CheatSheet manejo de datos con dplyr en R
•
1 recomendación•1,765 vistas

Cheat Sheet para el manejo de datos en R con el paquete dplyr

Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a CheatSheet manejo de datos con dplyr en R
Similar a CheatSheet manejo de datos con dplyr en R (20)
Último
Último (17)
CheatSheet manejo de datos con dplyr en R
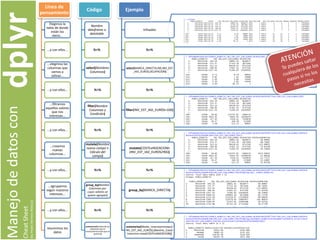
- 1. Línea de pensamiento Elegimos la tabla de donde están los datos... ...y con ellos... ...elegimos las columnas que vamos a utilizar... ...y con ellos... ...filtramos aquellos valores que nos interesan... ...y con ellos... ...creamos nuevas columnas... ...y con ellos... ...agrupamos según nuestros intereses... ...y con ellos... resumimos los datos Código Nombre dataframe o datatable %>% select(Nombres Columnas) %>% filter(Nombre Columnas y Condición) %>% mutate(Nombre nuevo campo = Cálculo del campo) %>% group_by(Nombre Columnas por cuyos valores se quiere agrupar) %>% summarise(Nombre de las cabecerasque se mostrarán=Función quese aplicará) Ejemplo Infoadex %>% select(MARCA_DIRECTA,INS,INV_EST _IAD_EUROS,OCUPACION) %>% filter(INV_EST_IAD_EUROS>100) %>% mutate(COSTExINSERCION= (INV_EST_IAD_EUROS/INS)) %>% group_by(MARCA_DIRECTA) %>% summarise(Media_Inversion=mean(I NV_EST_IAD_EUROS),Maximo_Coste Insercion=max(COSTExINSERCION)) Manejodedatoscon CheatSheet byPedroHerreroPetisco dplyr
- 2. Funciones más usadas para: mutate summarise first • Primer valor de un vector last • Último valor de un vector nth • N-esimo valor de un vector n() • Valores de un vector n_distinct • Valores distintos de un sector Funciones de R base Funciones de dplyr row_number • Numera las filas dense_rank • Ranking de la variable lead • Copia los valores de una columna en la nueva moviéndolos una fila hacia arriba lag • Copia los valores de una columna en la nueva moviéndolos una fila hacia abajo Operadores aritméticos • + Suma; - Resta; * Multiplicación; ^ Exponenciación; / División; %% Resto Operadores de comparación • == Igual; !=Distinto; > Mayor que; < Menor que; >= Mayor o igual; <= Menor o igual Operadores lógicos • & Y; | O; ! No mean • Media median • Mediana var • Varianza sd • Desviación típica sum • Suma de los valores de un vector max • Valor máximo de un vector min • Valor mínimo de un vector select contains • Selecciona las columnas que contiene una cadena de caracteres ends_with • Selecciona las columnas que terminan con una cadena de caracteres starts_with • Selecciona las columnas que empiezan con una cadena de caracteres Ejemplo de uso mutate • Datos %>% mutate(PosicionMasUno=lag(Posicion))) select • Datos %>% select(contains(“Cabecera”)) summarise • Datos %>% summarise(median(Cabecera)) Otros comandos del paquete dplyr: distinct() • Elimina las filas duplicadas slice(a:b) • Elije filas entre a y b sample_n(n) • Extrae una muestra aleatoria de n filas Select(Columna_n;everything()) • Reordena las columnas Datos%>%distinct() • Si se quieren quitar las duplicaciones en base a una columna poner Datos%>%distinct(NombreColumna) Datos%>%slice(10:20) • Selecciona las filas de la 10 a la 20 Datos%>%sample_n(4) • Extrae 4 filas aleatoriamente Datos%>%select(Columna_n,Columna_d,everything()) • Ordena las columnas poniendo primero la Columna_n, después la Columna_d y después el resto de columnas Manejodedatoscon CheatSheet byPedroHerreroPetisco dplyr