Descargado 53 veces





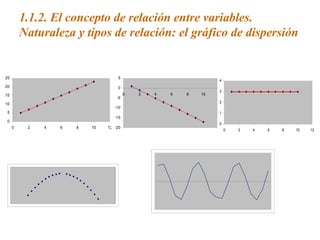
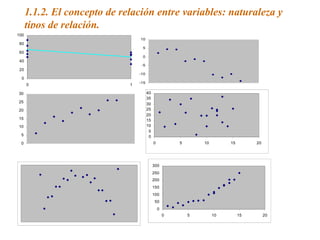
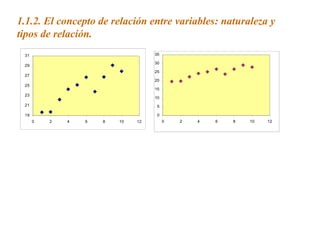

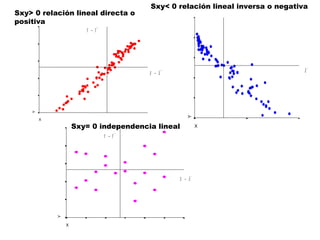
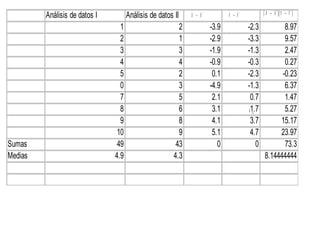
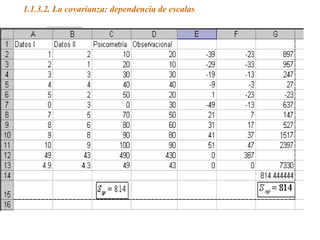


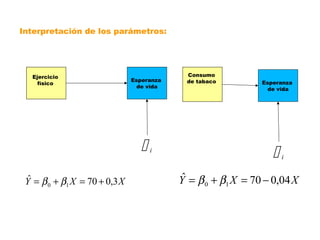

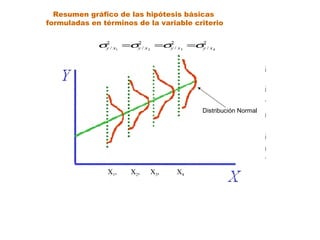
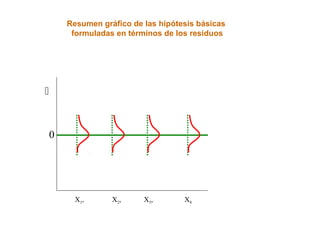



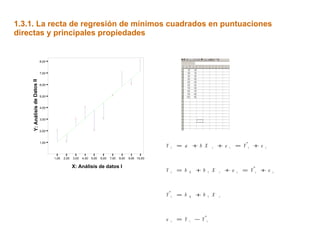


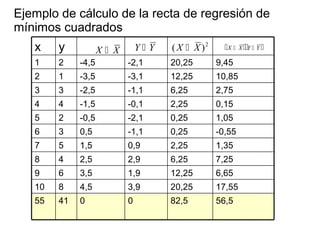





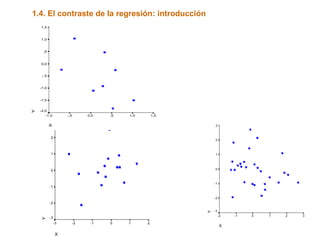
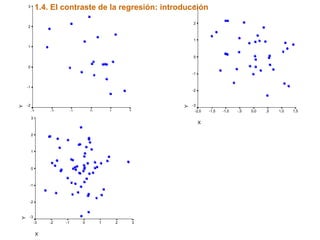
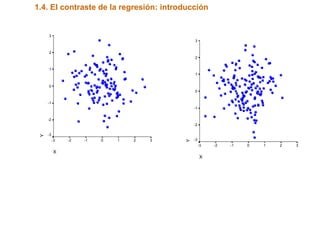
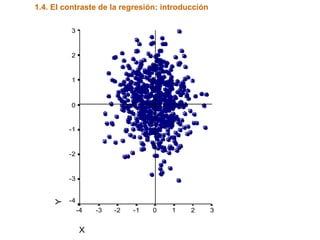
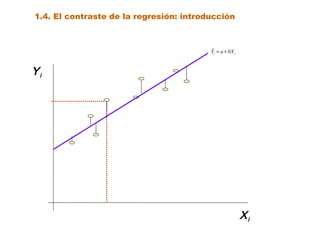
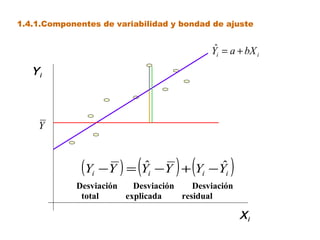




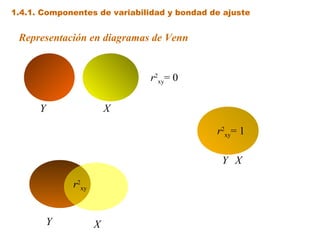



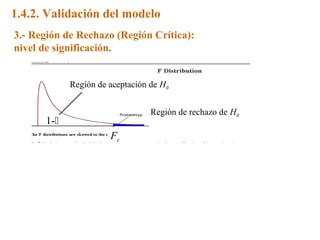

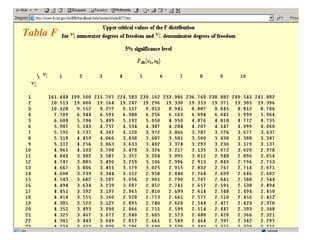


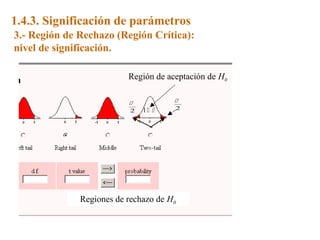

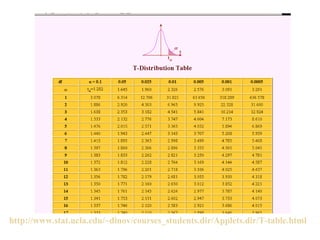
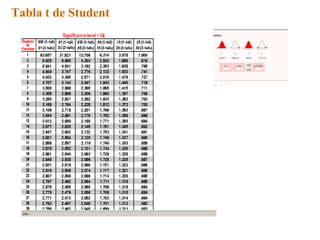

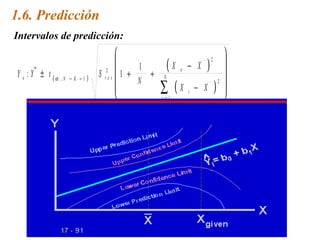
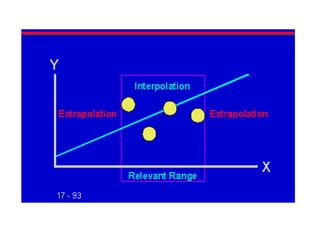

Este documento trata sobre el tema de la regresión lineal simple. Explica el modelo de regresión lineal, incluyendo su estructura, hipótesis y estimación de parámetros. También cubre el contraste del modelo, análisis de residuos, predicción y diagnóstico del modelo. Proporciona ejemplos de cómo se puede utilizar la regresión lineal simple para estudiar diferentes tipos de relaciones entre variables.






















































