Descargado 13 veces


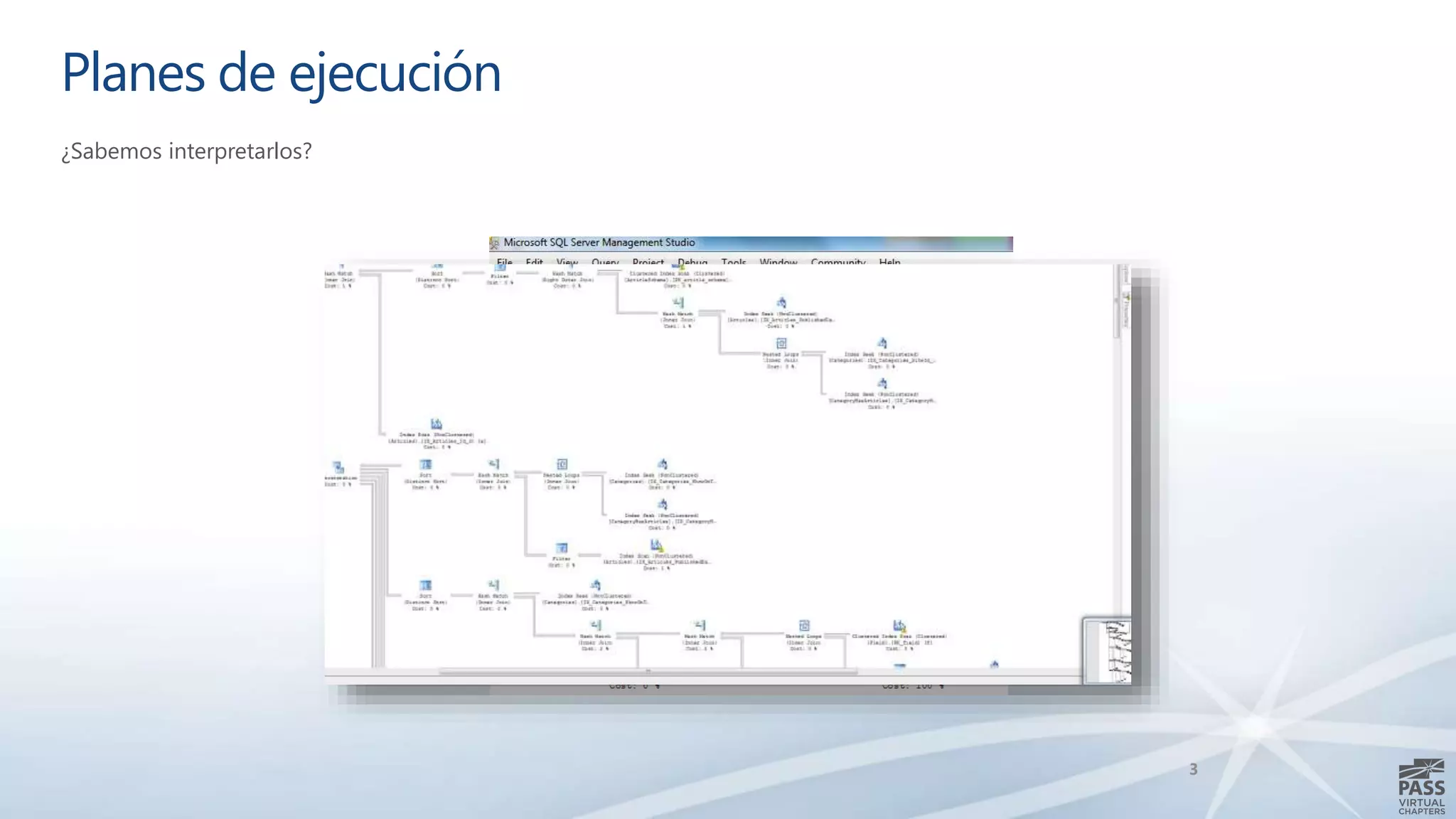
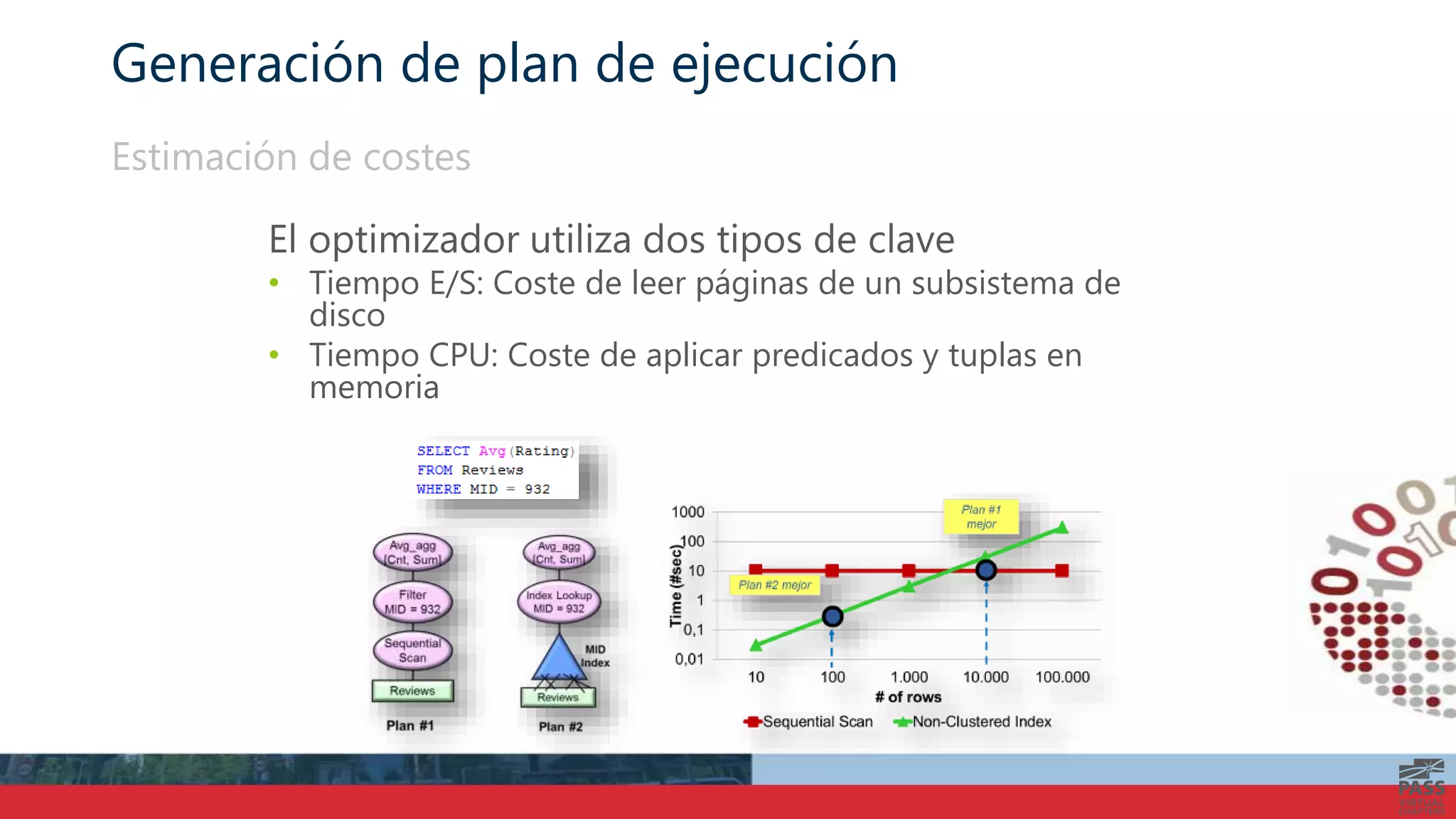
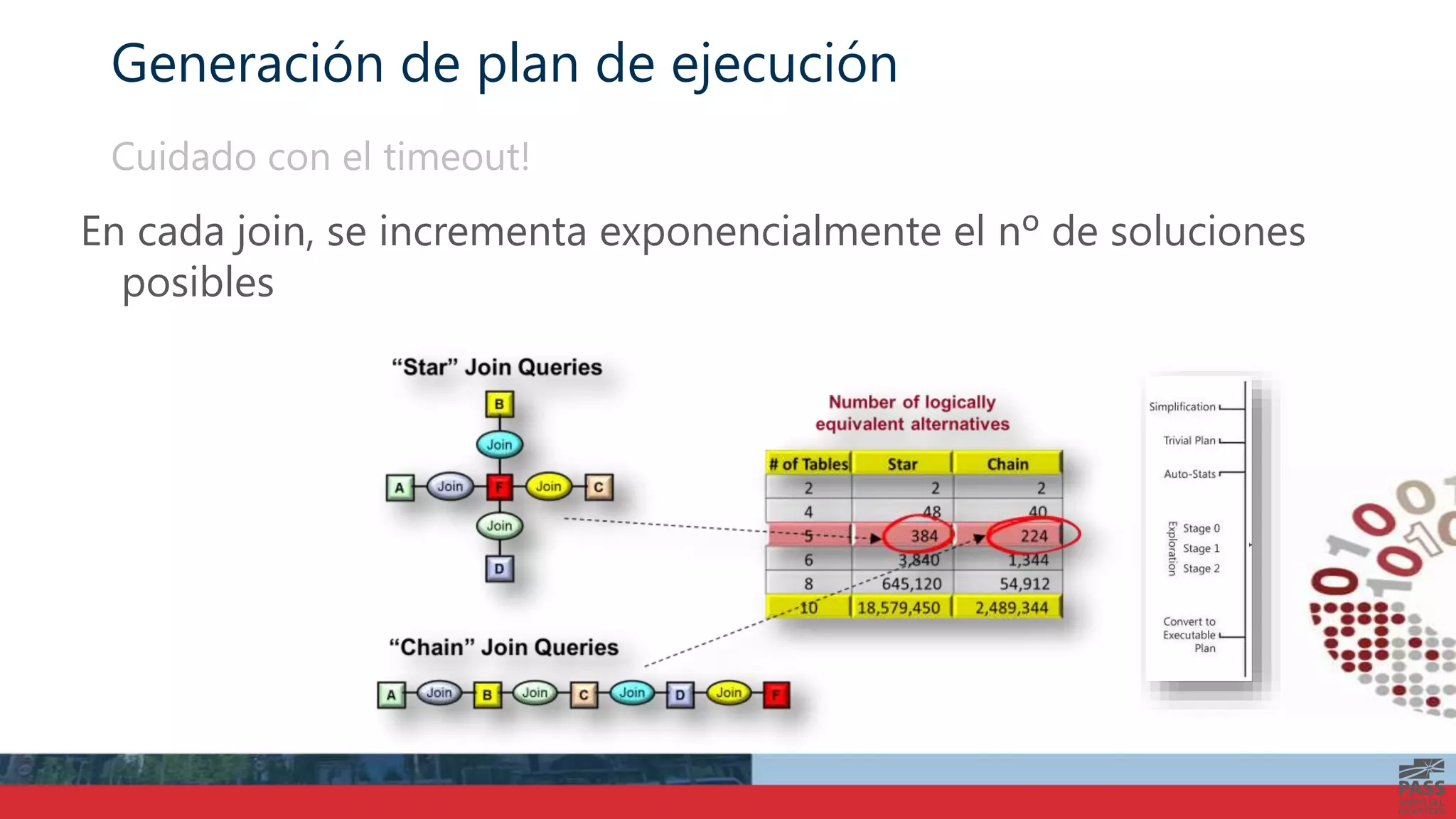
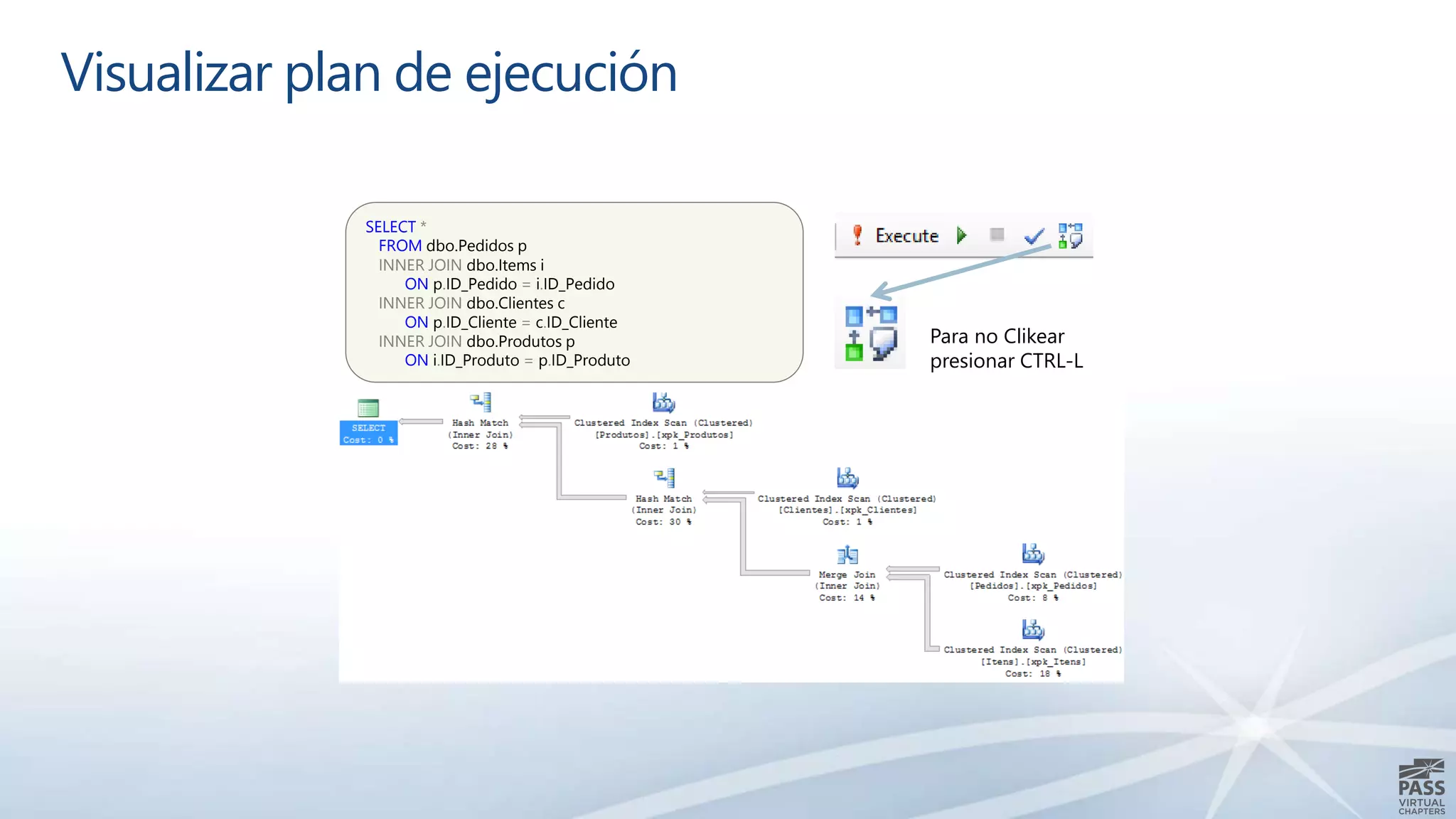
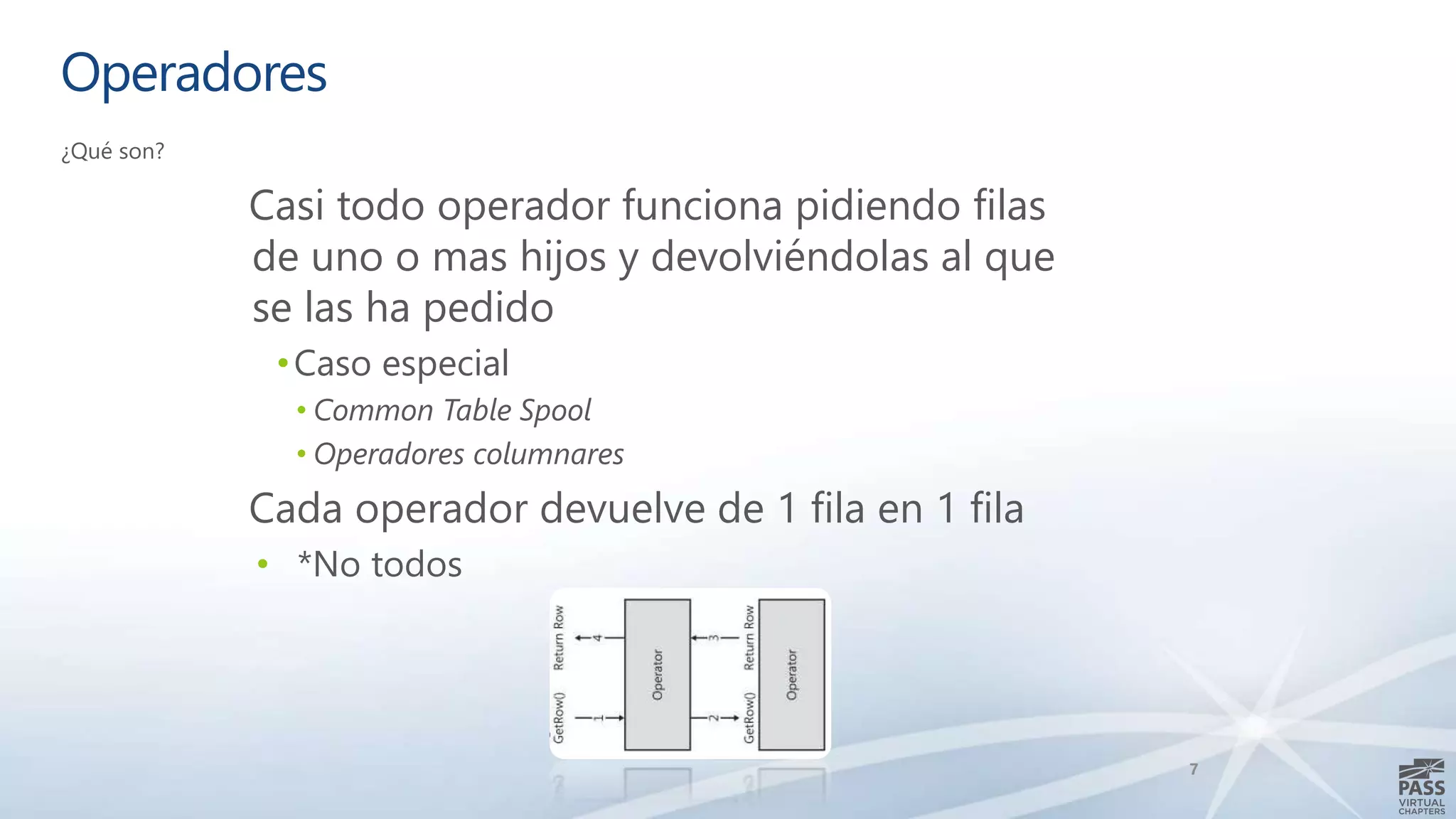
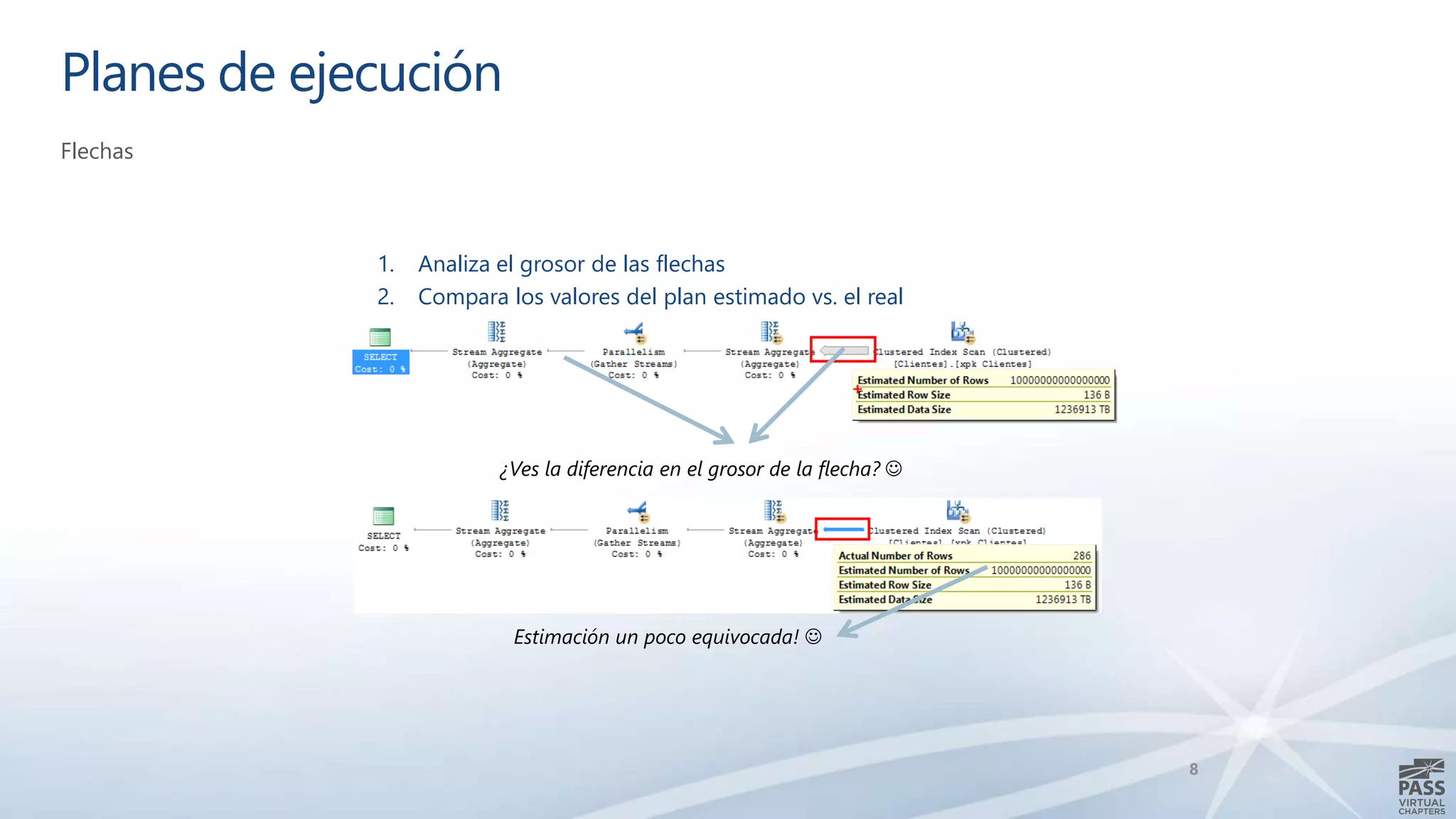
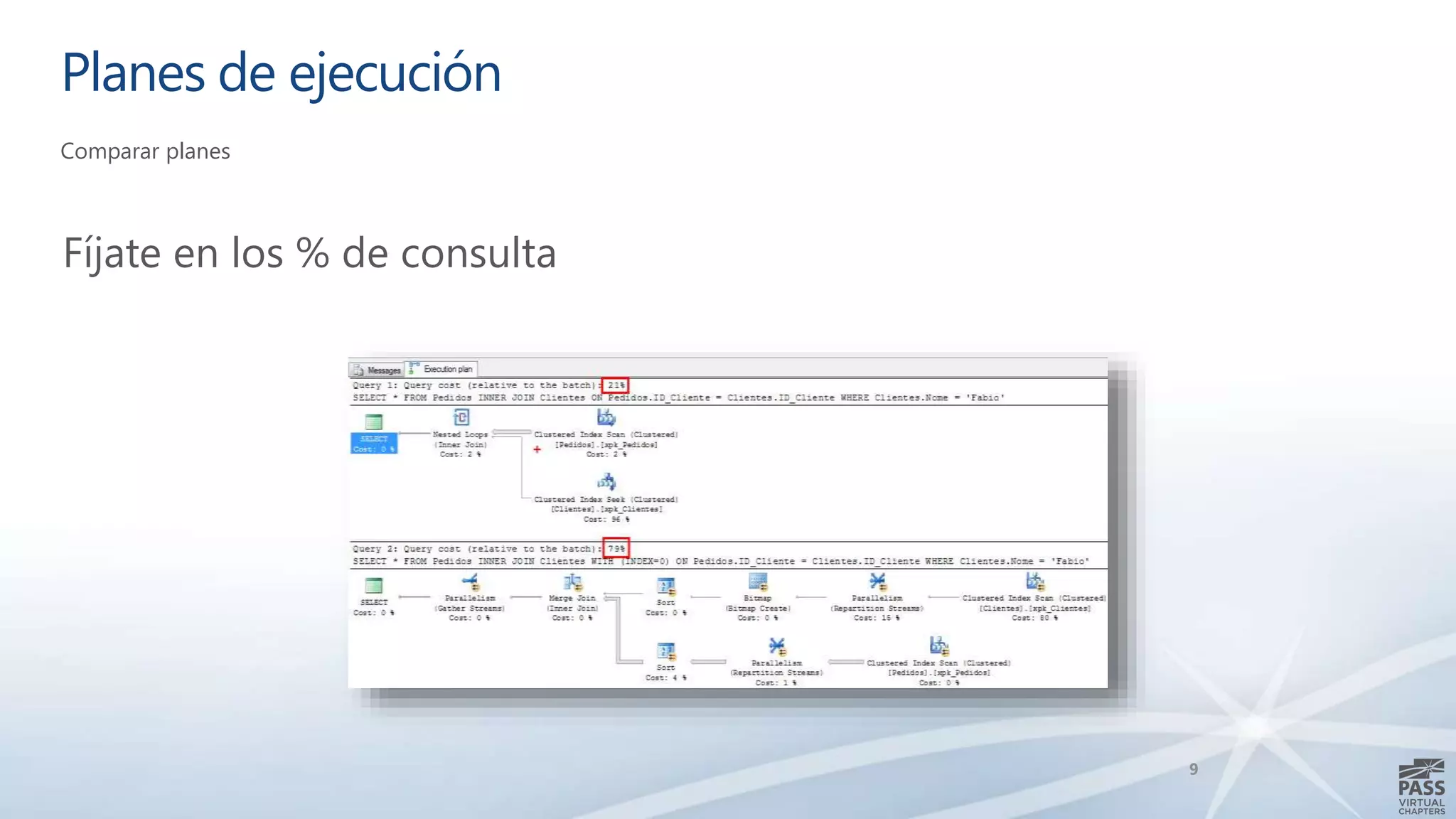
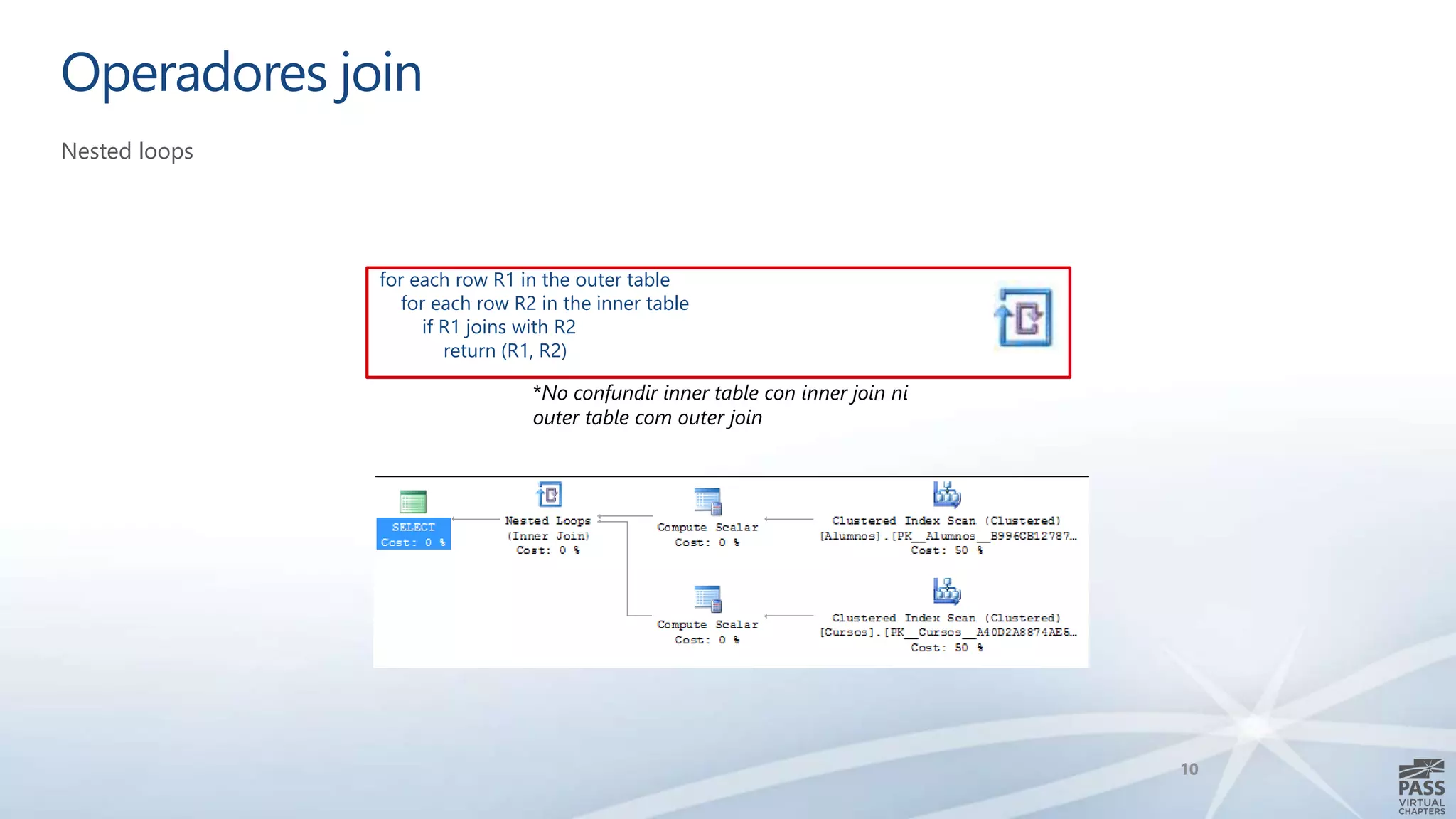
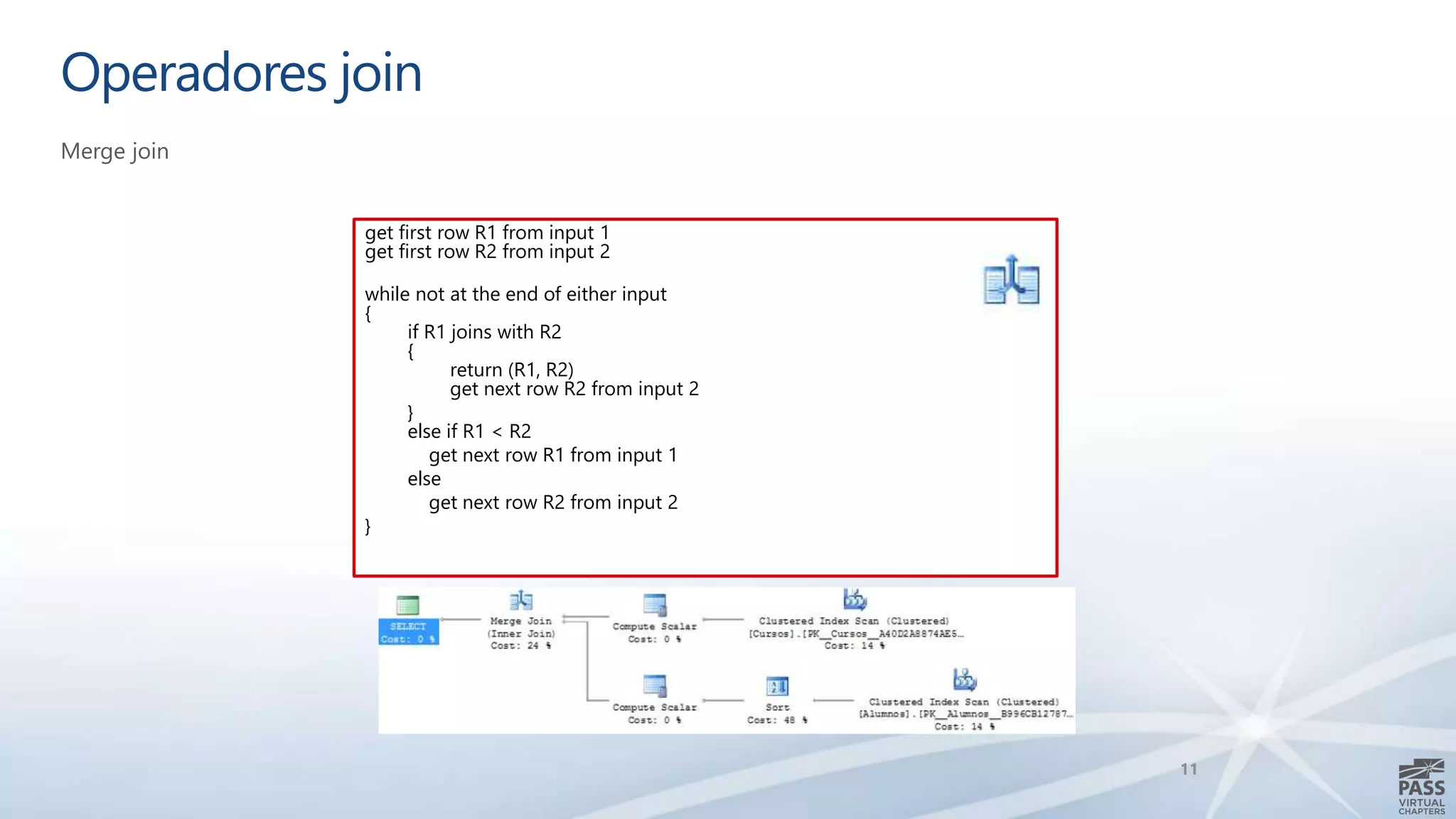

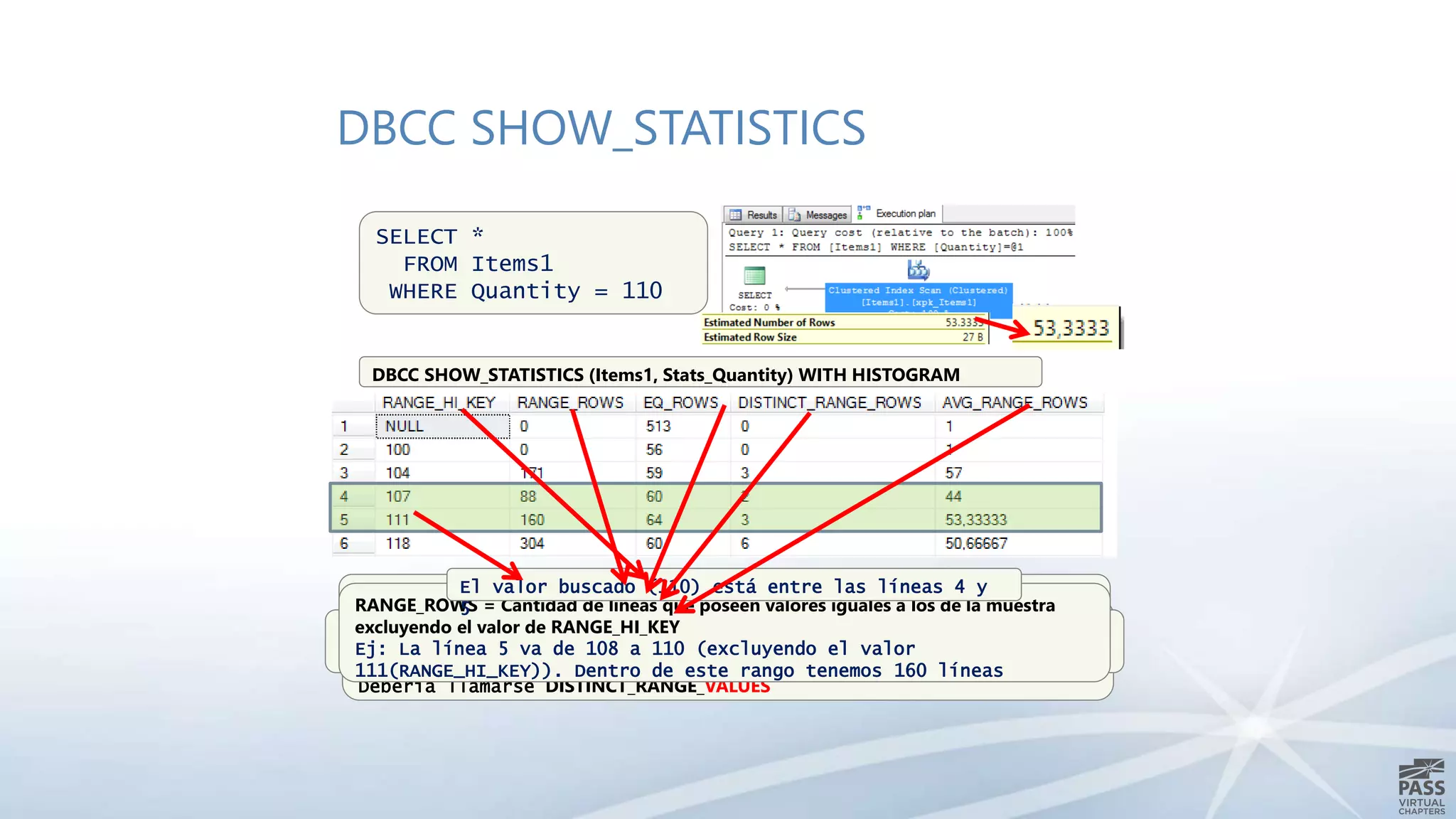



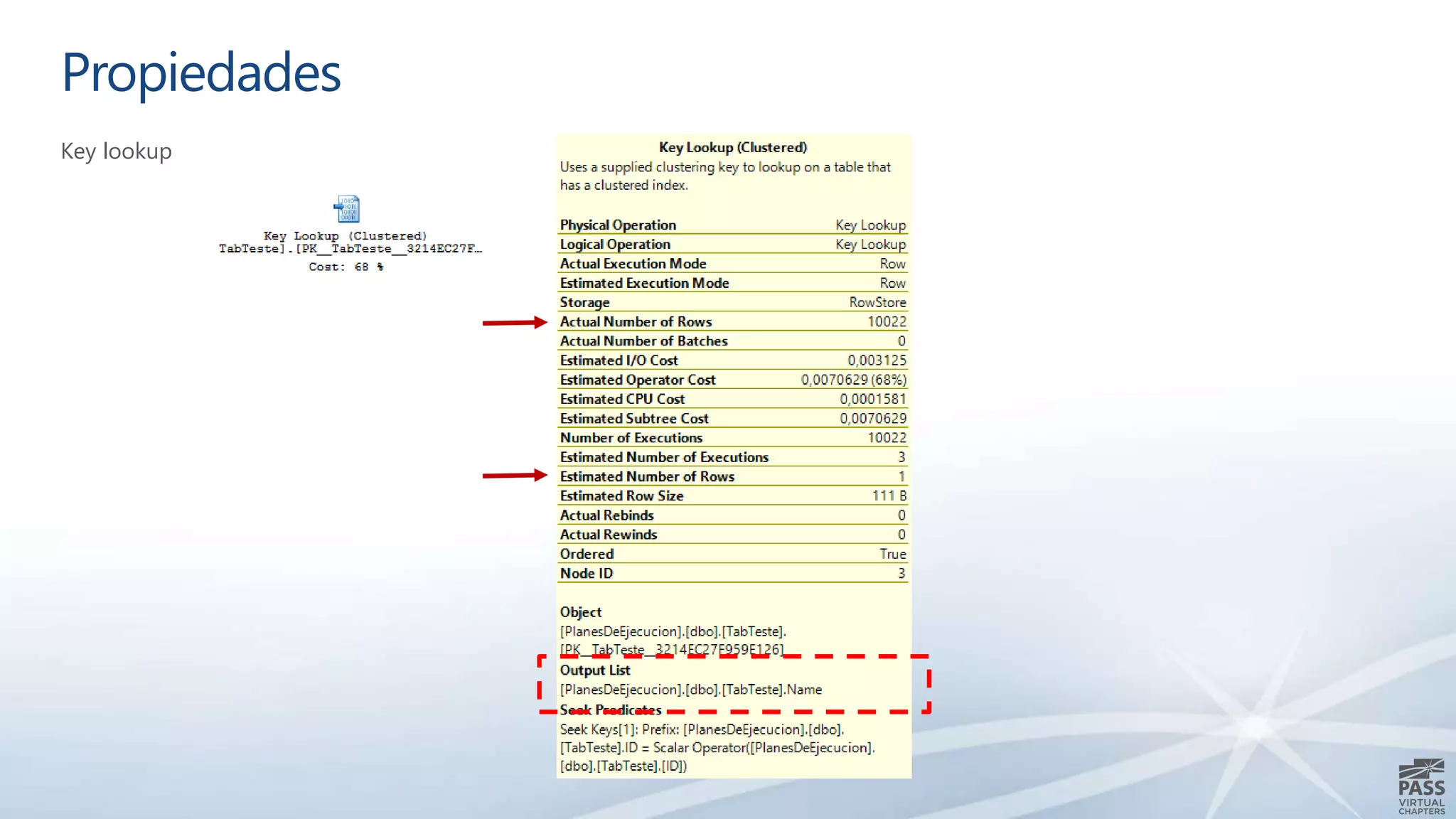



El documento aborda la interpretación de planes de ejecución en SQL Server, enfatizando la importancia de comprender cómo se generan y procesan las consultas para optimizar su rendimiento. Se discuten diferentes tipos de operadores de unión y se proporcionan ejemplos prácticos para facilitar su comprensión. Además, se comparte una agenda que incluye la generación de planes, el procesamiento lógico y la visualización de planes de ejecución.




































































































