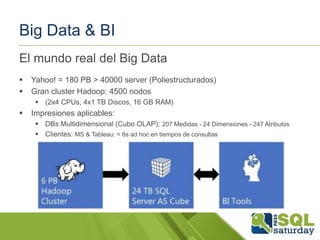
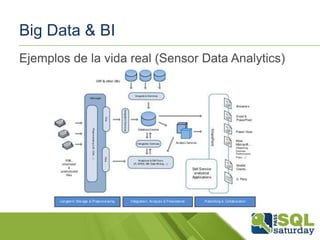
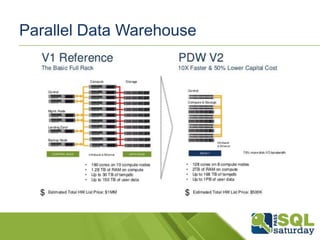
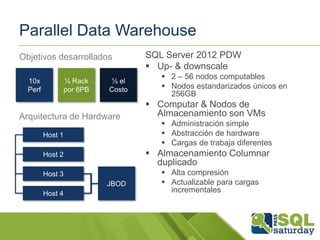
Descargado 51 veces




















![Big Data en la nube
Utilizando el almacenamiento Blob de HDInsight
•
•
•
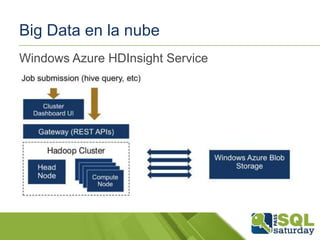
El cluster HDInsight está enlazado a una cuenta de almacenamiento blob
"predeterminada" y los contenedores en clúster al mismo tiempo
Mediante el contenedor "por defecto" no exige afrontar acceso especial ("/"
== carpeta raíz, etc)
Acceso a cuentas de almacenamiento blob adicionales o contenedores:
asv[s]://<container>@<account>.blob.core.windows.net/<path>
•
Cuentas de almacenamiento deben ser registrados en site-config.xml:
<property>
<name>fs.azure.account.key.accountname</name>
<value>enterthekeyvaluehere</value>
</property>](https://image.slidesharecdn.com/bigdataalmacenesdedatosempresarialesedwywindowsazuresqldatabasecomoplataformabi-131208064716-phpapp01/85/Big-Data-Almacenes-de-datos-empresariales-EDW-y-Windows-Azure-SQL-Database-como-Plataforma-BI-26-320.jpg)


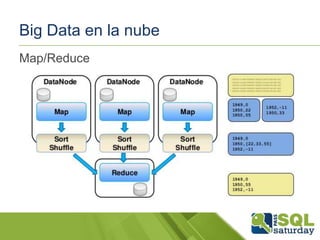
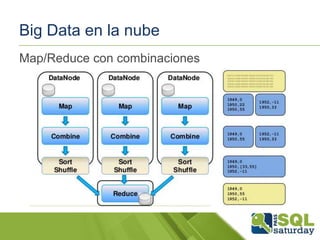




























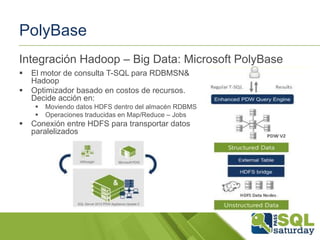


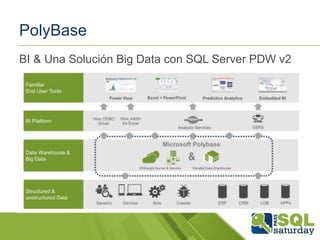
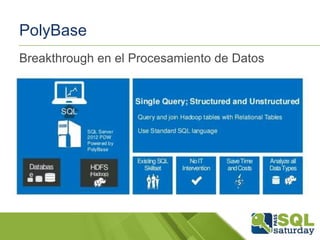



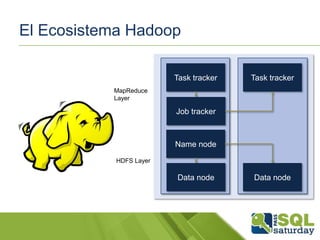
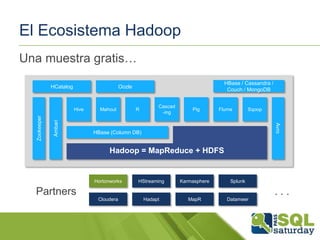
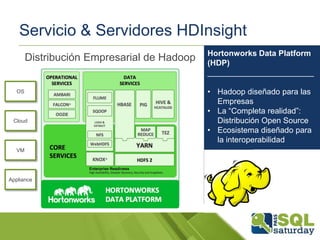
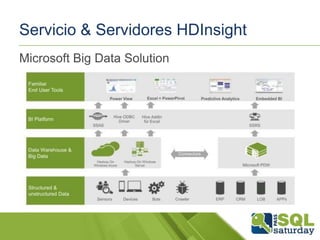
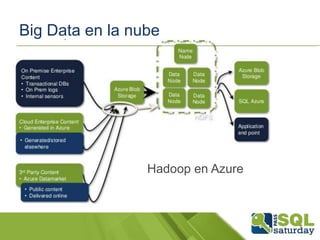
El documento presenta una visión general del ecosistema Hadoop y su integración con Microsoft Azure para el manejo de Big Data. Se abordan las características del Big Data, las diferencias con los RDBMS tradicionales, y se destaca el uso de herramientas como Hive y Polybase para optimizar la gestión de datos. Además, se discute la importancia de Hadoop en el procesamiento de grandes volúmenes de datos y su repercusión en el ámbito empresarial.




















































































