Descargado 407 veces



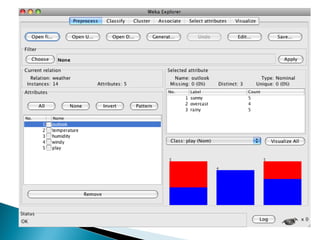



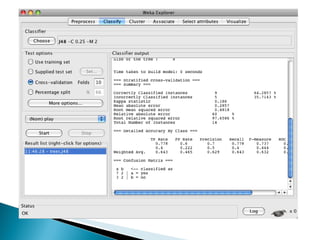


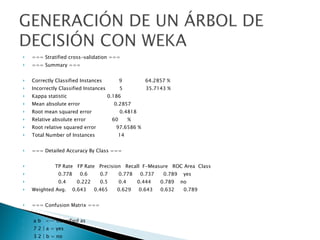

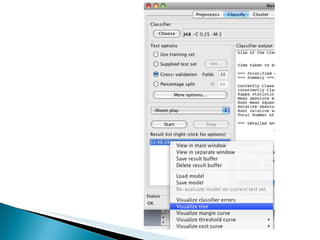
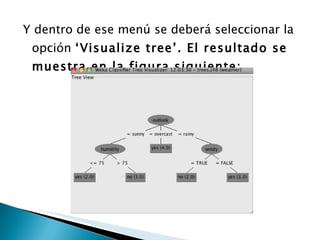

Este documento describe el uso de un clasificador de árboles de decisión (algoritmo J48) en Weka para predecir si una persona jugará tenis basado en condiciones meteorológicas como el clima, la temperatura y la humedad en una base de datos de 14 días. Se carga la base de datos, se genera un árbol de clasificación con 5 nodos y se evalúa su precisión usando validación cruzada, clasificando correctamente el 64% de los casos.


































































































