Descargar como PDF, PPTX





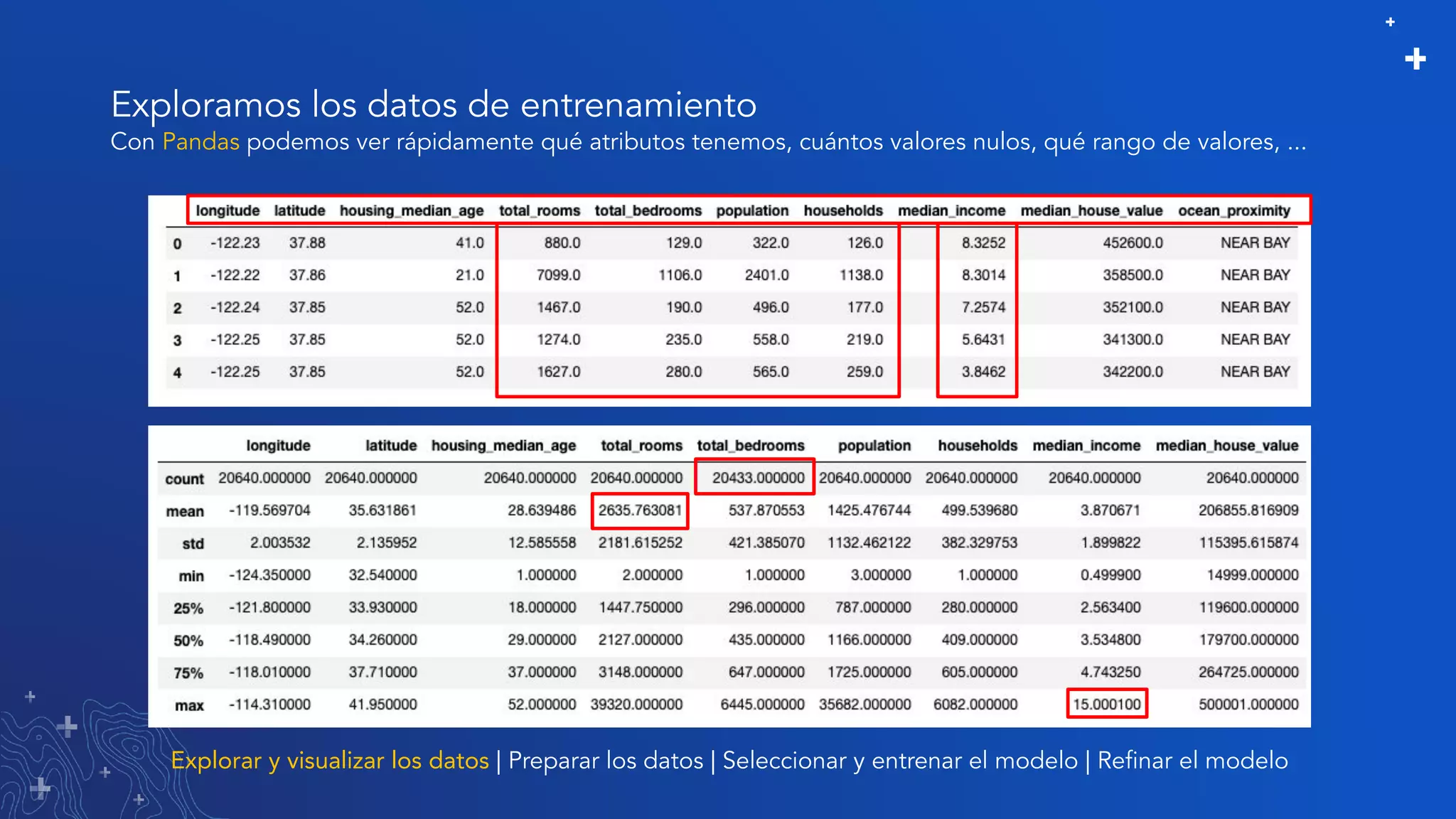
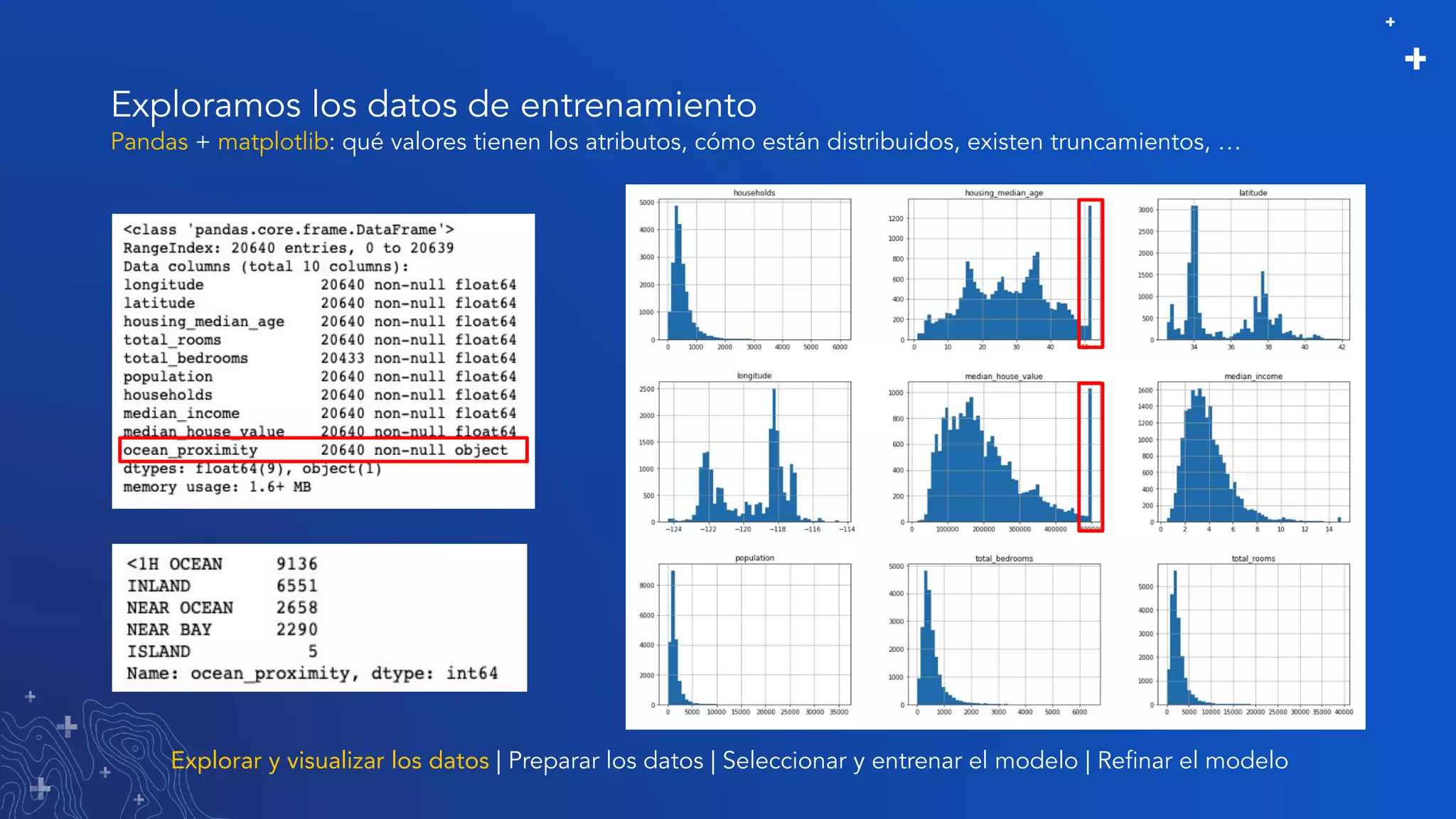
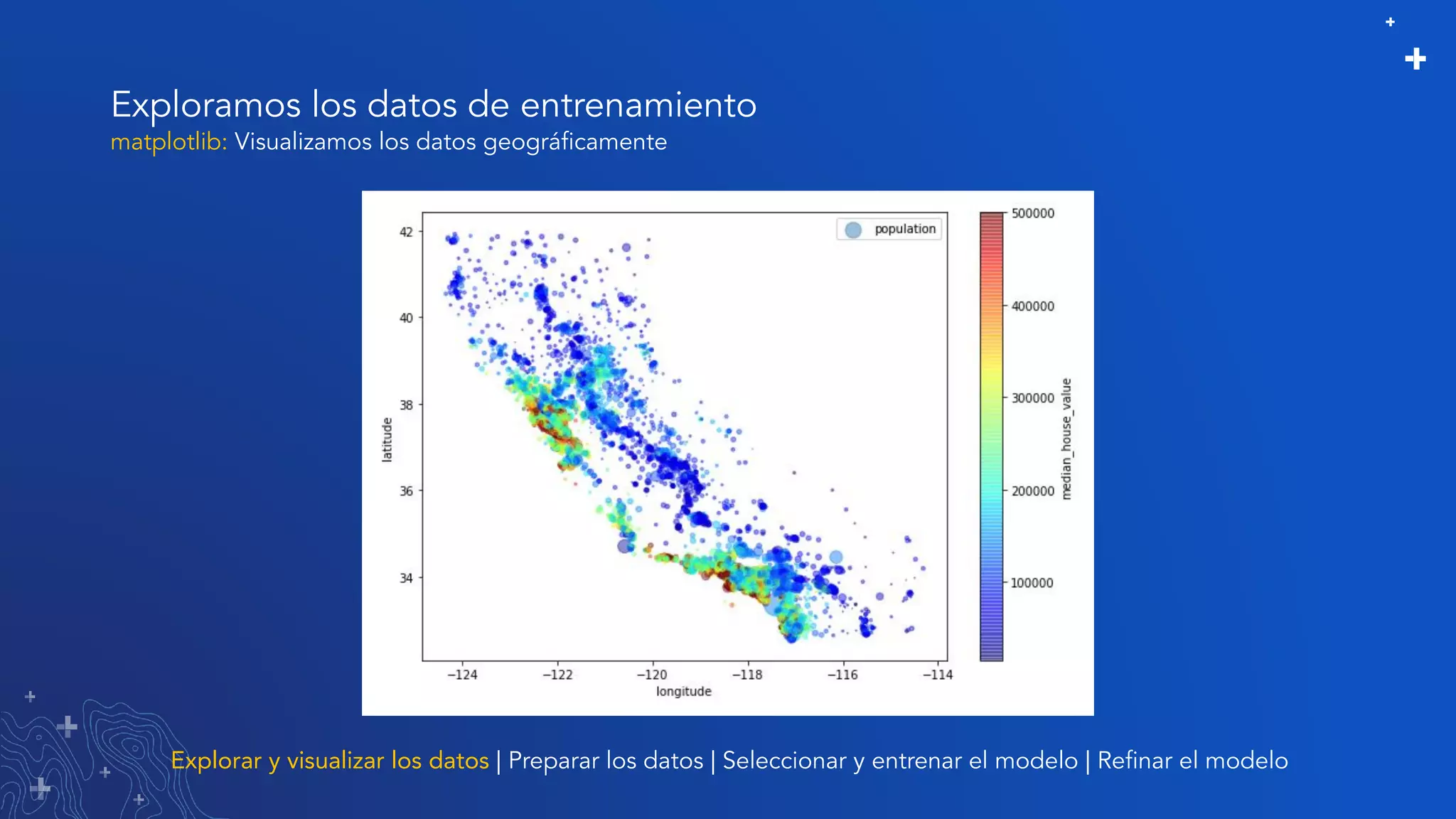

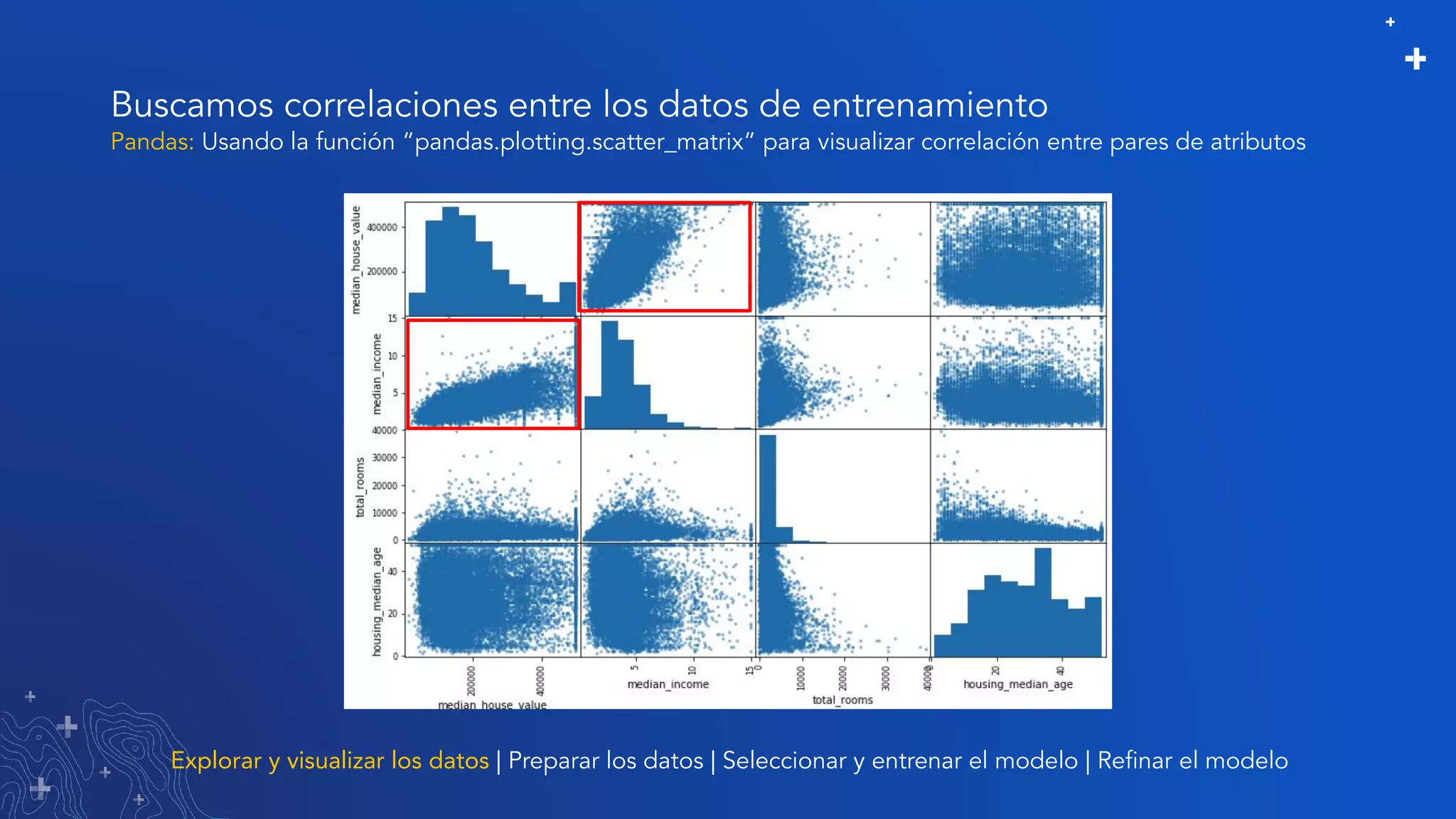


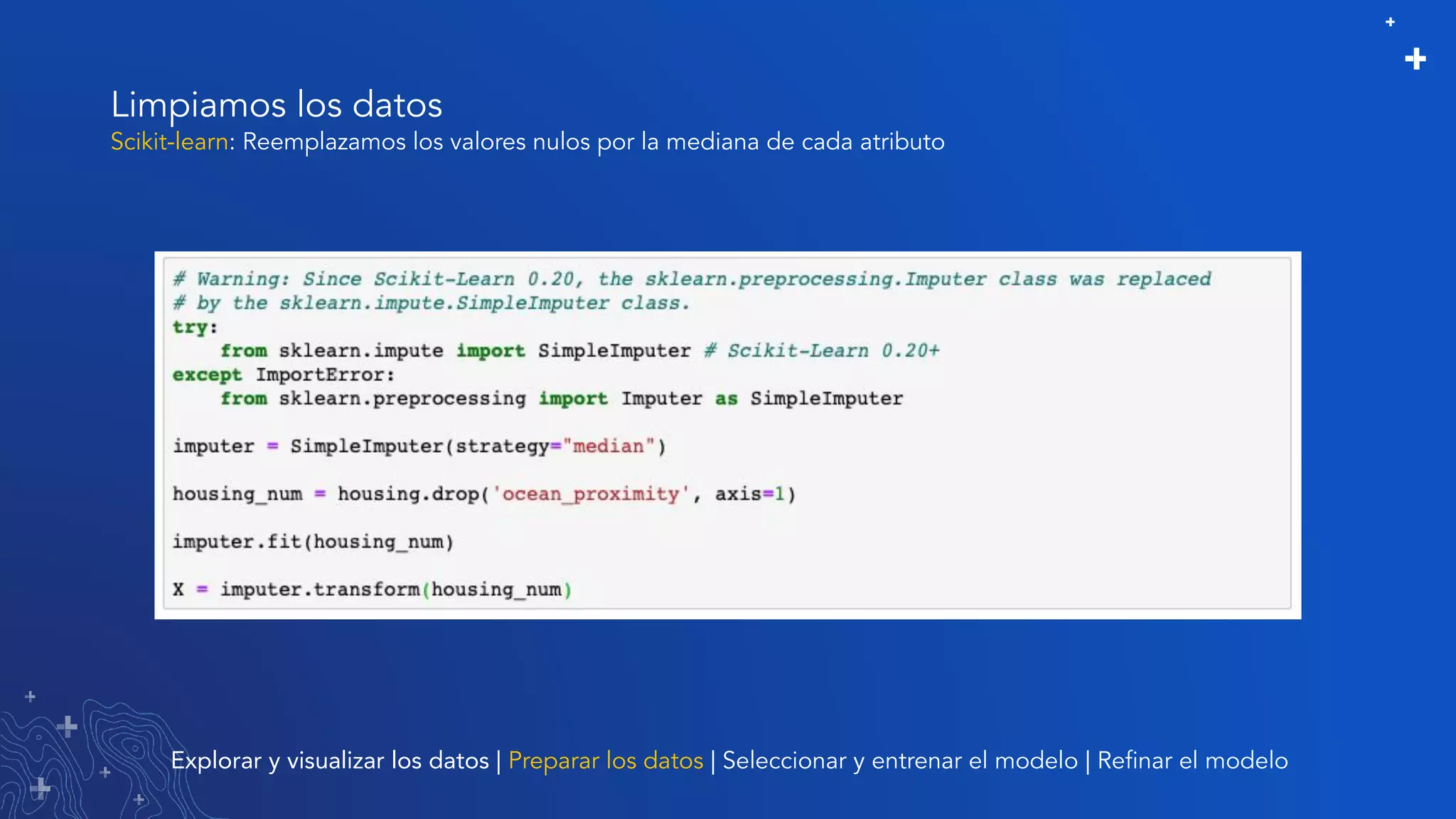
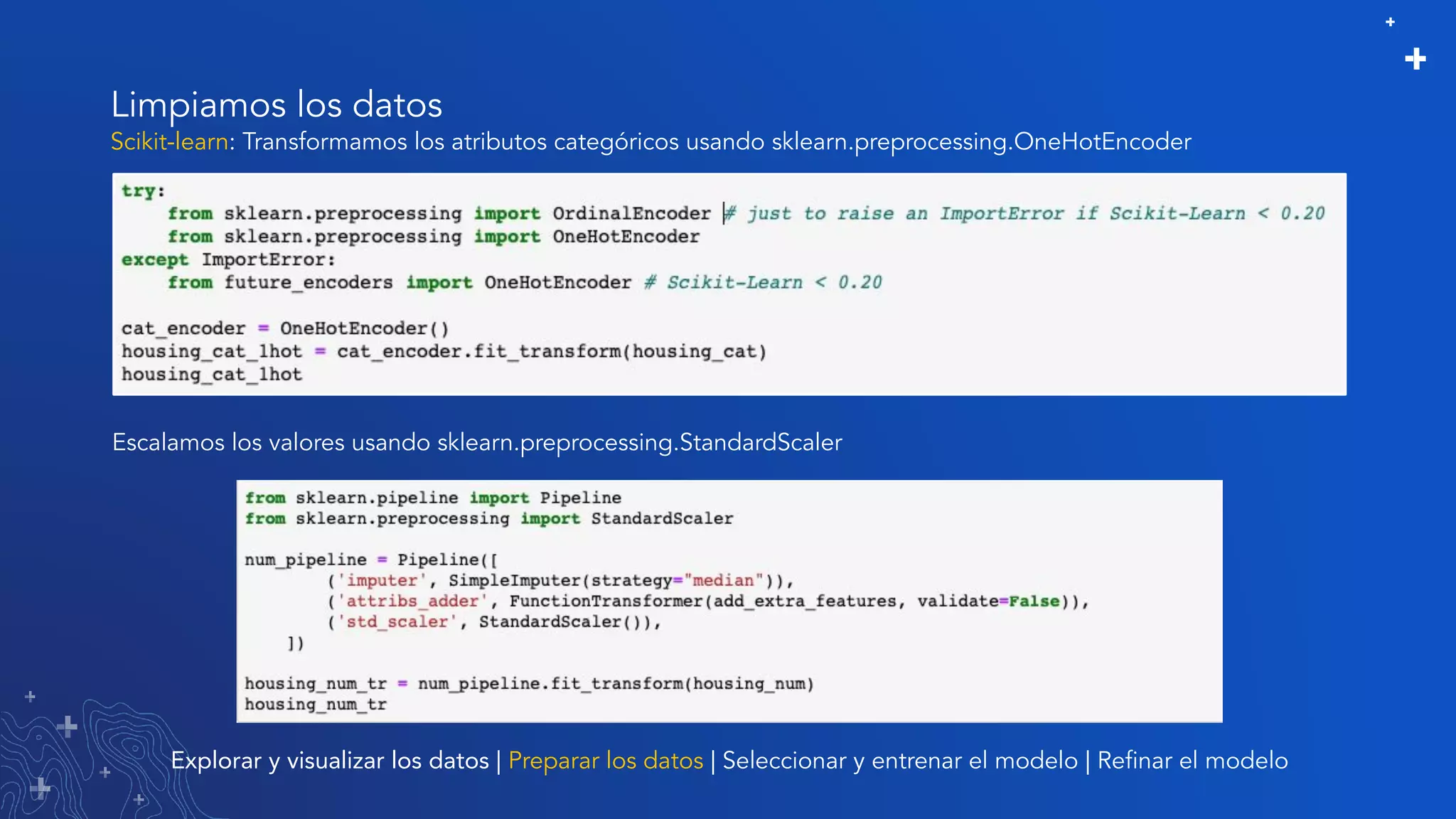


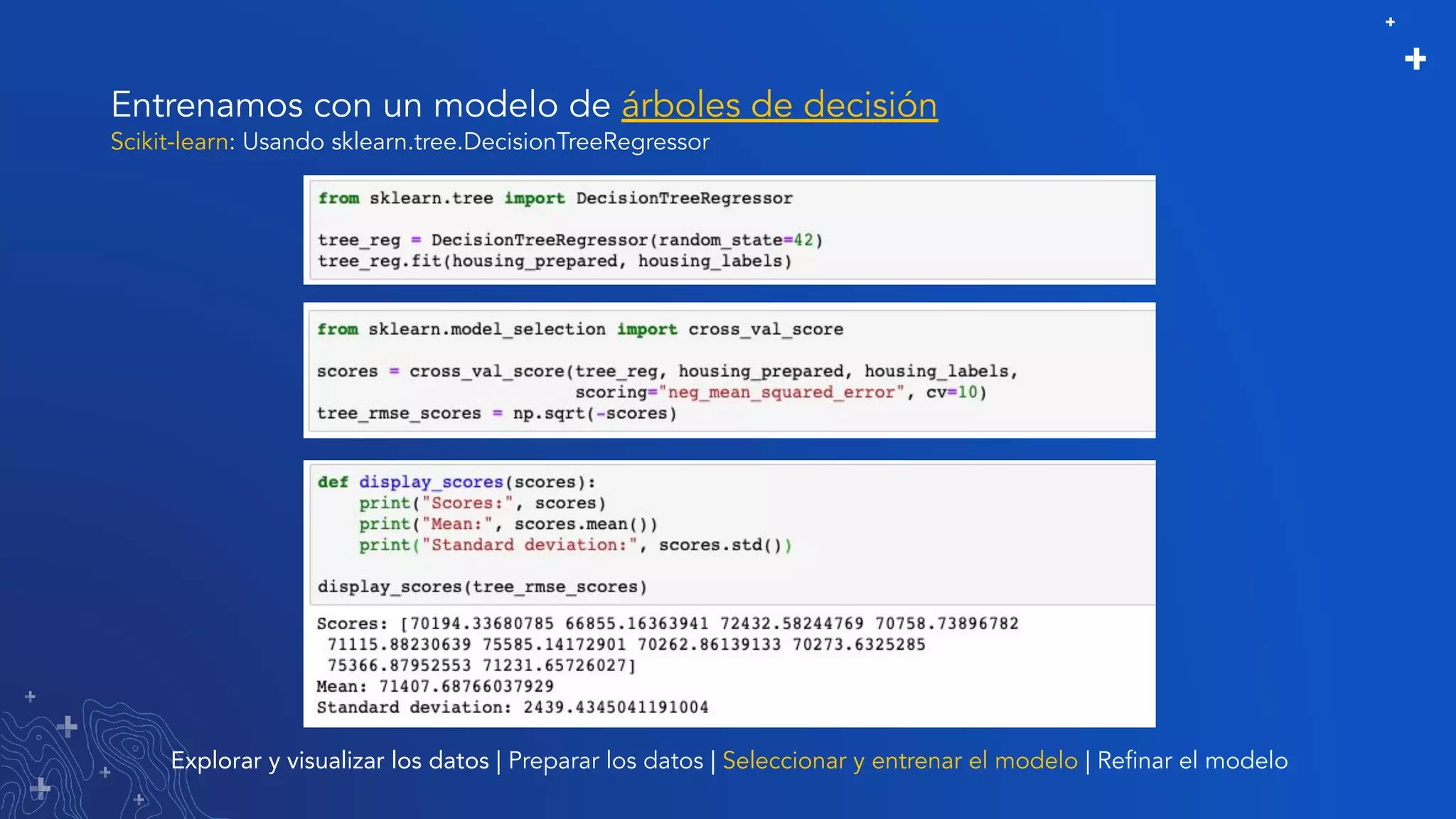
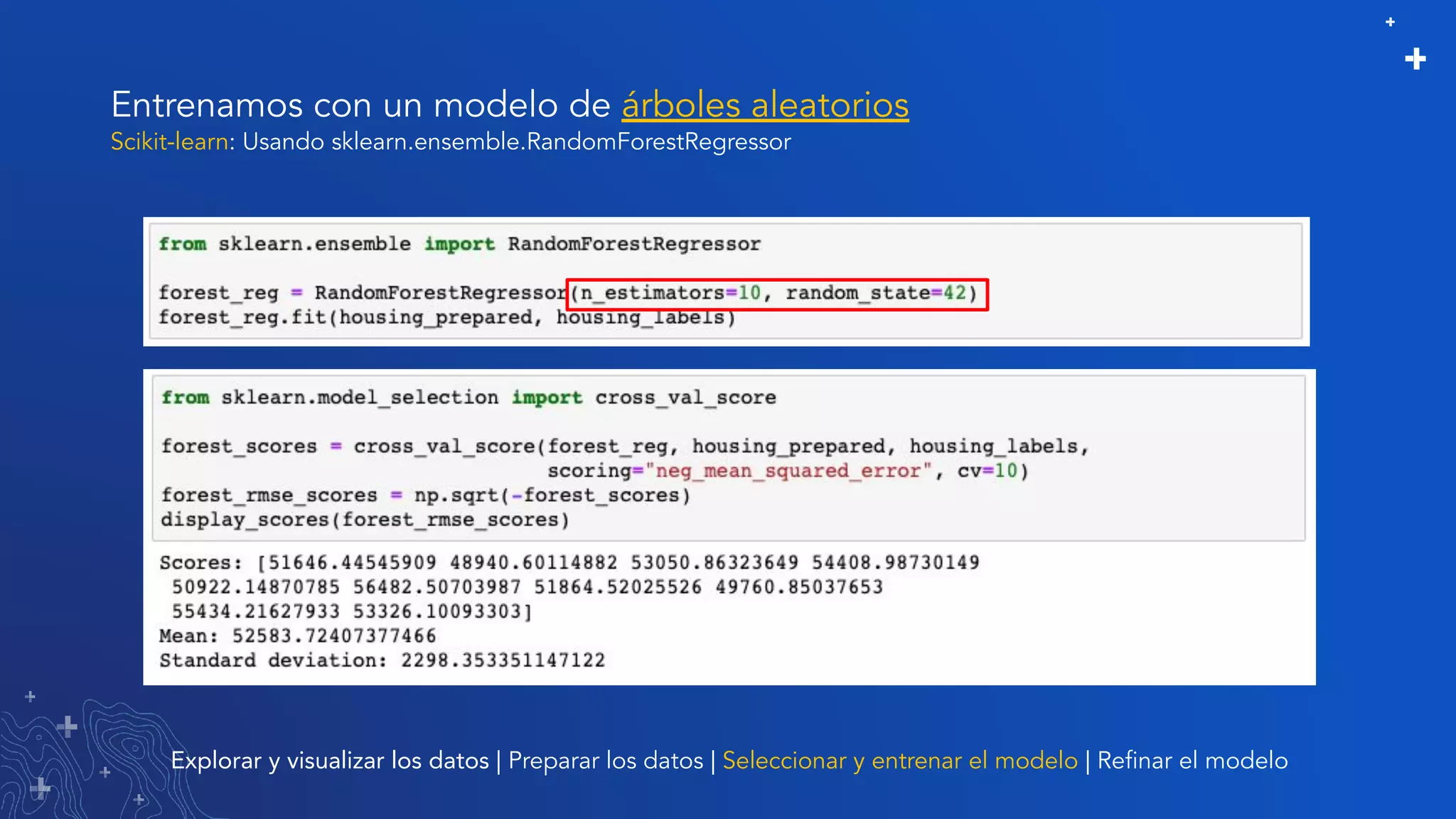

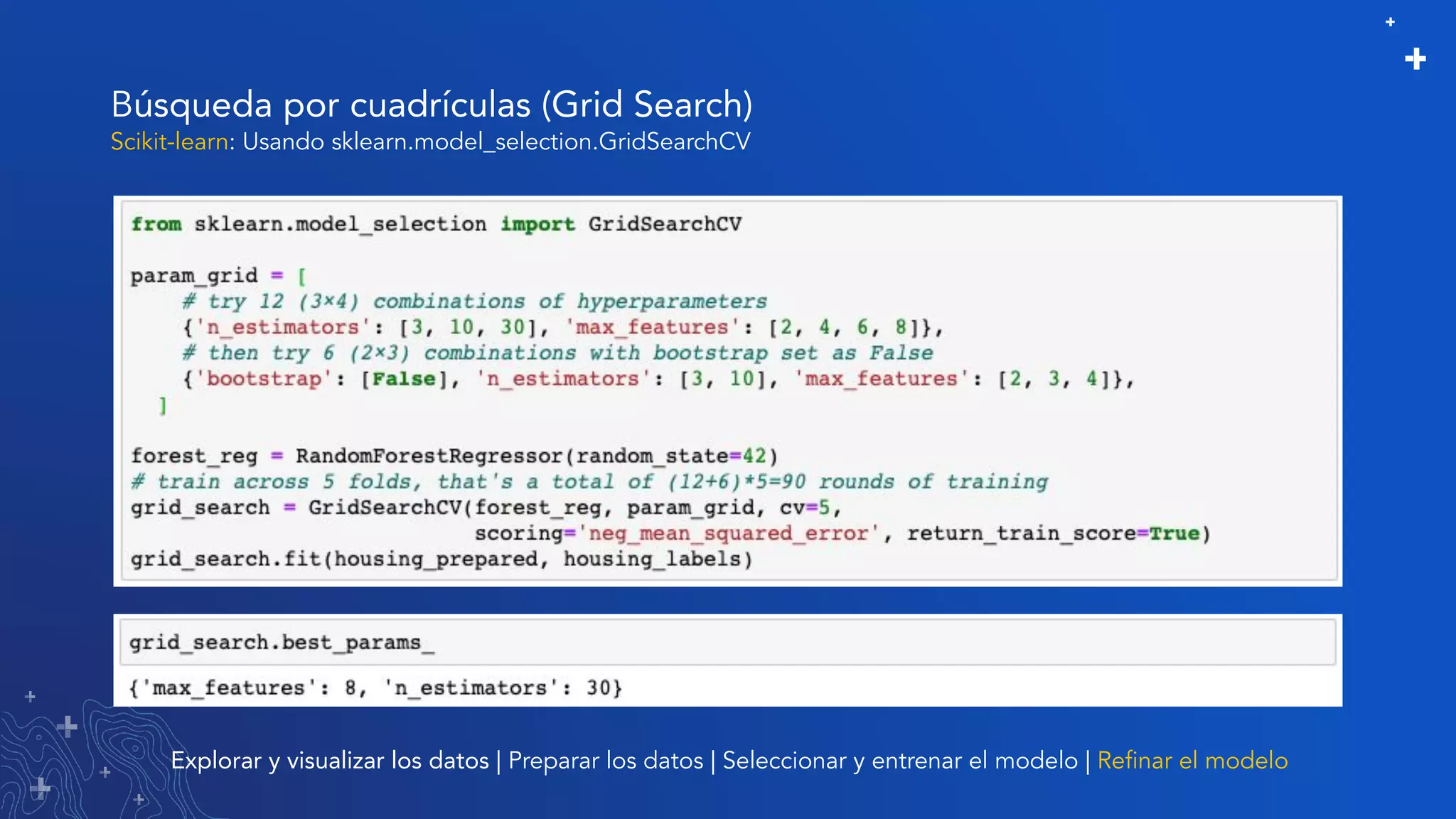
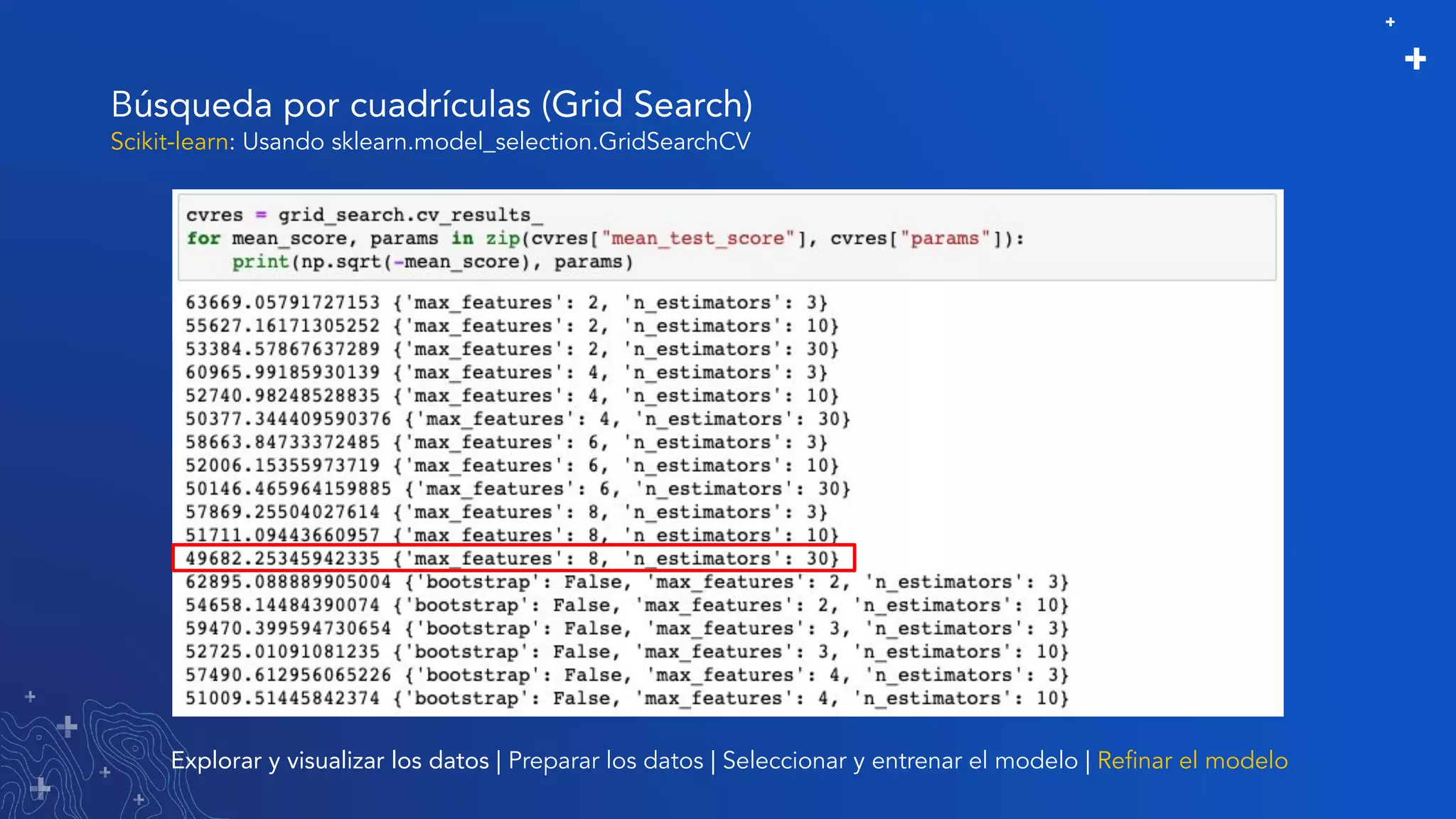
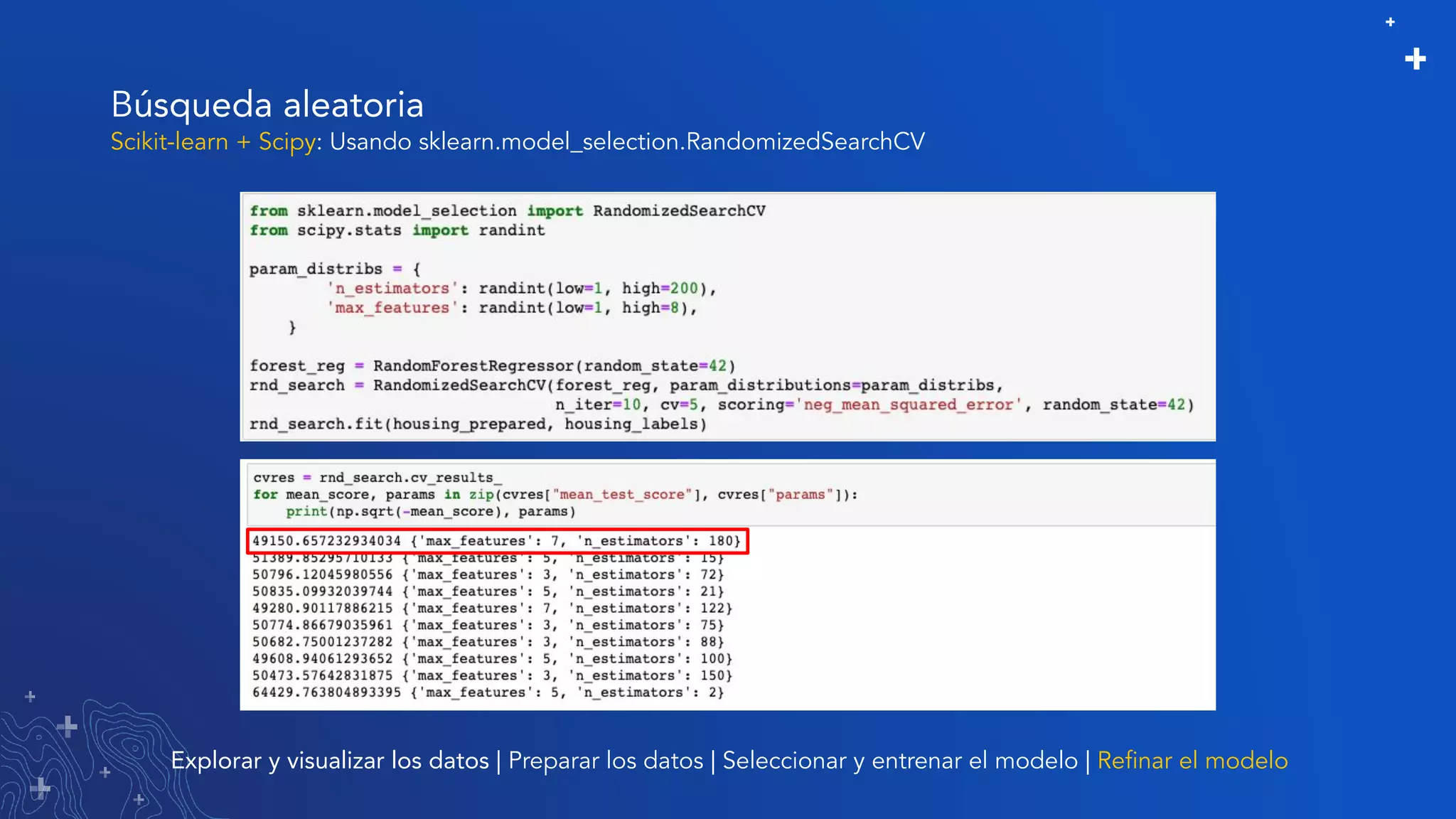
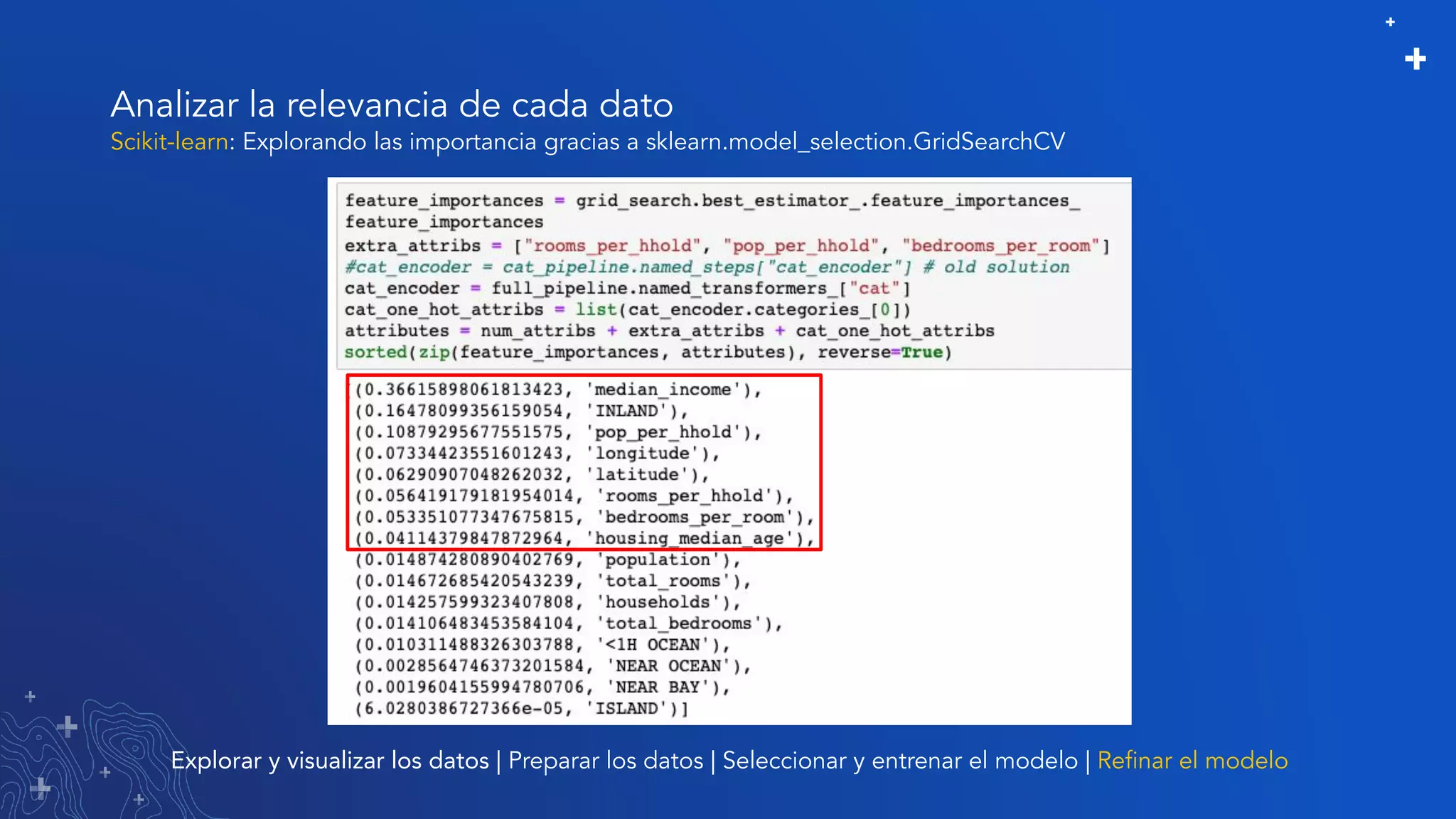

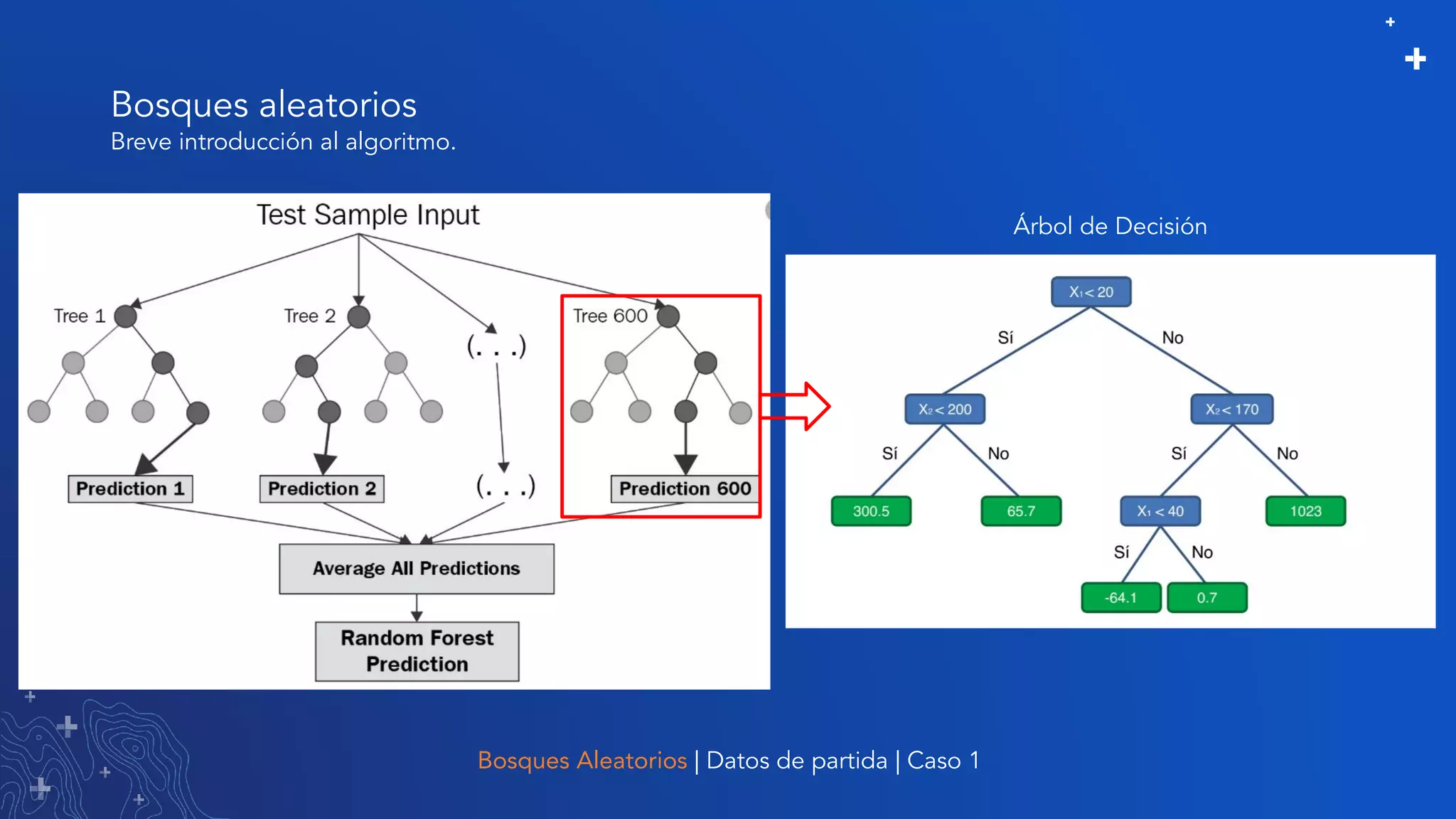

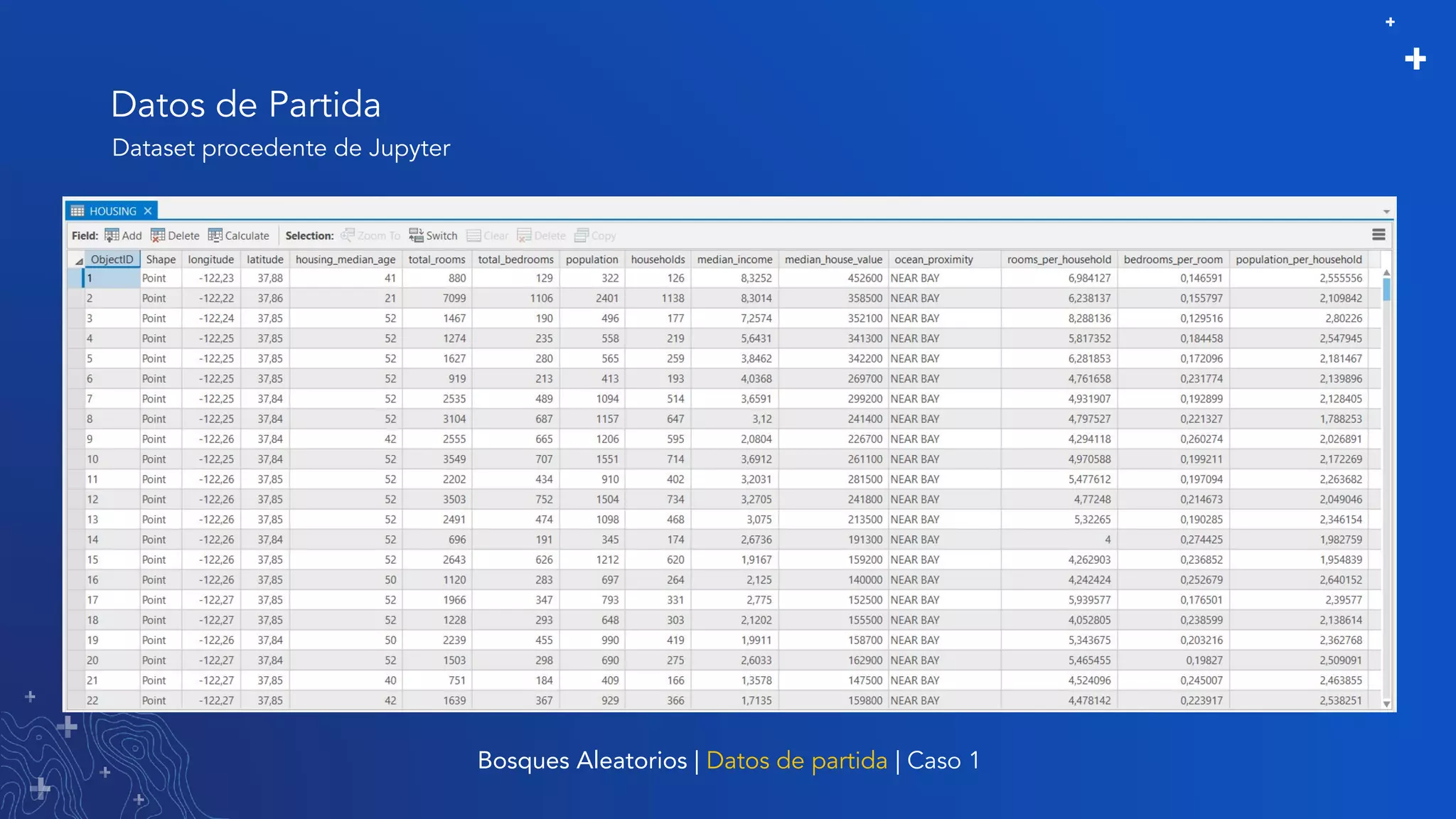
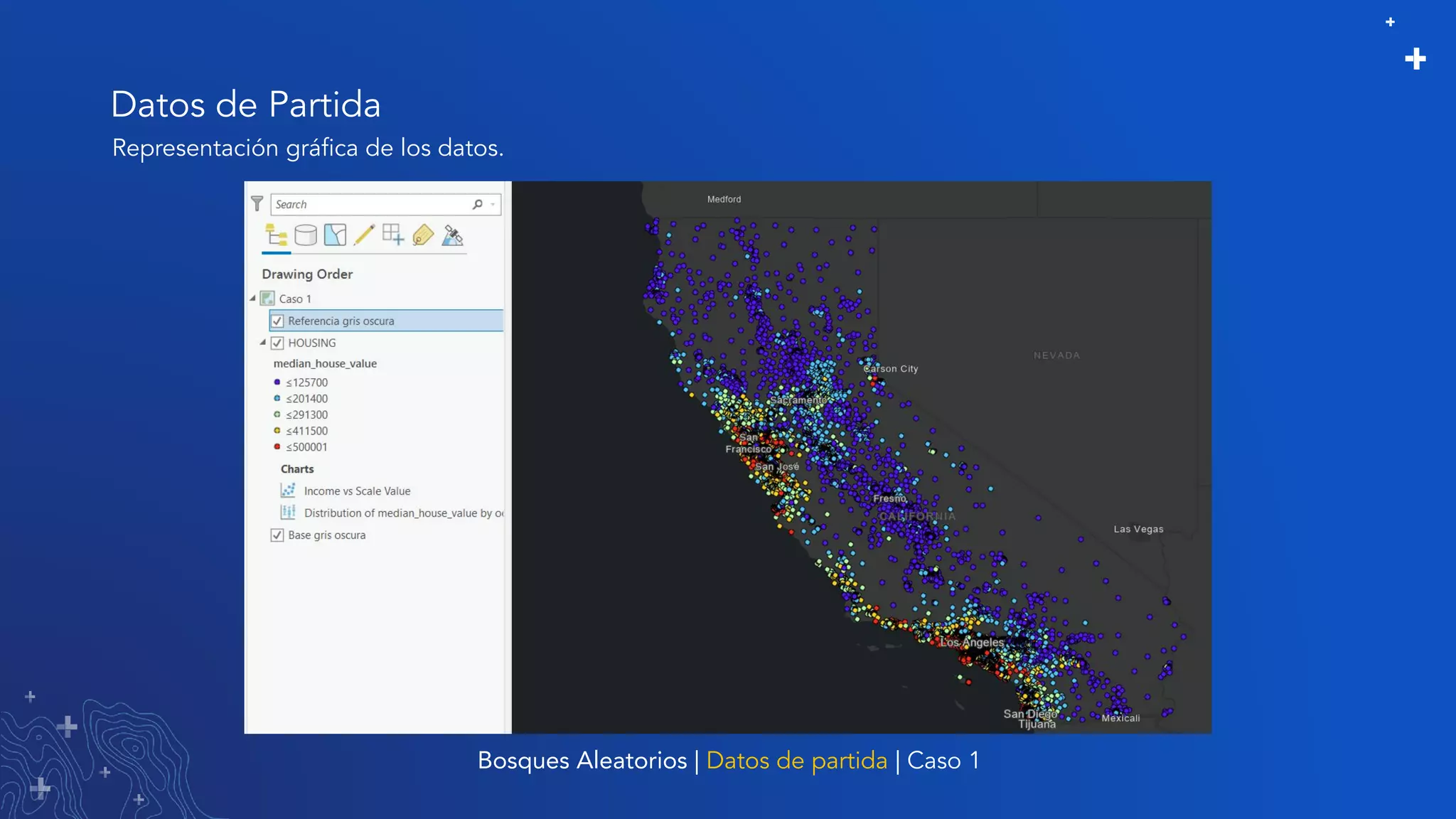

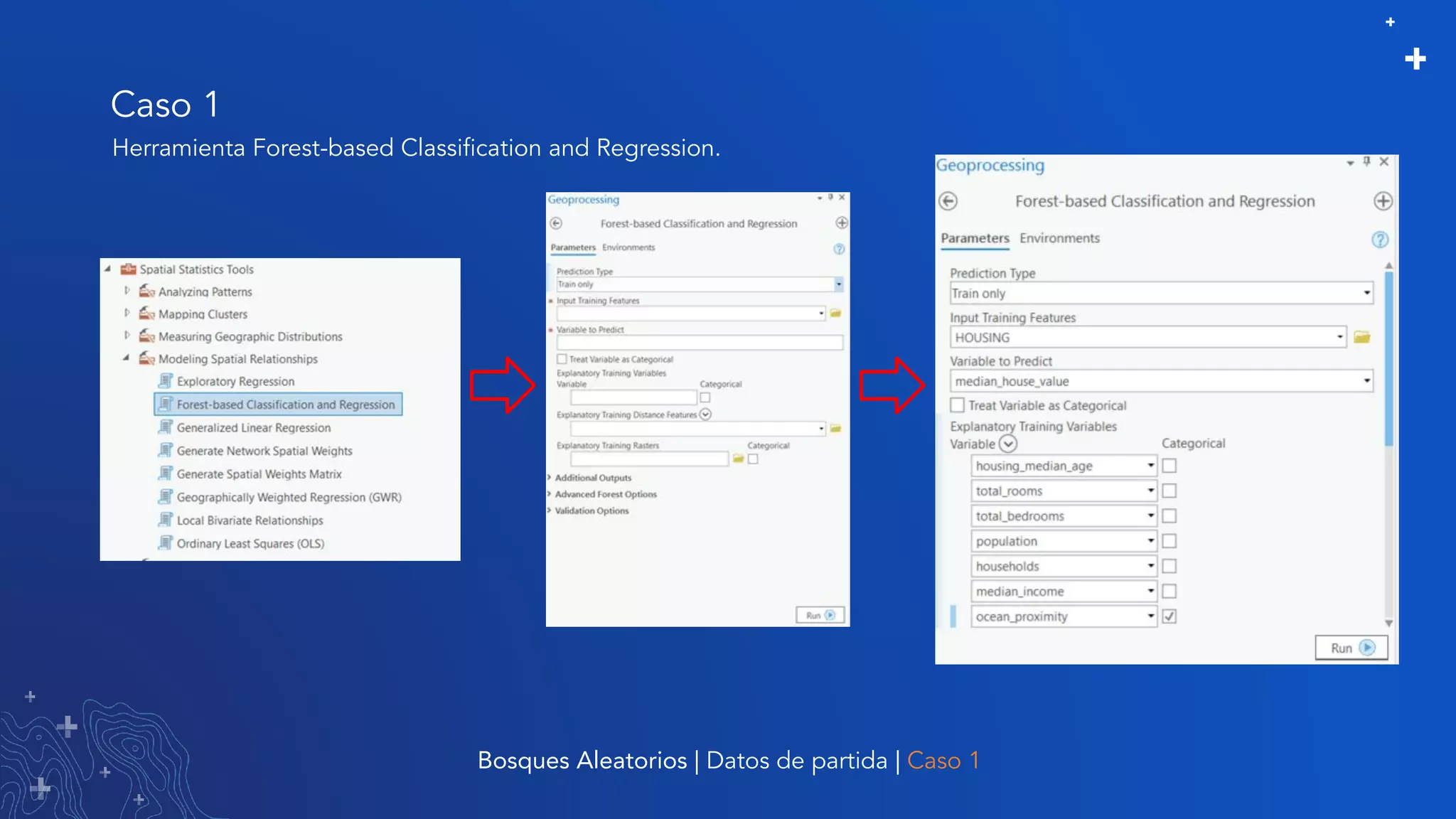
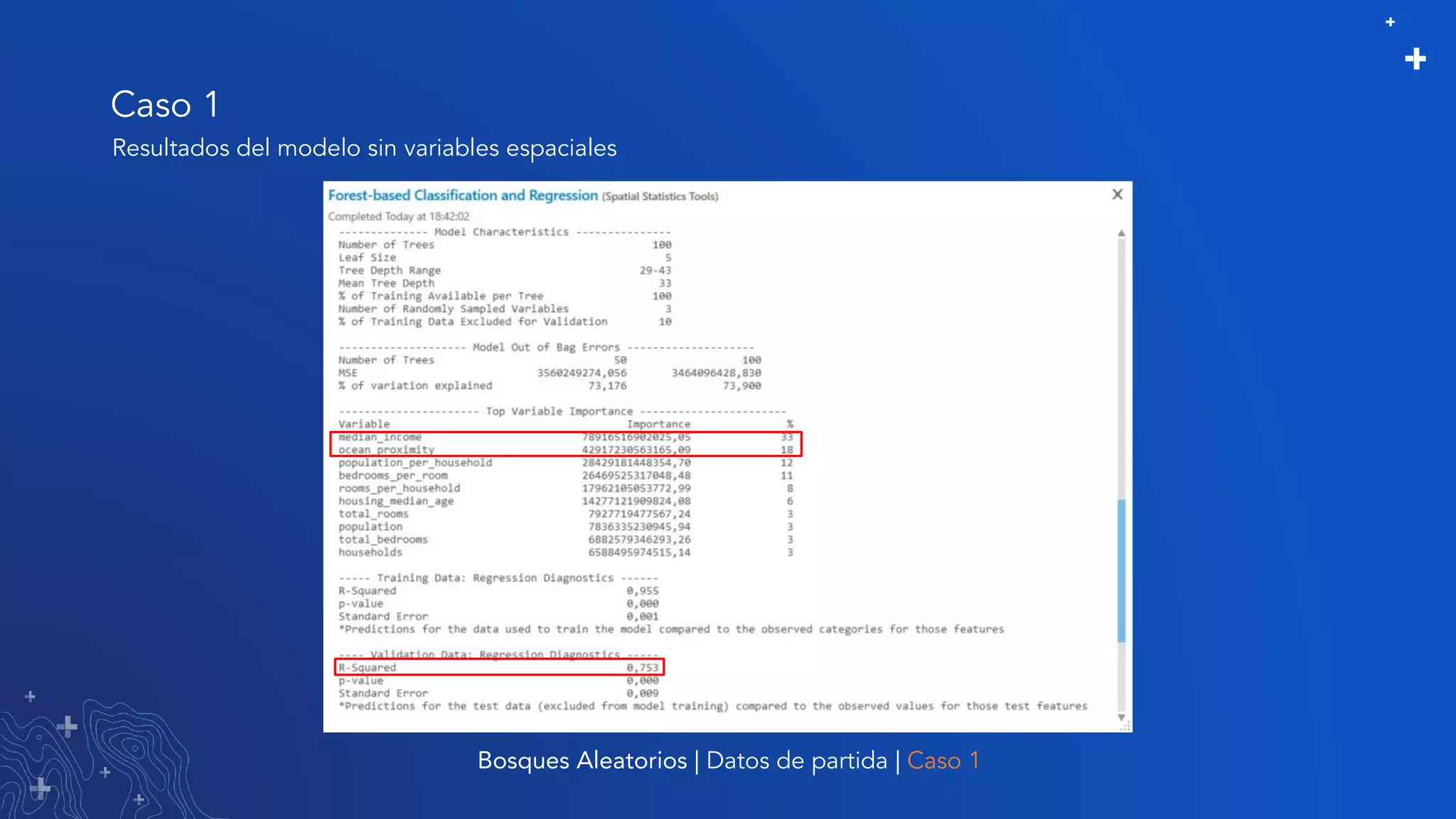

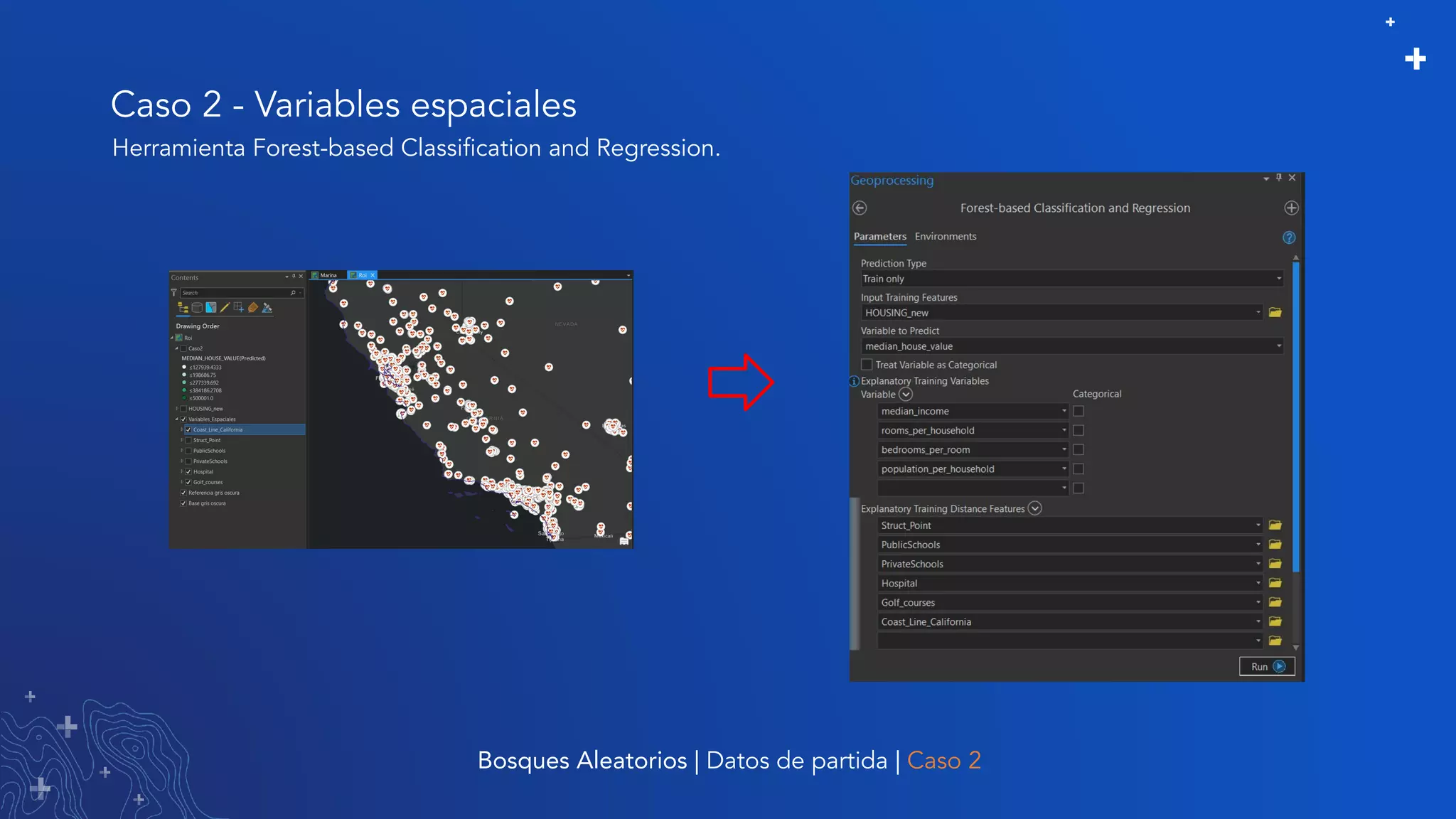
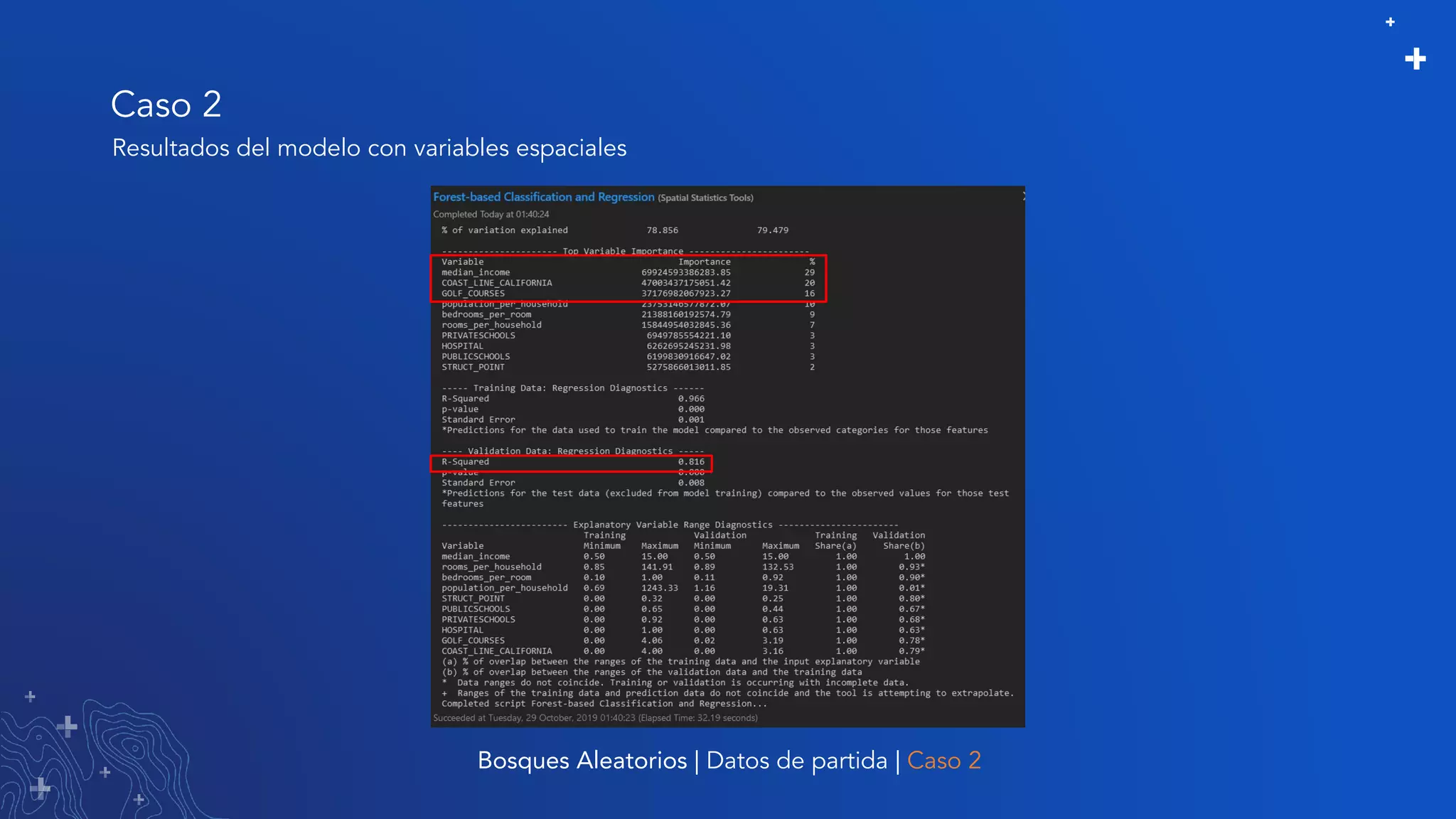

El documento trata sobre el refinamiento de un modelo predictivo para la estimación de precios de viviendas utilizando herramientas de GIS y Python. Se aborda la selección, entrenamiento y mejora del modelo mediante el uso de bibliotecas como scikit-learn y la evaluación dentro de ArcGIS Pro. Además, se discuten técnicas para la visualización de datos y la búsqueda de correlaciones, así como el uso de algoritmos de árboles aleatorios.















































