Descargar para leer sin conexión







![ {$mode objfpc}{$H+}
interface
uses
Classes, SysUtils;
const
num=20;
type
{ TBusquedas }
TBusquedas=class
private
vector:array[1..num] of string;
public](https://image.slidesharecdn.com/sliders-120320110242-phpapp01/85/metodos-de-busqueda-8-320.jpg)




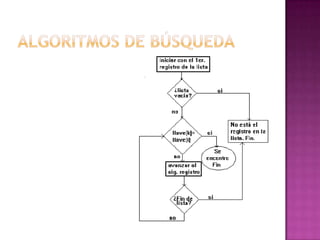


Este documento describe diferentes métodos de búsqueda como la búsqueda secuencial y binaria para encontrar datos en vectores y archivos. También presenta la implementación de una clase lógica TBusquedas que incluye métodos para realizar búsquedas secuenciales y binarias. Además, proporciona instrucciones sobre cómo realizar búsquedas efectivas en un sistema considerando factores como la capitalización, el uso de comillas para números y frases exactas, y los operadores AND, - y +.


























































