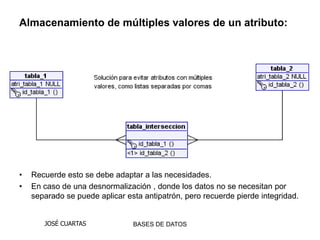
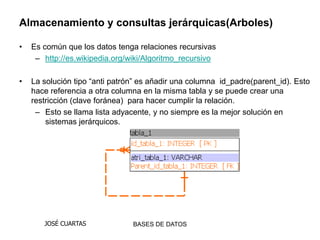
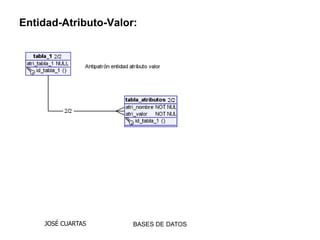
Este documento describe varios antipatrones comunes en SQL, incluyendo almacenar múltiples valores en una columna, usar una sola tabla genérica para diferentes tipos de entidades, y dividir datos en múltiples tablas similares ("tribbles"). Estos patrones dificultan consultas y mantenimiento. Se recomiendan enfoques como tablas de intersección y herencia para modelar datos de forma más normalizada y flexible.