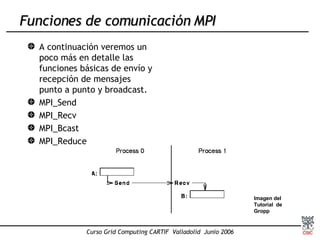
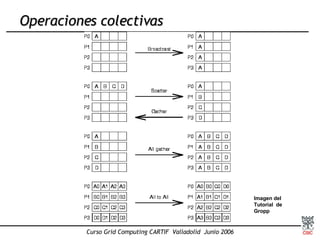
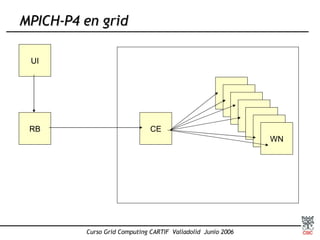
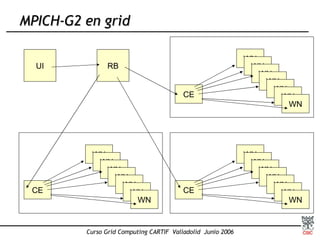
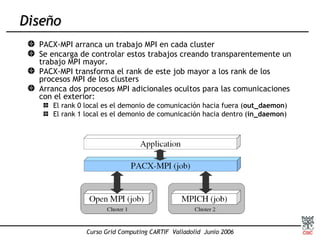
Este documento presenta una introducción a MPI (Message Passing Interface), el estándar más extendido para programación paralela mediante paso de mensajes. Explica conceptos clave como computación paralela, modelo de paso de mensajes, funciones básicas de MPI como Send, Recv y Bcast, y tipos de comunicación punto a punto y colectiva. También describe implementaciones como MPICH y su uso para compilar, ejecutar programas MPI y realizar comunicaciones entre procesos.


























![Ejemplo MPI_Send/MPI_Recv char msg[100]; if(my_rank==0) { sprintf( msg ,"\n\n\t Esto es un mensaje del proceso %d al proceso %d",source,dest); MPI_Send(msg,100,MPI_CHAR,dest,TAG,MPI_COMM_WORLD); printf("\n Mensaje enviado a %d",dest); } else if(my_rank==1) { MPI_Recv(msg,100,MPI_CHAR,source,TAG,MPI_COMM_WORLD,&status); printf("\n Mensaje recibido en %d",dest); printf(msg); }](https://image.slidesharecdn.com/intro-mpi-120343798951044-5/85/Intro-Mpi-28-320.jpg)





![Ejemplo BroadCast Char msg[100]; if(my_rank==source) { sprintf(msg,"\n Esto es un mensaje del proceso %d a todos los demás",sourc e); MPI_Bcast(msg,100,MPI_CHAR,source,MPI_COMM_WORLD); printf("\n Mensaje enviado a todos desde %d",source); } else { MPI_Bcast(msg,100,MPI_CHAR,source,MPI_COMM_WORLD); printf("\n Mensaje recibido en %d desde %d",my_rank,source); printf(msg); }](https://image.slidesharecdn.com/intro-mpi-120343798951044-5/85/Intro-Mpi-35-320.jpg)




















































![What is [Open] MPI?](https://cdn.slidesharecdn.com/ss_thumbnails/test-1230829557420508-1-thumbnail.jpg?width=640&height=640&fit=bounds)































