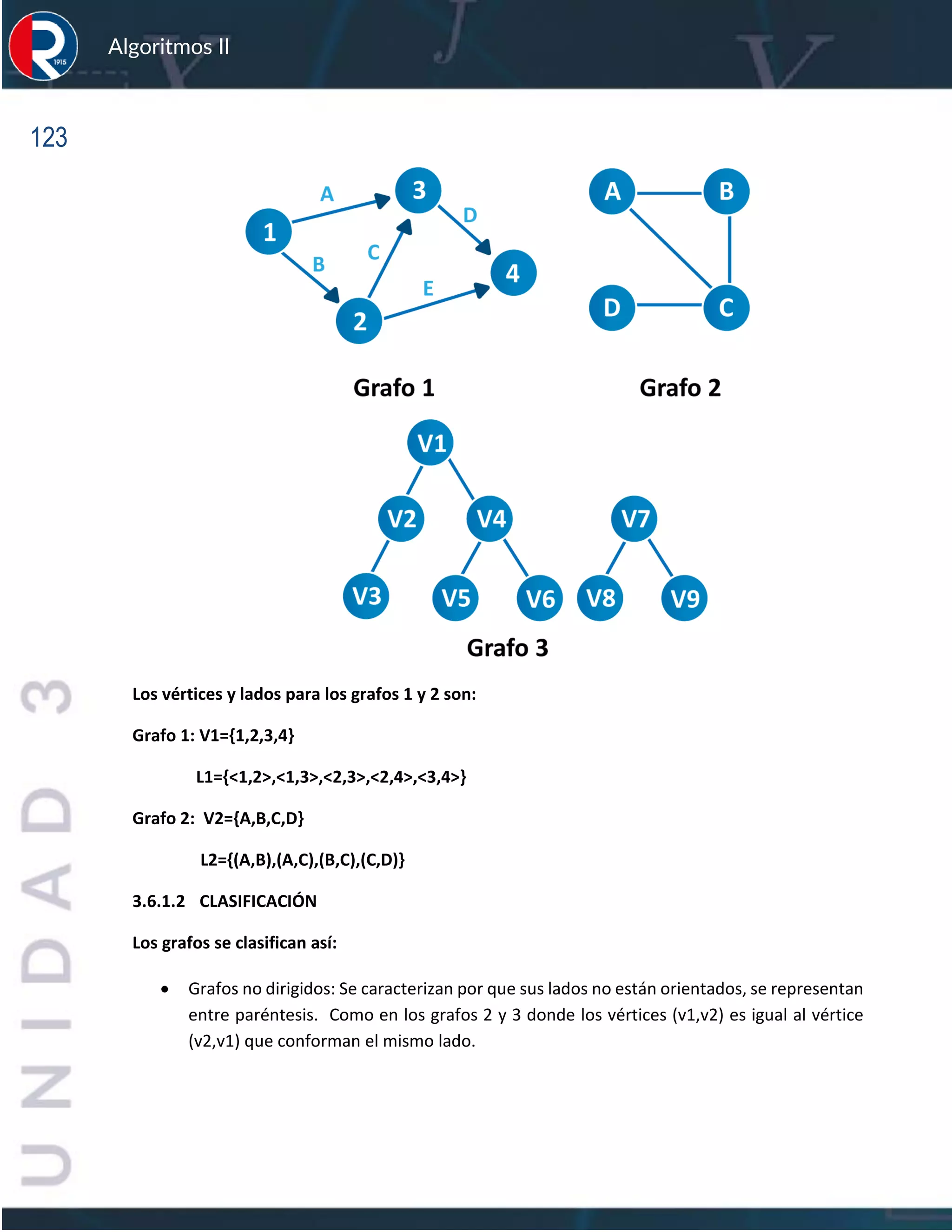



![127
Algoritmos II
La representación con listas ligadas de adyacencia para el Grafo1 será:
• Multilista de adyacencia: Se define un registro para representar cada lado del grafo. El
lado está conformado por dos vértices. La configuración del nodo es la siguiente:
Vi Vj LVi L Vj Sw
➢ LVi: Apunta hacia otro registro que representa un lado incidente a Vi
➢ LVj: Apunta hacia otro registro que representa un lado incidente a Vj
➢ Sw: bandera usada para métodos sobre el grafo.
Donde se crea un vector V[i] apunta al primer nodo de la lista de nodos con los que se representan
los lados incidentes al vértice i. La lista ligada que corresponde a un vértice v contiene los lados
incidentes sobre el vértice v
• Matriz de incidencia: se define como una matriz de m filas y n columnas con: n: número
de vértices del grafo y n: número de lados del grafo.
Para hacer la representación se deben numerar los lados del grafo (aleatoriamente).
Para el grafo 2 del ejemplo inicial:](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-127-2048.jpg)
![128
Algoritmos II
Lado (A,B) se numera con 1
Lado (A,C) se numera con 2
Lado (B,C) se numera con 3
Lado (C,D) se numera con 4
En este caso m=4, n=4 (la matriz tiene 4 filas representan los vértices y 4 columnas
representan los lados)
Si denominados la matriz como In
In[i][j] es igual a 1 si el lado j es incidente sobre el vértice i y es 0 si el lado j no es incidente
sobre el vértice i
La representación del grafo seria:
In 1 2 3 4
A 1 1
B 1 1
C 1 1](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-128-2048.jpg)

![130
Algoritmos II
o Para ejercer el control sobre los visitados o no se utiliza un vector v[i] que tiene 0
si el vértice I no ha sido visitado y que vale 1 si el vértice ya fue visitado.
Inicialmente el vector de visitados se inicializa con ceros.
Un algoritmo para el DFS seria:
Void DFS ( int i ) //el método recibe el vértice donde arranca el grafo
V[i]=1 // el vértice ya fue visitado se pone en uno el vector
Para todo vertice w adyacente a i haga //ciclo que recorre los vértices adyacentes
If (V[i]==0) entonces // pregunta si el vértice no ha sido visitado
DFS(w) // hace un llamado recursivo a DFS con w
Fin (if)
Fin (para)
Fin (DFS)
El parámetro i indica el vértice a partir del cual se comienza a hacer el recorrido DFS. La
determinación de los vértices adyacentes depende de la forma en que está representado
el grafo.
1. Realizar el recorrido DFS sobre grafos representado como matriz de incidencia: Debe
recorrer la matriz de incidencia para determinar, por cual vértice realizo el recorrido.
Después debe llamar recursivamente a dfs con el siguiente lado del grafo y así de manera
sucesiva.
Void dfs(entero v)
Visitado[v]=1
Para (w=1,w<n,w++) do
Para (v=1,v<m,v++) do
Si (incidente[w] [v]==1) entonces
Si (visitado[w]==0) entonces
dfs(w)
fin si
fin si
fin mientras
fin mientras
fin(dfs)
• Recorrido BFS:
Su nombre en inglés lo que hace es justificar primero la búsqueda a lo ancho del grafo. En
este algoritmo se visitan todos los vértices adyacentes a un vértice dado.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-130-2048.jpg)
![131
Algoritmos II
La forma en que este recorrido se maneja sobre el grafo, supone que debe manejar una
cola que indique el orden en que se han ido visitando los vértices, a este vector cola lo
denominaremos visitado
El algoritmo para hacer un recorrido BFS sobre grafos en forma general es:
void BFS(entero v) //recibe como parámetro el vértice
donde inicia
visitado[v]=1 // marca el vértice como visitado
cola.encolar(v) // encola el vértice en los
visitados
while ( cola.esvacia<>vacia) do // ciclo para preguntar por
visitados
v=cola.desencolar() // desencola el vértice v
imprima(v) // imprime el vértice en el recorrido
para todo vértice w adyacente a v haga // ciclo para recorrer vértices
adyacentes a v
if(visitado(w)==0) then // pregunta si w fue visitado o
no
visitado(w)=1 // marca como visitado a w
cola.encolar(w) // lleva el vértice a la cola
fis(si)
fin(para)
fin(while)
fin(BFS)
La determinación de los vértices w adyacentes a un vértice v dependerá de la forma como
se tenga representado el grafo.
A continuación se muestra un recorrido BFS con el grafo representado como matriz de
adyacencia:
void BFS(entero v) //recibe como parámetro el vértice
donde inicia
visitado[v]=1 // marca el vértice como visitado
cola.encolar(v) // encola el vértice en los
visitados
while ( cola.esvacia<>vacia) do // ciclo para preguntar por
visitados](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-131-2048.jpg)
![132
Algoritmos II
v=cola.desencolar() // desencola el vértice v
imprima(v) // imprime el vértice en el recorrido
para (w=1;w<=n;w++) haga // ciclo para recorrer adyacentes
if(adya[v] [w]==1) then // pregunta por vector de
adyacentes
if(visitado(w)=0) then// pregunta si w fue visitado o no
visitado[w]=1 // marca w como visitado
cola.encolar(w) // encola el visitado
fin(si)
fis(si)
fin(para)
fin(while)
fin(BFS)
Revisar implementación de grafos en Java Caminos mínimos:
➢ Video: ” Grafos, El Camino Más Corto, Implementación (EDDJava)”
➢” Ver Video”: https://www.youtube.com/watch?v=xK0ShW9G-
Ts&ebc=ANyPxKqDE3I0CdiQnRu402itJt-OKWO_7yr1-oQdD-
29MRJDIyV35kY0a6nUelWFSD30vC01d5Kr2Q5bSyG_8vYDFwGrWNv2jg ”
Revisar grafos en Netbeans también interesante desde la programación con grafos
➢ Video: ” Grafos(Graphs) En NetBeans(java). prim y dijkstra”
➢” Ver Video”: https://www.youtube.com/watch?v=NQxpzlGpZS0 ”
Ejercicios propuestos del capítulo:
1. Elabore un algoritmo que imprima el recorrido DFS de un grafo representado como matriz
de adyacencia.
2. Elabore un algoritmo que imprima el recorrido BFS de un grafo representado como listas
ligadas de adyacencia](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-132-2048.jpg)


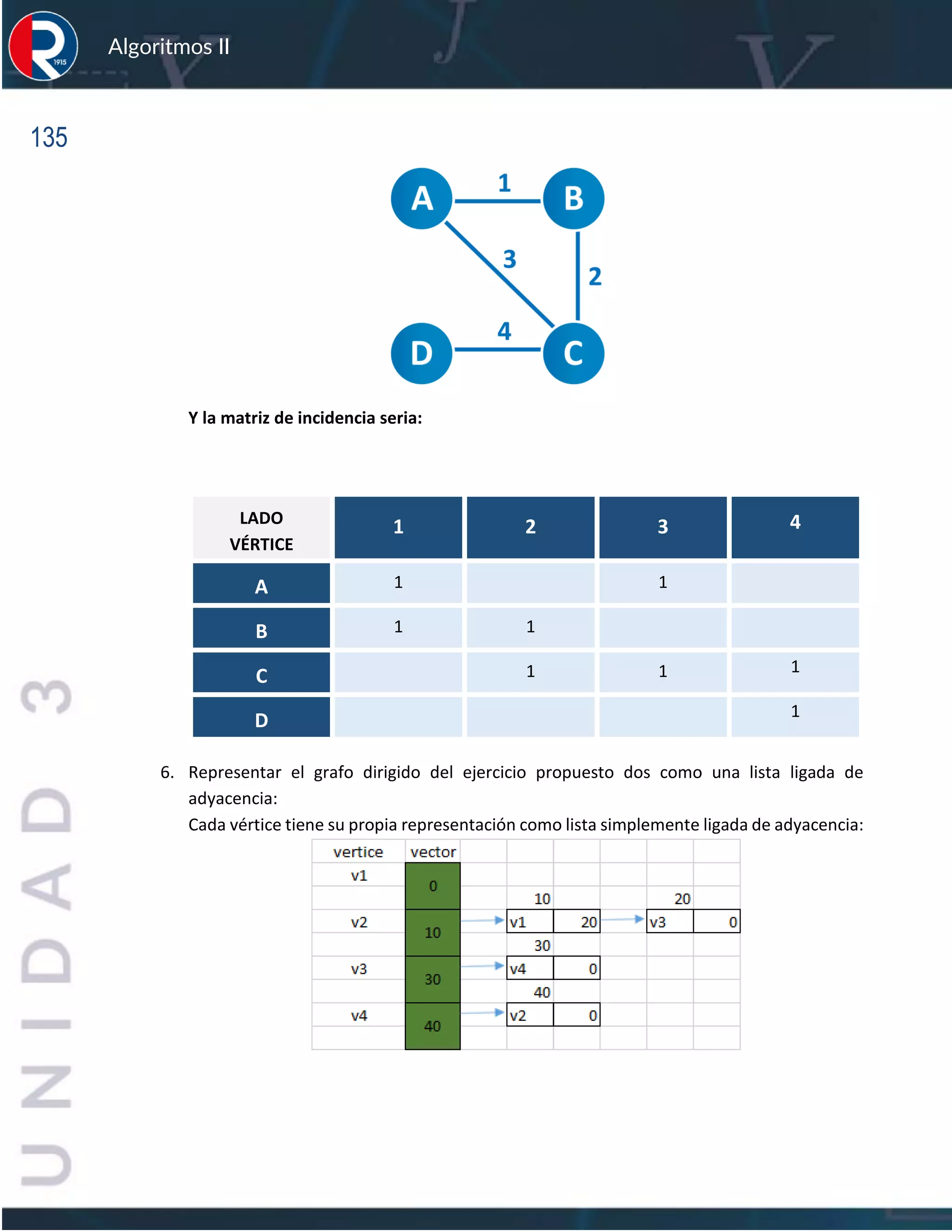
![136
Algoritmos II
3.6.2 EJERCICIO DE APRENDIZAJE
Un método general de representación para un grafo teniéndolo representado como listas ligadas
de adyacencia seria:
Void DFS (entero i) //el método recibe el vértice donde arranca el grafo
V[i]=1 // el vértice ya fue visitado se pone en uno el vector
p=vec[i] // p apunta al primer nodo del vector de la lista
While (p<>null) do // recorre con p hasta el último nodo
w=p.retornaDato() // asigna a w el dato de p
If(V[w]==0) entonces // pregunta si w fue visitado o no
DFS(w) // si no fue visitado hace llamado recursivo a DFS
Fin(if)
P=p.retornaLiga() // Actualiza la liga de p
Fin(mientras)
Fin (DFS)
3.6.3 TALLER DE ENTRENAMIENTO
7. Realizar el recorrido DFS sobre grafos representado como matriz de incidencia: Debe
recorrer la matriz de incidencia para determinar, por cual vértice realizo el recorrido.
Después debe llamar recursivamente a dfs con el siguiente lado del grafo y así de manera
sucesiva.
8. Realizar el recorrido DFS sobre grafos representado como matriz de adyacencia: Debe
recorrer la matriz de adyacencia para determinar, por cual vértice realizo el recorrido.
Después debe llamar recursivamente a dfs con el siguiente vertice adyacente según la
matriz de representación del grafo y así de manera sucesiva.
TIPS
Los grafos son estructuras de gran utilidad para soluciones reales a nivel
de programación.](https://image.slidesharecdn.com/algoritmosii2020-220831205853-6a35134e/75/Algoritmos-II_2020-pdf-136-2048.jpg)










































