Descargado 46 veces















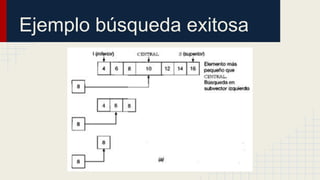
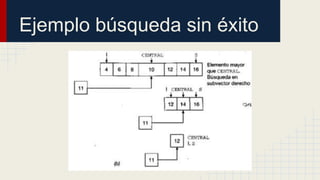





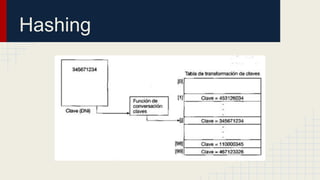










El documento detalla métodos de búsqueda y ordenamiento, incluyendo ejemplos de algoritmos como la búsqueda secuencial, binaria y hashing. Se analizan las ventajas y desventajas de cada método, así como los casos de colisiones en hashing y diferentes técnicas para manejarlas. Incluye ejercicios prácticos para aplicar ordenamientos a listas numéricas y utiliza tablas intermedias para mostrar el proceso.
































































