Descargar como PDF, PPTX










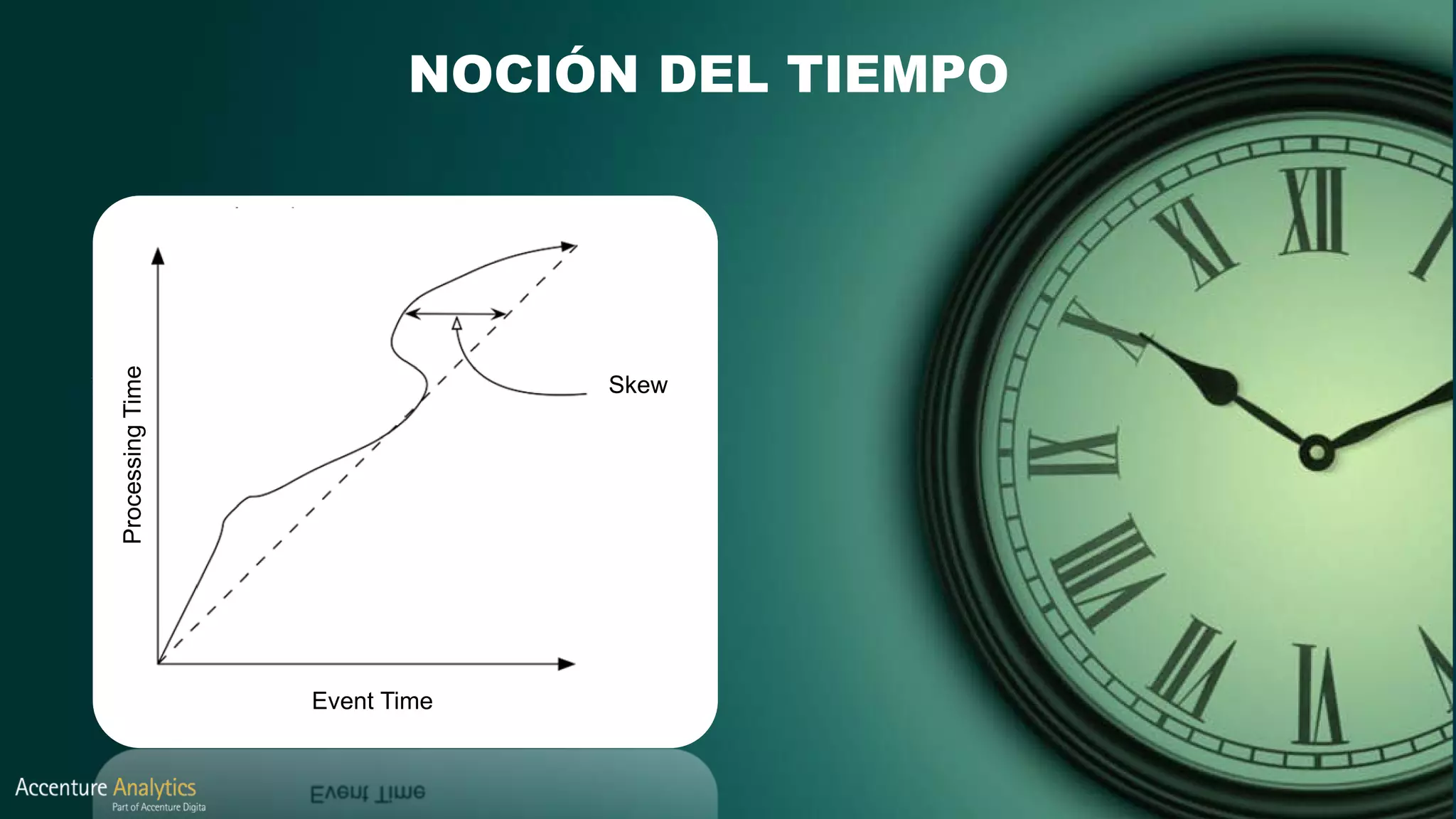


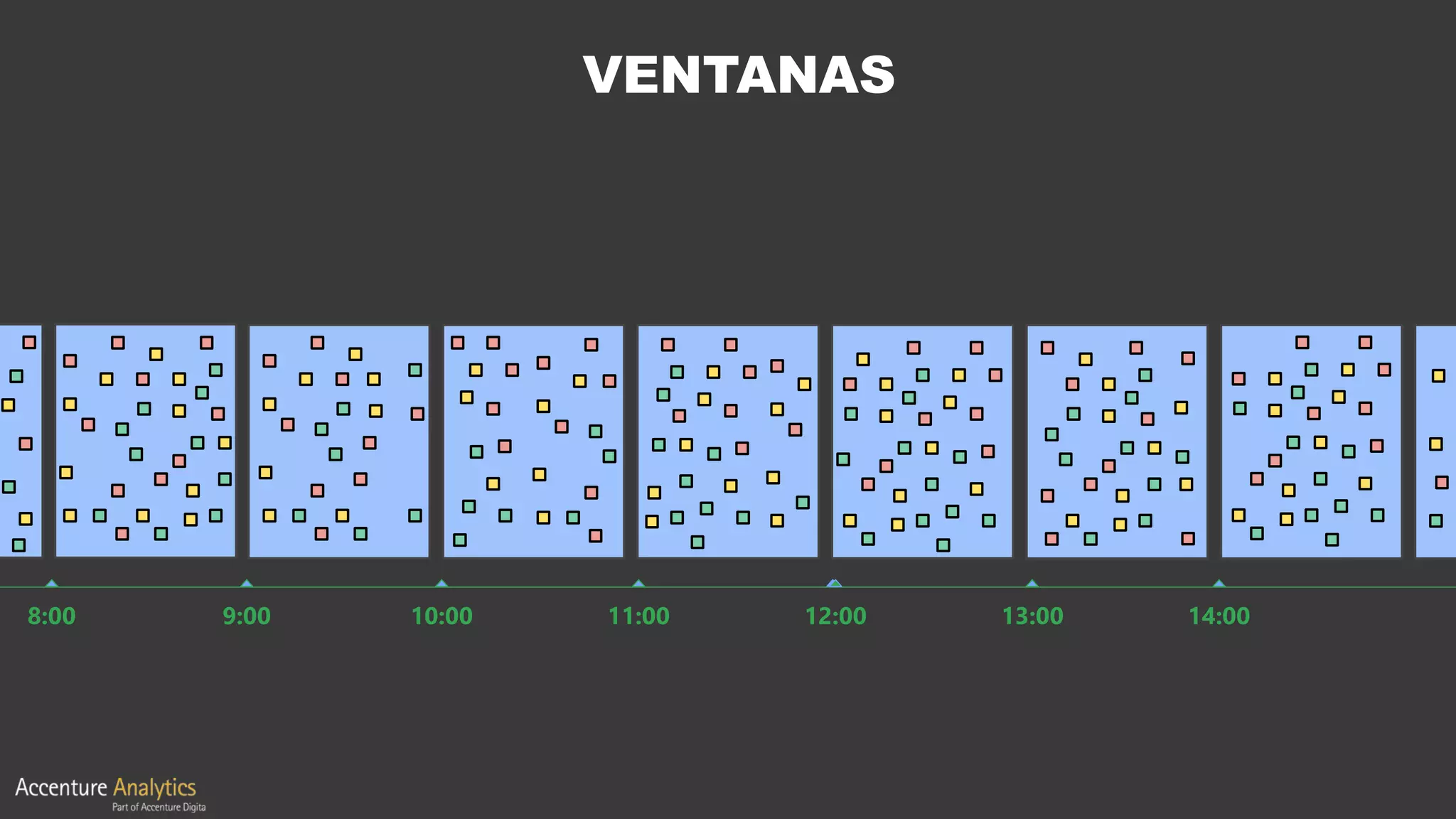

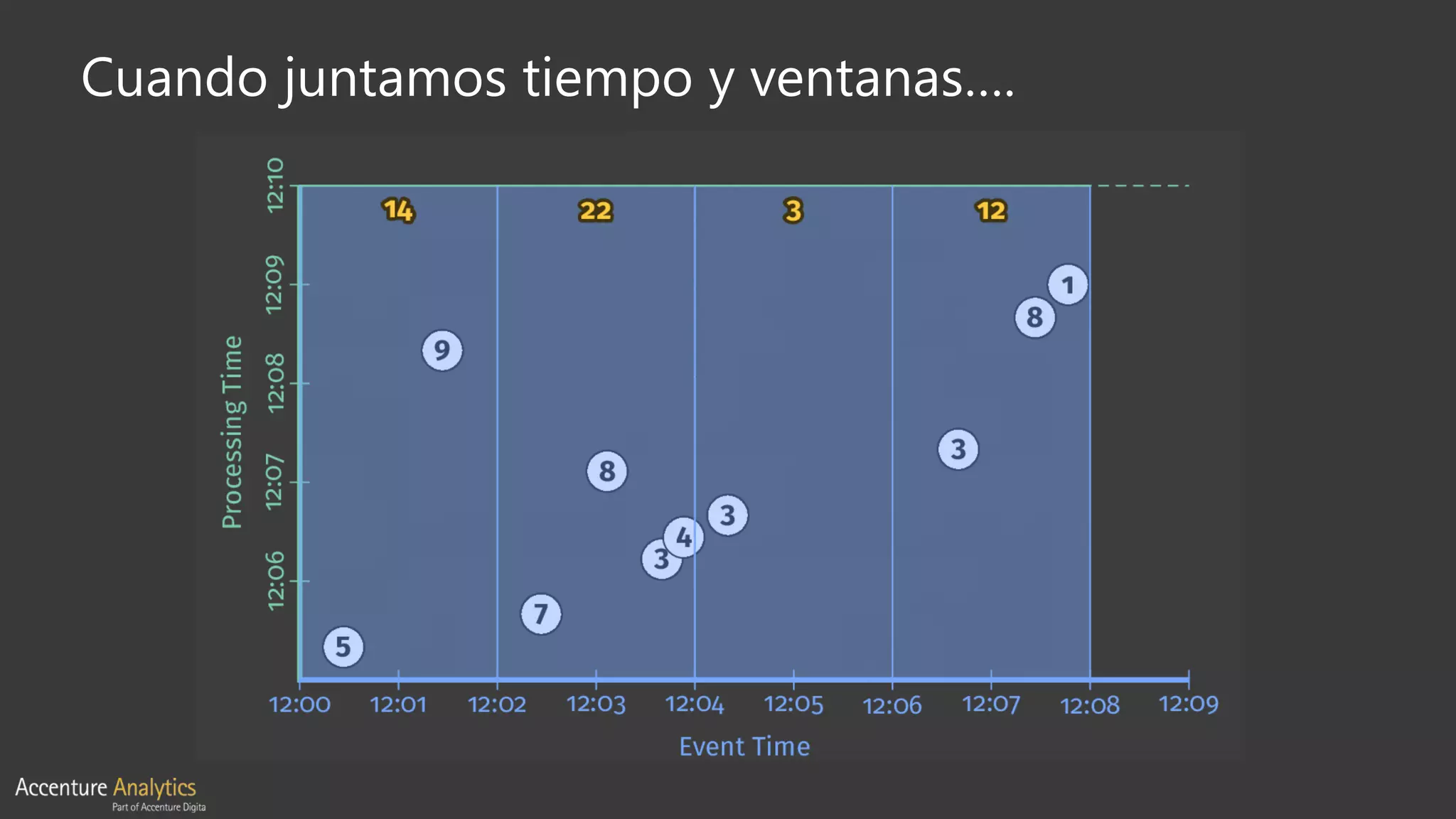
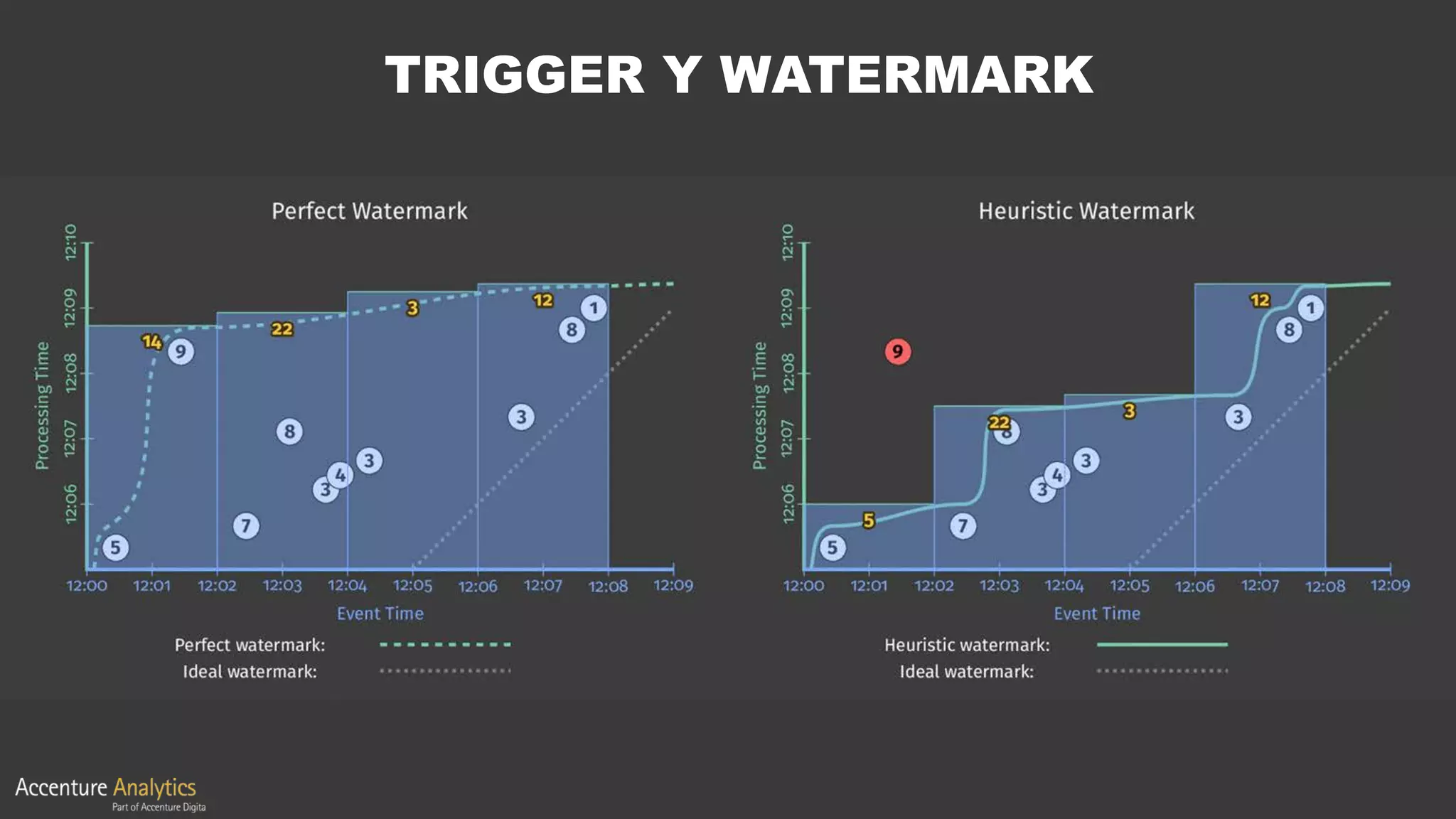
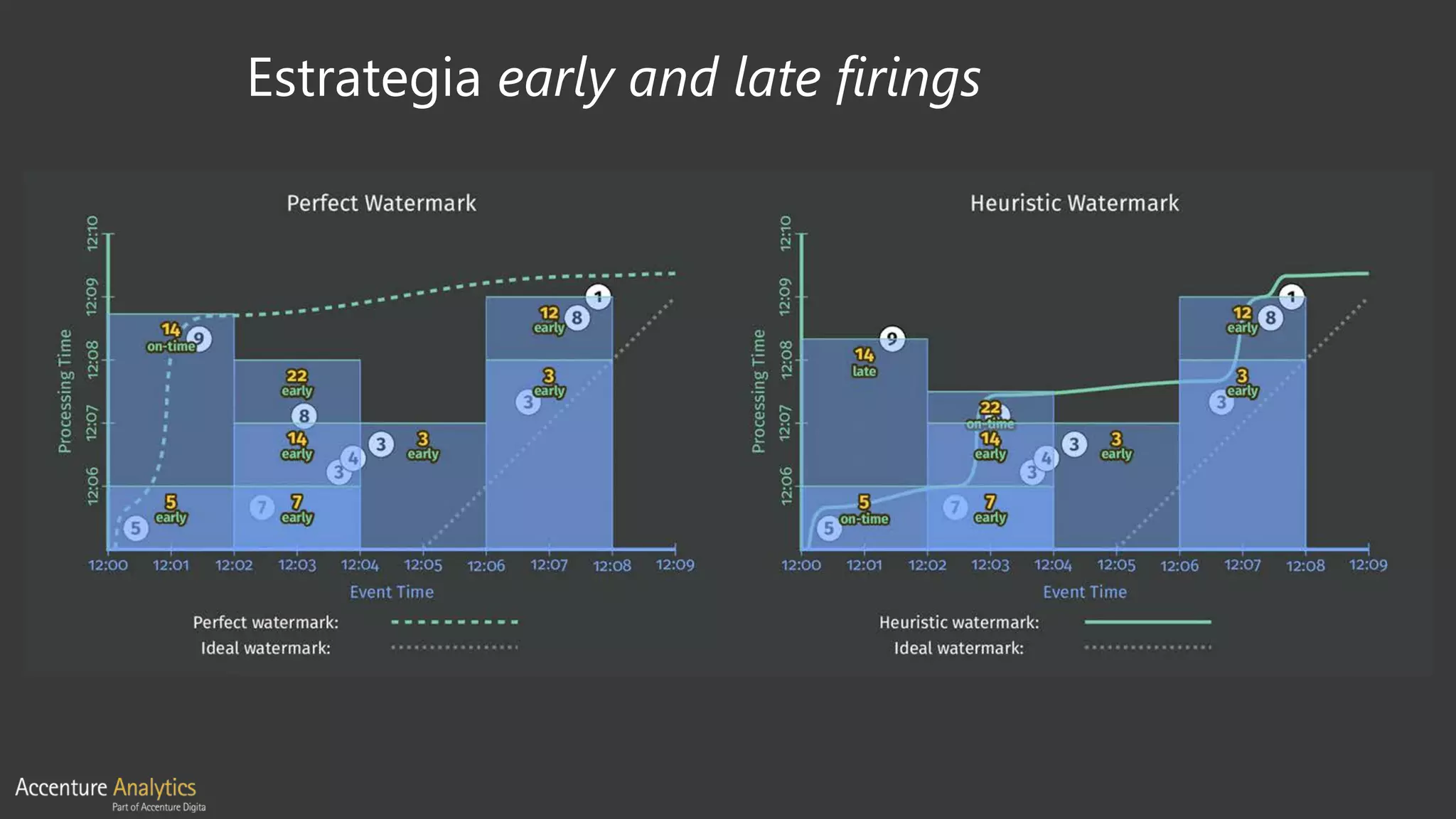








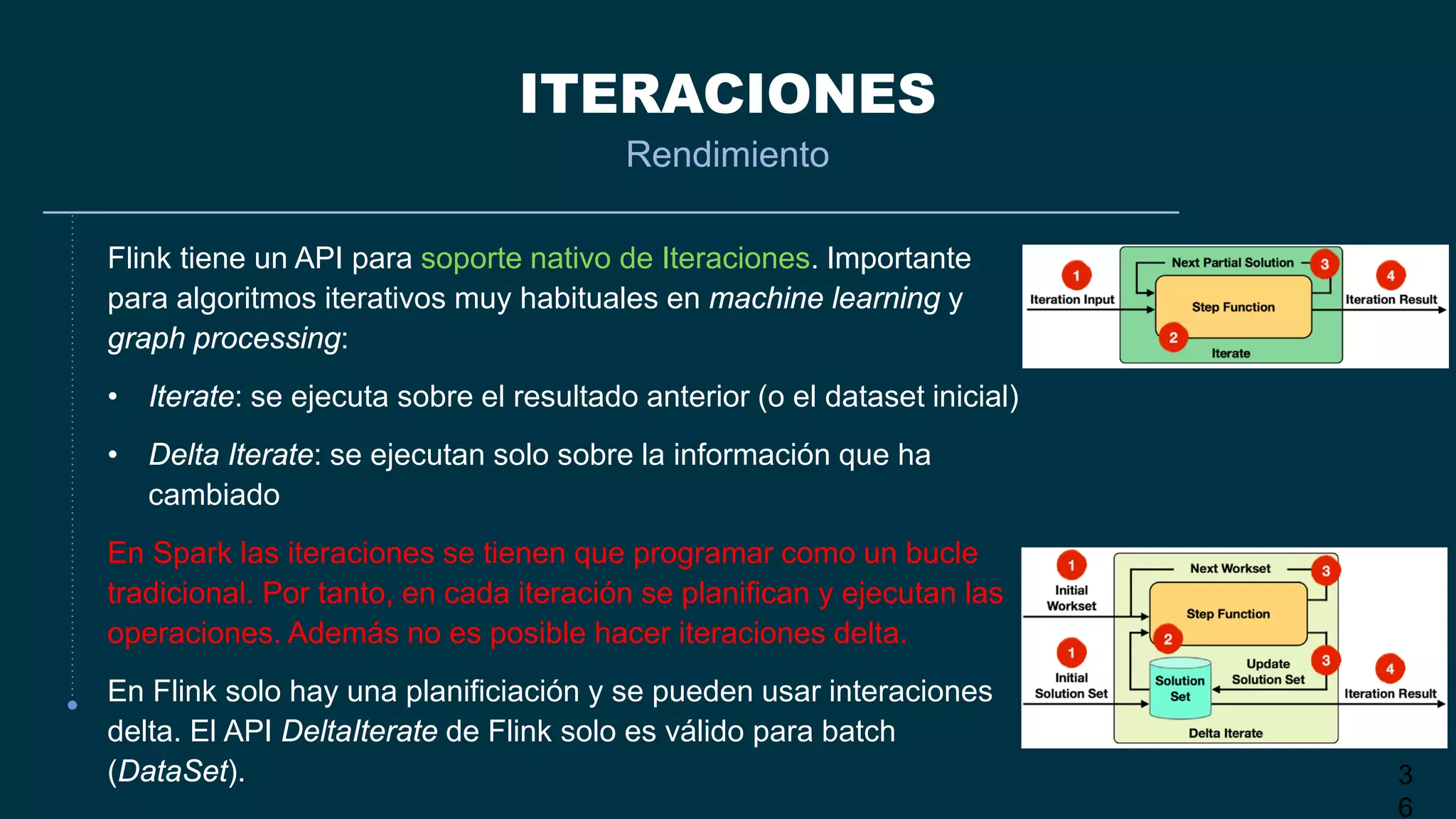

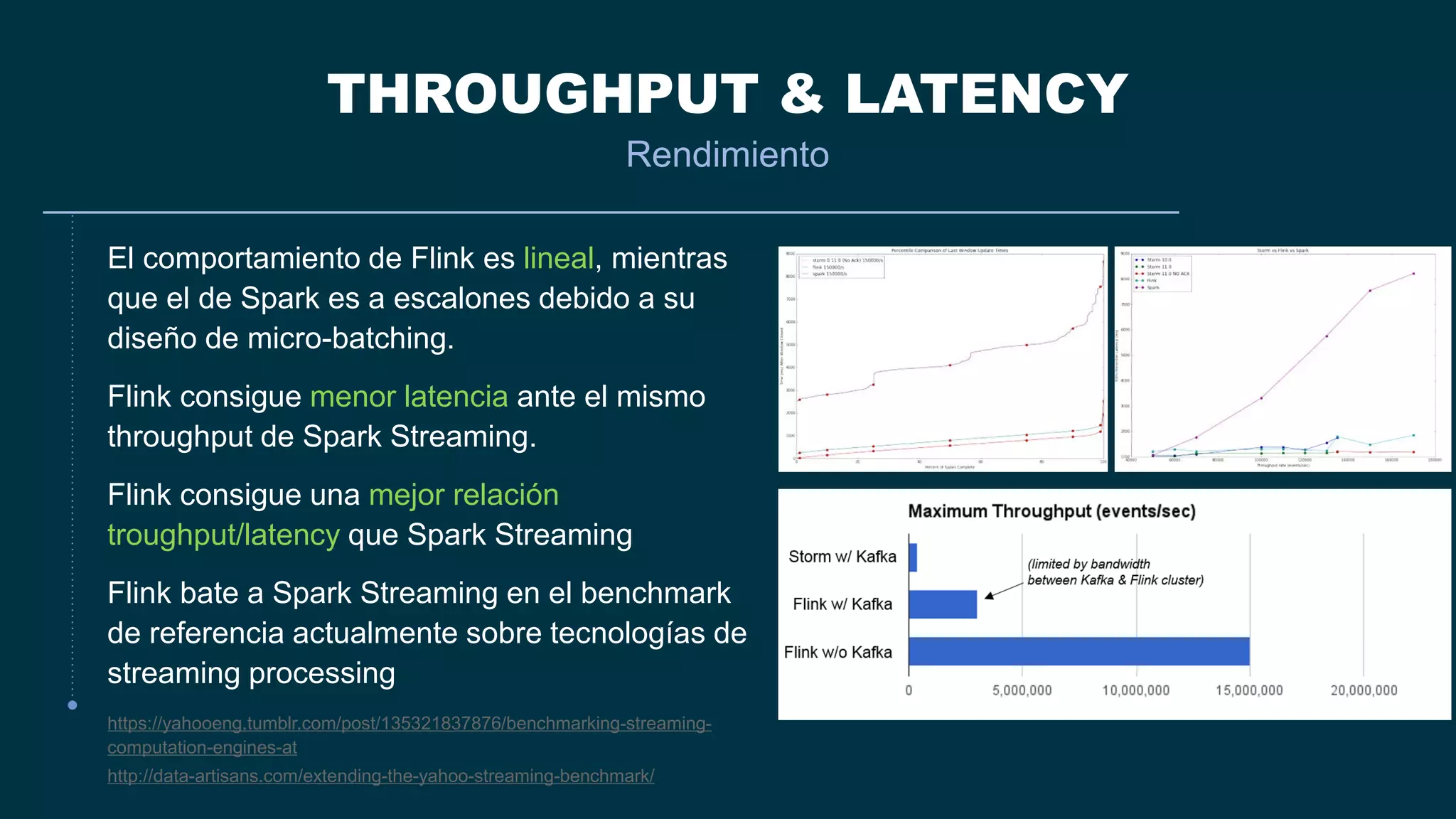





El documento compara Apache Flink y Apache Spark en términos de procesamiento de datos en tiempo real y eficiencia. Flink se destaca por su latencia baja, capacidad de manejar eventos desordenados y soporte nativo para iteraciones, mientras que Spark utiliza un enfoque de micro-batching que introduce latencias y limitaciones en la gestión de ventanas. Se concluye que Flink es preferible para arquitecturas centradas en streaming y situaciones que requieren procesamiento en tiempo real.
![[Main Session] 카프카, 데이터 플랫폼의 최강자](https://cdn.slidesharecdn.com/ss_thumbnails/180519-kafka-oraclefin-180521125323-thumbnail.jpg?width=640&height=640&fit=bounds)