Descargar como ODP, PPTX




![Ejemplo 2: Expresiones regulares
Dominio: Buscar y extraer patrones de texto
dentro de otros textos.
[A-Za-z_][A-Za-z0-9_]*](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-5-2048.jpg)






















![Una gramática
Program --> Begin line+ End
line --> id num
id --> [A-Za-z][A-Za-z0-9]*
num --> [0-9]+](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-29-2048.jpg)
![Otra gramática
Program --> Begin lines End
lines → line+
line --> id num
id --> [A-Za-z][A-Za-z0-9]*
num --> [0-9]+](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-30-2048.jpg)

![Símbolos especiales
● | Representa alternativas, a|b significa que
se puede generar a o b
● * Significa repetición de cero o más
● + Significa repetición de uno o más
● ? Opcional (uno o cero)
● [a-z] Rango de caracteres
[0-9] se podría representar como 0|1|2|3|4|5|6|8|9](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-33-2048.jpg)



![Lista de Tokens
Token = namedtuple('Token', ['kind', 'value'])
buffer = [
Token('BEGIN', 'Begin'),
Token('ID', 'Bob'),
Token('NUM', 12),
Token('ID', 'Alice'),
Token('NUM', 26),
Token('END', 'End'),
]
pos = 0](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-37-2048.jpg)
![Función auxiliar reduce
def consume(token):
global buffer, pos
tk = buffer[pos]
if tk.kind != token:
raise ParserError(...)
pos += 1
return True](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-38-2048.jpg)


![Función line
def line():
global buffer, pos
tk = buffer[pos]
if tk.kind == 'ID':
pos += 1
tk = buffer[pos]
if tk.kind == 'NUM':
pos += 1
else:
raise ParserError(...)
return True
return False](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-41-2048.jpg)












![Ejecutemos el parser
['Begin', 'Bob', '12', 'Alice', '26', 'End']](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-54-2048.jpg)

![¡Tranquilidad!
● Nosotros podemos incluir las acciones que
queramos, asociadas a los elementos que
constituyen las reglas.
● Como no hay acciones, el resultado es una
simple lista de tokens.
['Begin', 'Bob', '12', 'Alice', '26', 'End']](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-56-2048.jpg)
![Añadamos acciones
begin = Suppress(Literal('Begin'))
end = Suppress(Literal('End'))
num = Word(nums)
op = Literal('+') | Literal('-')
id = Word(alphas)
line = Group(id + num + Optional(op + num))
lines = OneOrMore(line)
program = begin + lines + end
num.setParseAction(lambda p: int(p[0]))](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-57-2048.jpg)
![Esto está mejor
Ejecutemos ejemplo_pyparsing_2.py:
['Begin', ['Bob', 12], ['Alice', 26], 'End']](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-58-2048.jpg)
![Las acciones nos permiten construir
nuestro modelo (o un AST)
def parse_line(s, loc, toks):
items = toks[0]
if len(items) == 4:
op = items[2]
delta = items[3]
if op == '+':
v = items[1] + delta
elif op == '-':
v = items[1] - delta
return (items[0], v)
else:
return tuple(items)
line.setParseAction(parse_line)](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-59-2048.jpg)
![Mucho mejor
Ejecutemos ejemplo_pyparsing_3.py
ejemplo3.txt:
[('Bob', 12), ('Alice', 26), ('Charles', 55), ('Daniel', 29)]
Begin
Bob 12
Alice 26
Charles 33+22
Daniel 72-43
End](https://image.slidesharecdn.com/presentacindslintro-151124180611-lva1-app6891/75/Introduccion-a-DSL-Lenguajes-Especificos-de-Dominios-con-Python-60-2048.jpg)










Un DSL (lenguaje específico de dominio) se utiliza para resolver problemas específicos de manera más sencilla que un lenguaje de propósito general. Ejemplos de DSL incluyen SQL para bases de datos, expresiones regulares para buscar patrones en texto y CSS para la apariencia de elementos HTML. La creación de un DSL puede ser interna, expandiendo un lenguaje existente, o externa, donde se desarrolla un lenguaje completamente nuevo con su propia gramática y parser.
Definición de un Lenguaje Específico de Dominio (DSL) y su objetivo de resolver problemas específicos de manera más sencilla.
Presentación de ejemplos de DSL como SQL, expresiones regulares y CSS, mostrando sus dominios de aplicación.
Características que definen un DSL, ventajas como legibilidad y flexibilidad, y su uso por personal no técnico.
Descripción de tipos de DSL, incluyendo internos y externos, y características particulares de cada uno.
Fases de la estructura de un lenguaje: scanner, lexer, parser, y generación o ejecución de código.
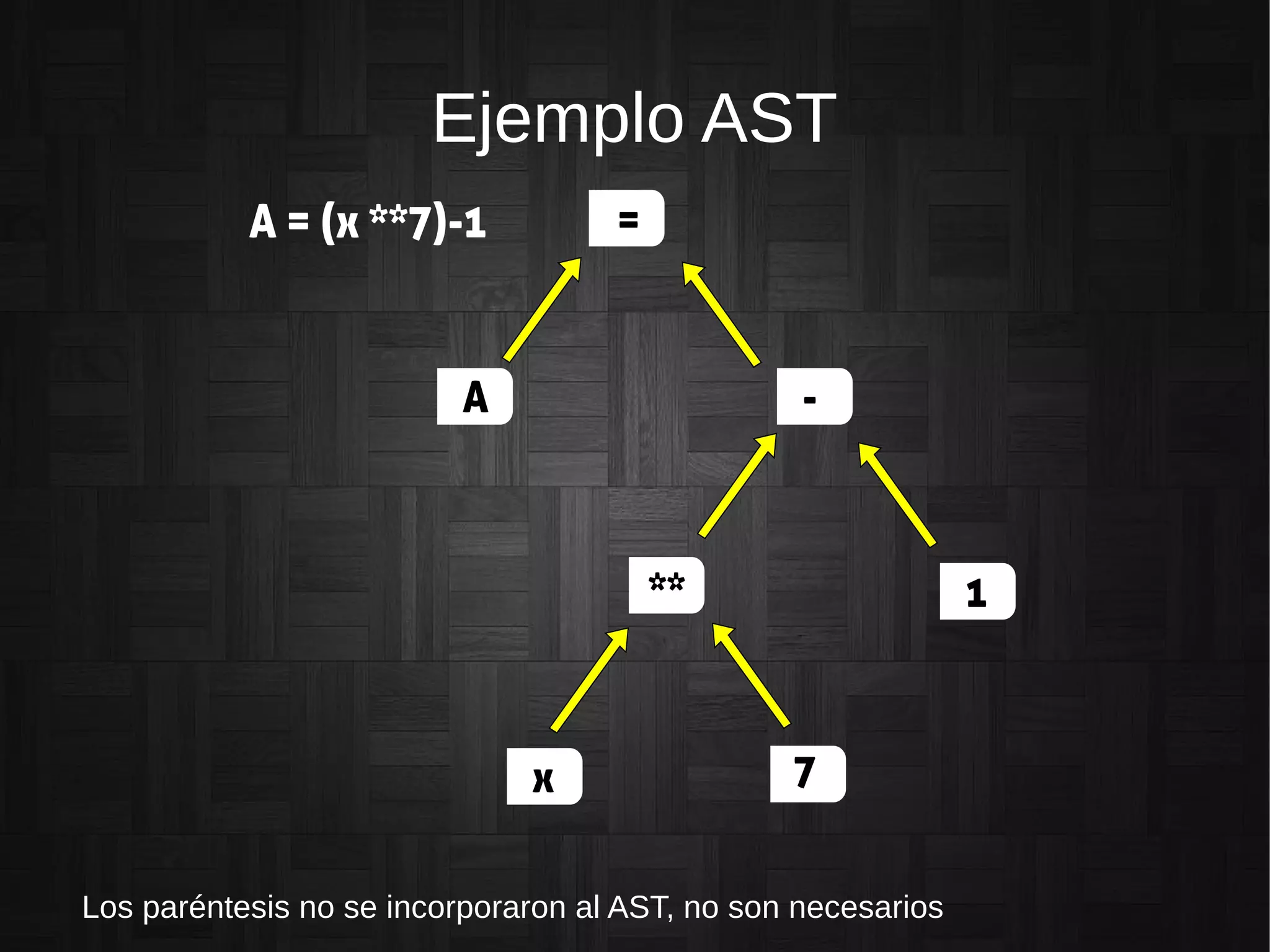
La función de las gramáticas en el parsing: detectar la entrada correcta y organizar tokens en un AST.
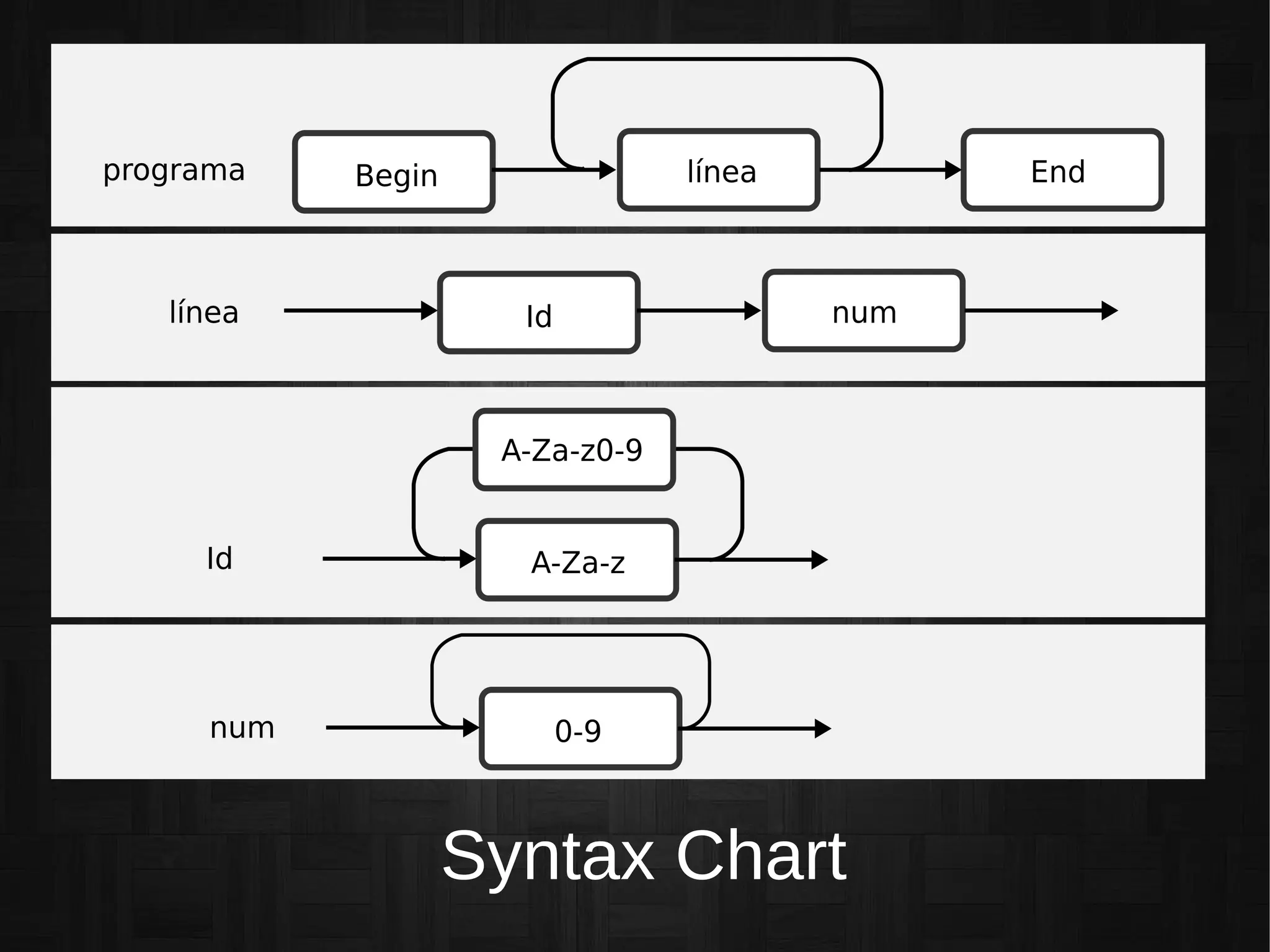
Presentación de una gramática simple empleada para un lenguaje ficticio, mostrando su estructura y reglas.
Descripción de parsers, especialmente recursivo descendente y LR, junto con sus características y procesos automáticos.
Lista de generadores de parsers destacando Lex, Yacc, Flex, Bison y herramientas específicas para Python.
Demostración de cómo usar Pyparsing para crear un parser visualizando y ejecutando una gramática definida.
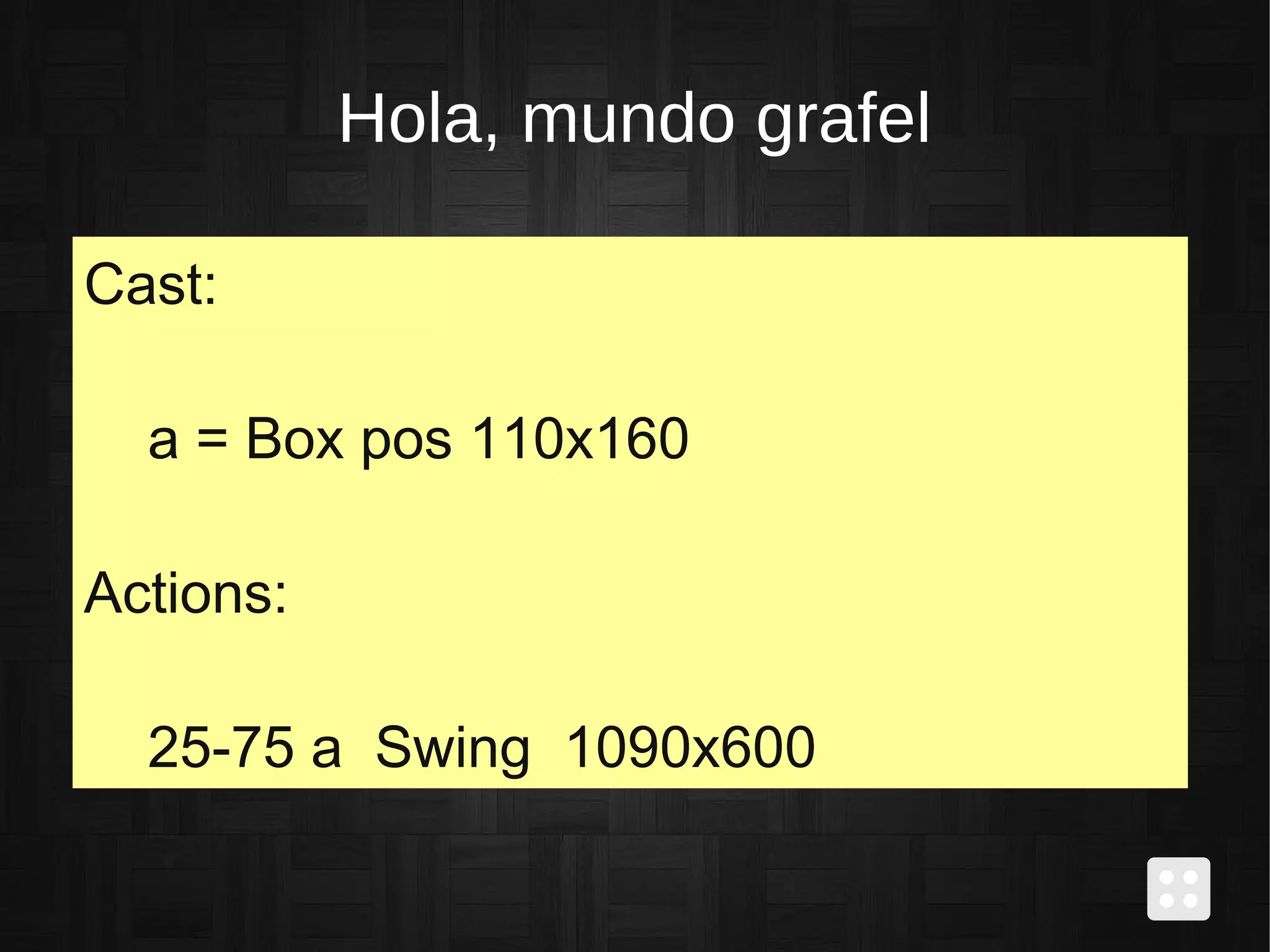
Caso de estudio sobre Grafel, un DSL para animaciones, incluyendo ejemplos de sintaxis y recomendaciones de lectura.












































































![Se deben realizar liquidaciones GASTOS GENERALESDIRECTIVA_017[1].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/directiva0171-251204151453-363e228f-thumbnail.jpg?width=640&height=640&fit=bounds)








