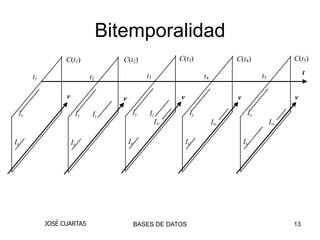
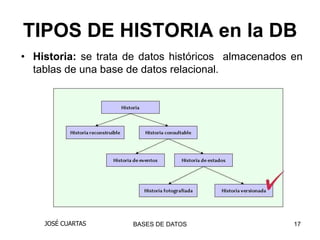
El documento describe los conceptos de bases de datos temporales y la importancia de almacenar información histórica. Explica que las bases de datos convencionales solo representan un estado de los datos en un momento, mientras que las bases de datos temporales administran la variación de los datos a través del tiempo. También discute los conceptos de tiempo de validez, tiempo de transacción y bitemporalidad.





































































![Bases de datos[1]](https://cdn.slidesharecdn.com/ss_thumbnails/basesdedatos1-171024190720-thumbnail.jpg?width=640&height=640&fit=bounds)














































