Descargado 120 veces



















![Referencias
● High Performance MySQL
● Building Scalable Web Sites
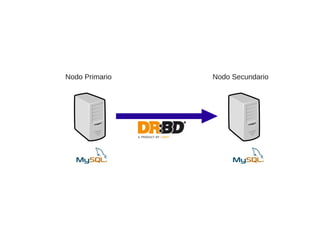
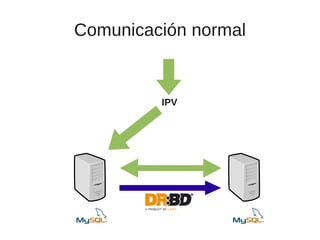
● DR:BD [www.drbd.org]
● MySQL [www.mysql.com]
● MySQL Replication Features
(Thalmann, Lars)](https://image.slidesharecdn.com/mysql-ha-130205221432-phpapp01/85/Alta-disponibilidad-con-MySQL-43-320.jpg)


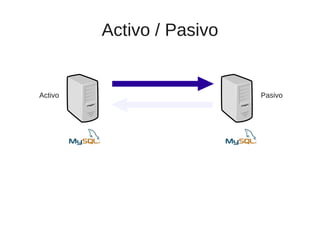
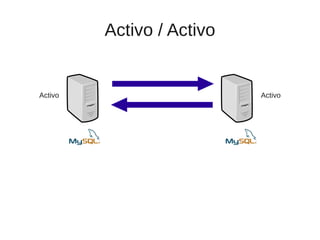
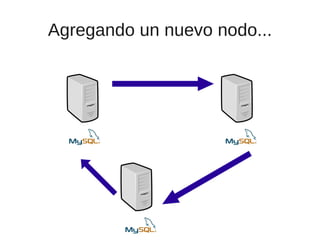
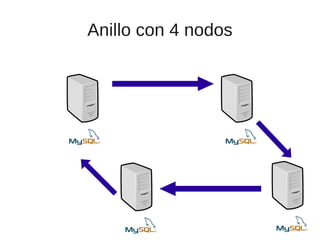
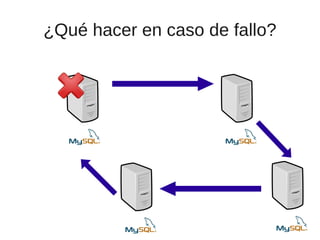
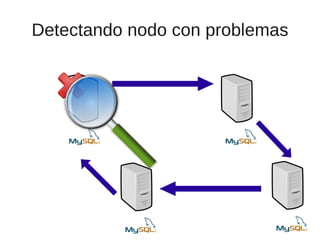
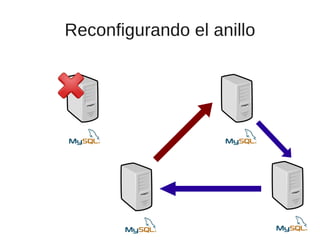
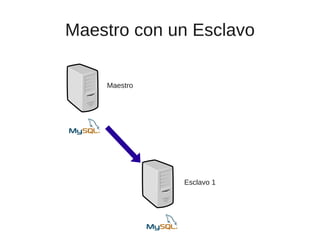
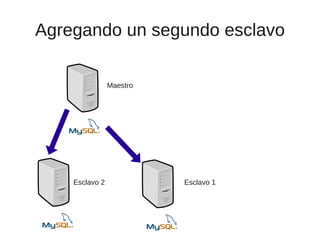
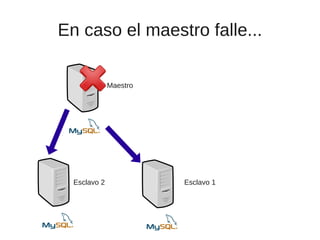
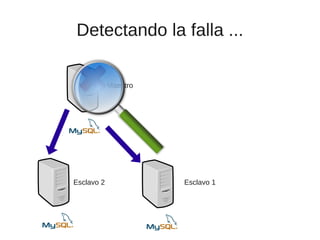
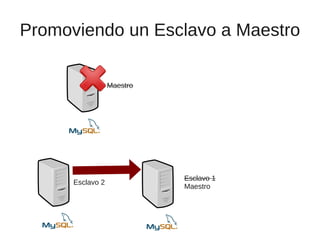
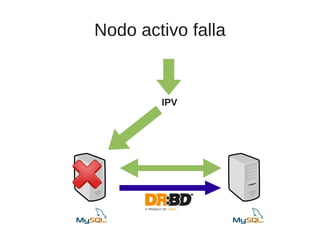
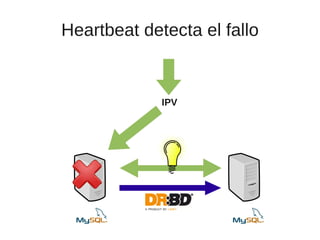
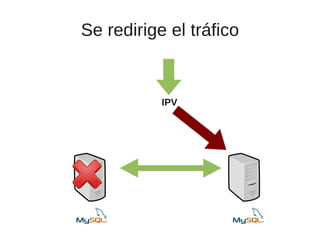
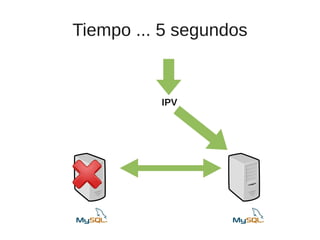
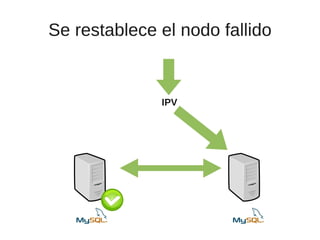
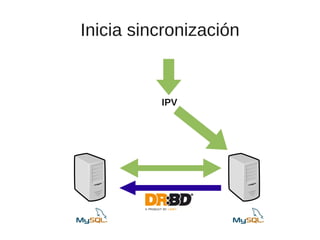
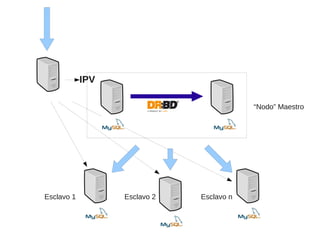
El documento trata sobre la alta disponibilidad en sistemas MySQL, destacando la importancia de la replicación, tolerancia a fallos y redundancia. Se presentan configuraciones para replicación maestro-esclavo y maestro-maestro, así como procedimientos para manejar fallos y migraciones. También se mencionan futuras mejoras en la replicación y la gestión de nodos para optimizar el rendimiento y la disponibilidad.










































































