Descargar para leer sin conexión





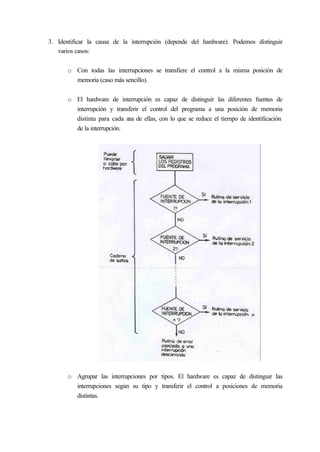

















1) El documento describe las funciones básicas del núcleo de un sistema operativo, incluyendo el manejo de interrupciones, la creación y planificación de procesos, y el soporte de E/S y memoria. 2) Explica que el hardware mínimo necesario incluye un mecanismo de interrupción, protección de memoria, y modos de operación de usuario y núcleo. 3) Detalla los tipos de interrupciones y cómo el manipulador de interrupciones las gestiona, salvando el contexto y transfiriendo el control




















































