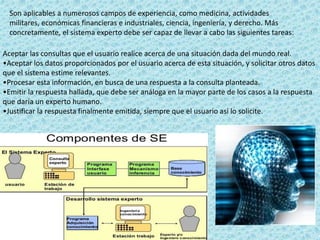
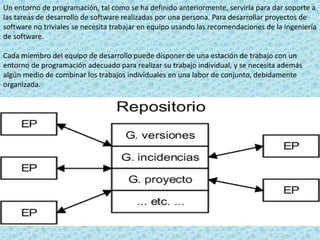
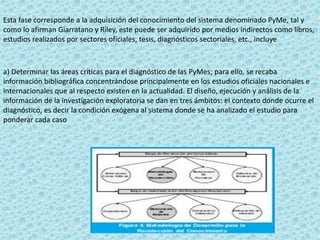
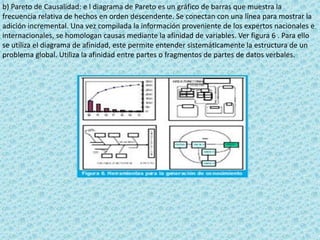
El documento describe los sistemas expertos y sus características. Explica que un sistema experto es un sistema informático que puede emular las habilidades de un experto humano en un área de conocimiento especializado al resolver preguntas complejas usando una gran base de datos y reglas de decisión. También describe las funciones clave de un sistema experto como aceptar consultas y datos de usuarios, procesar la información para responder a consultas, y justificar sus respuestas.