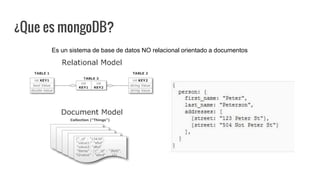
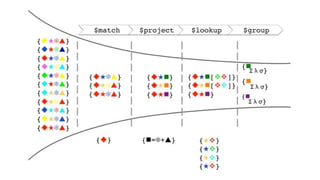
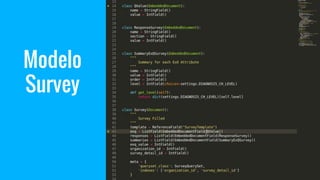
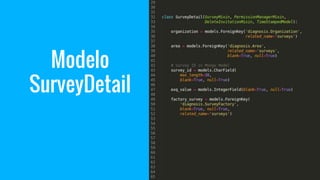
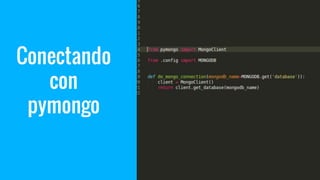
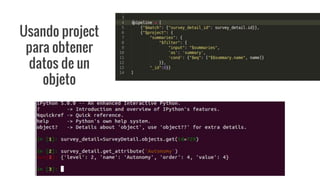
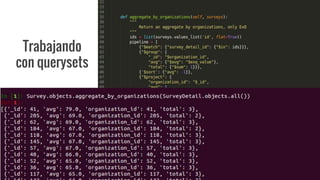
El documento explora el uso del framework de agregación en MongoDB con PyMongo y su integración en aplicaciones Django. Se detallan las etapas del pipeline de agregación y los operadores utilizados para transformar y consultar datos. Además, se proporciona un ejemplo práctico de creación y manipulación de documentos y consultas ad-hoc.