Descargar para leer sin conexión




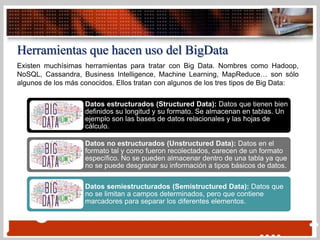


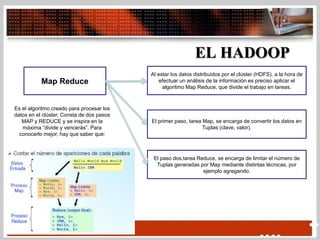





Este documento describe el Big Data y Hadoop. Explica que el Big Data se refiere a grandes cantidades de datos que superan la capacidad del software habitual de gestionarlos. Luego describe que Hadoop es un sistema de código abierto que se utiliza para almacenar, procesar y analizar grandes volúmenes de datos a través de múltiples nodos. Usa MapReduce para dividir el procesamiento de datos en tareas de mapeo y reducción para procesar los datos de manera distribuida.












































































