Descargado 26 veces








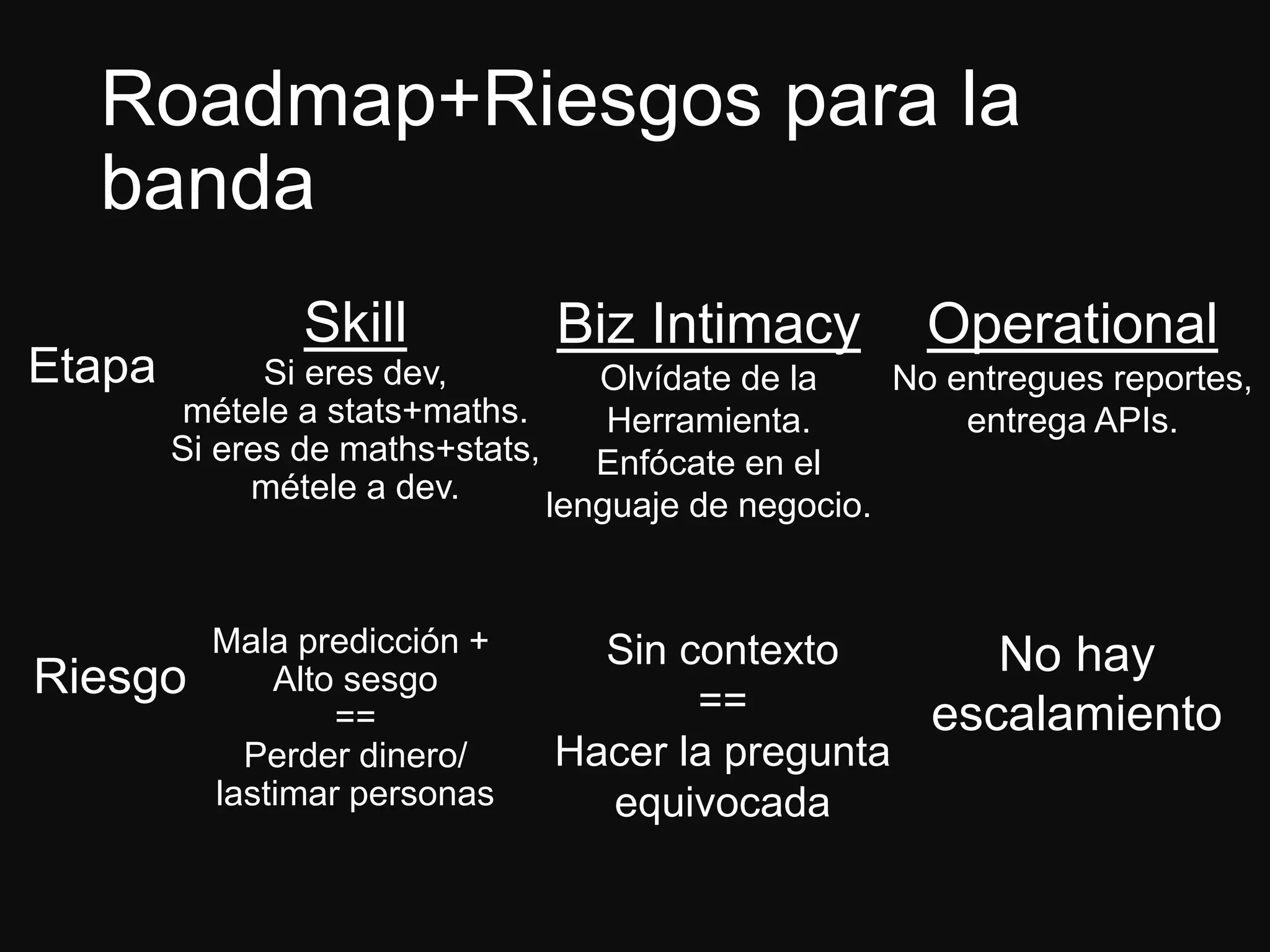
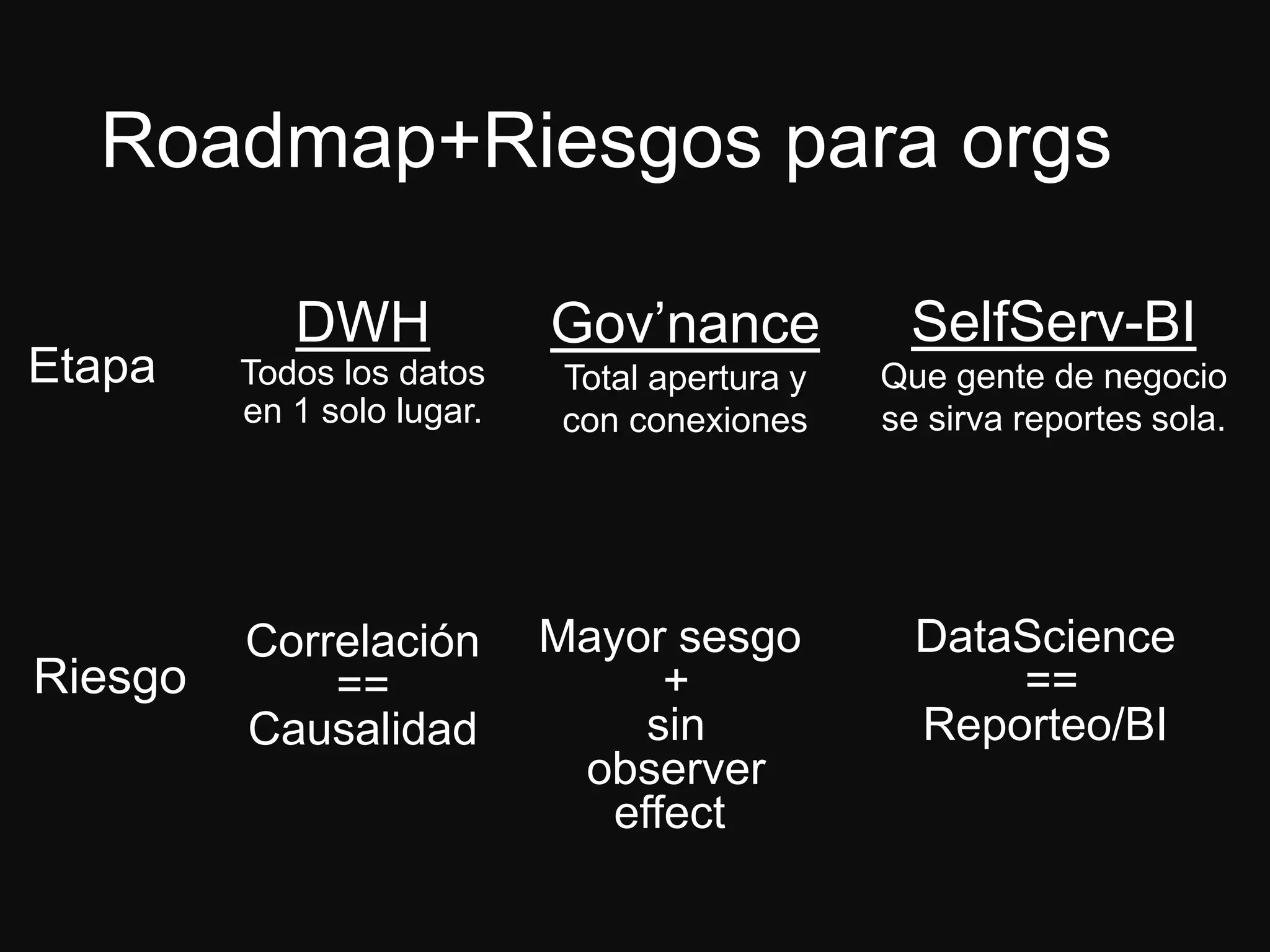

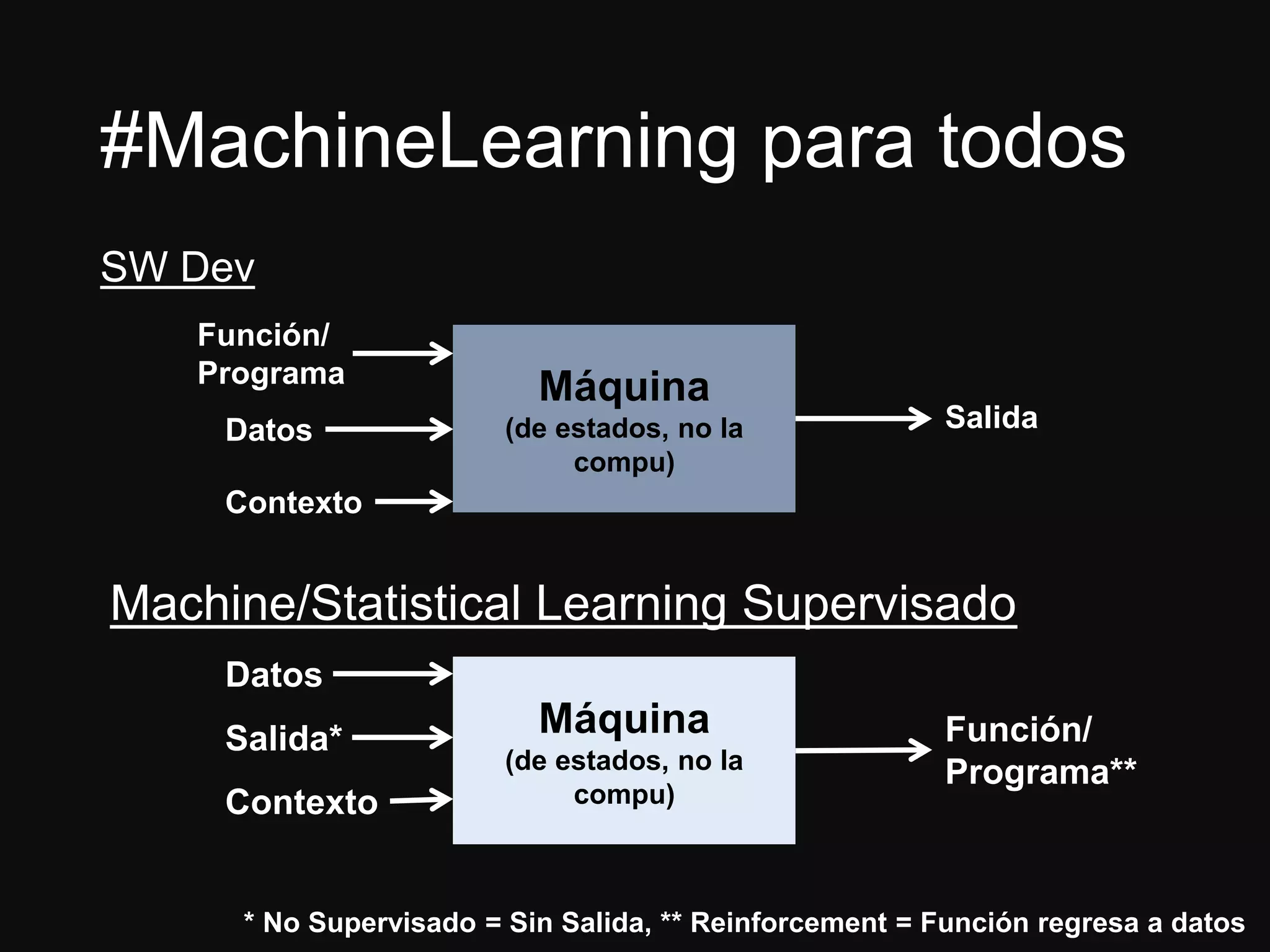
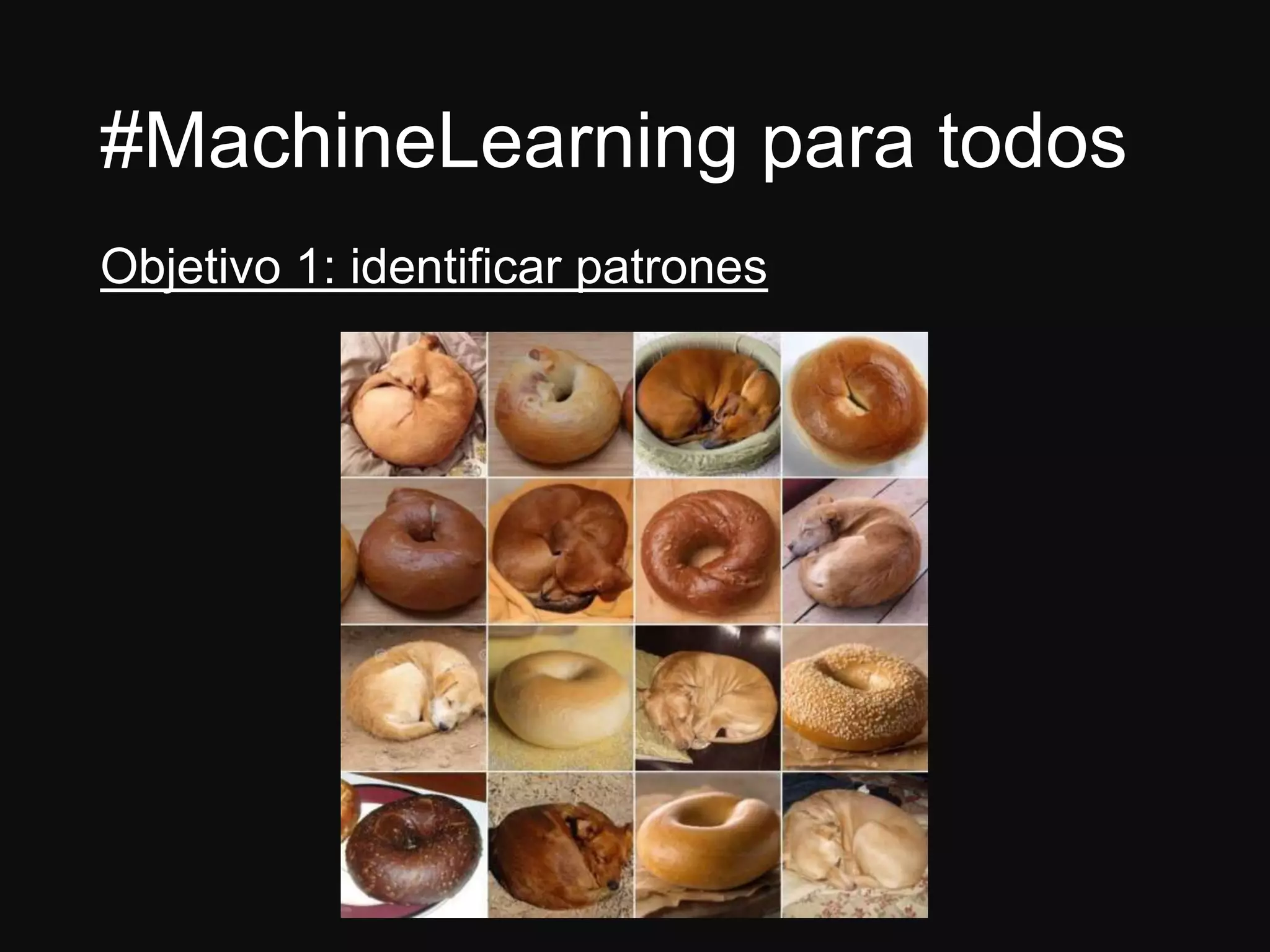
























El documento presenta a Jesús Ramos, ingeniero de software y econometrista con experiencia en machine learning, abordando sus logros y perspectivas sobre la analítica en organizaciones. Discute la importancia de la preparación en matemáticas y estadísticas para desarrolladores interesados en machine learning, así como los riesgos asociados con la mala implementación de modelos. Además, resalta diversas aplicaciones de machine learning en la industria y concluye con recomendaciones para quienes buscan iniciarse en este campo.

























































