Descargado 29 veces







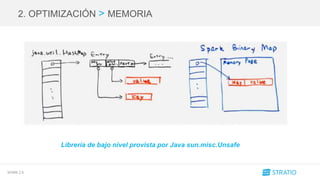
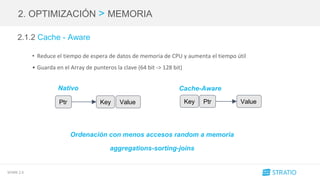
![SPARK 2.0
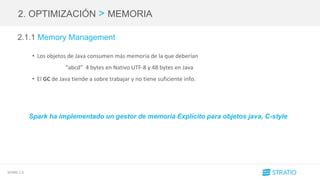
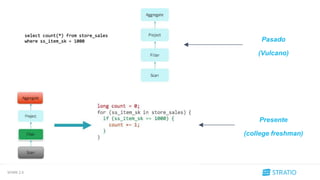
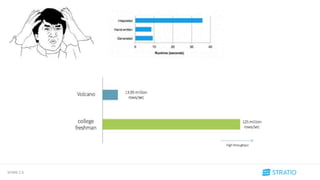
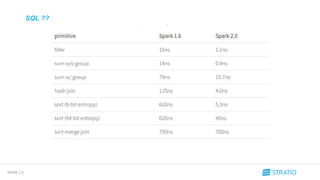
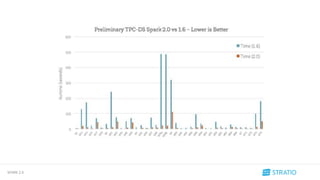
Antes
Ahora
== Physical Plan ==
*Aggregate(functions=[sum(id#201L)])
+- Exchange SinglePartition, None
+- *Aggregate(functions=[sum(id#201L)])
+- *Filter (id#201L > 100)
+-
*Range 0, 1, 3, 1000, [id#201L]
== Physical Plan ==
*TungstenAggregate(key=[],functions=[(sum(id#201L),mode=Final,isDistinct=false)], output=[sum(id)#212L])
+- Exchange SinglePartition, None
+- *TungstenAggregate(key=[], functions=[(sum(id#201L),mode=Partial,isDistinct=false)], output=[sum#214L])
+- *Filter (id#201L > 100)
+- *Range 0, 1, 3, 1000, [id#201L]](https://image.slidesharecdn.com/spark2-160607092136/85/Meetup-Spark-2-0-16-320.jpg)

![SPARK 2.0
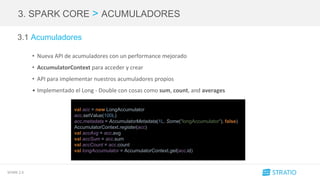
2. OPTIMIZACIÓN > FUNCIONES
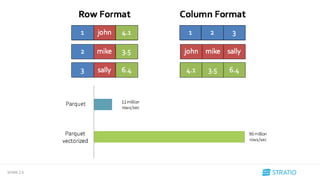
2.2 Funciones
• Integración de algoritmos aproximados en DataFrames y Datasets.
HyperLogLog - CountMinSketch - BloomFilters
• ApproxCountDistinct
Estimación del número de elementos distintos que hay en una colección
• ApproxQuantile
Devuelve una aproximación a los percentiles
Ejm. approx_count = users.agg(approxCountDistinct(users['user'], rsd = rsd))
Jugamos con el margen de error, más margen => más rápido](https://image.slidesharecdn.com/spark2-160607092136/85/Meetup-Spark-2-0-22-320.jpg)



![SPARK 2.0
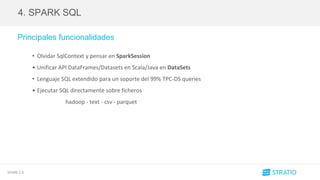
4. SPARK SQL > API DataSet
4.2 API Dataset
• Unificada la API de DataFrames y Dataset
• type DataFrame = DataSet[Row]
• No disponible en R ni Python
• DataSet tipados y no tipados:
Operaciones sobre tipados y no tipados (map, select, etc...)
Agregaciones](https://image.slidesharecdn.com/spark2-160607092136/85/Meetup-Spark-2-0-30-320.jpg)



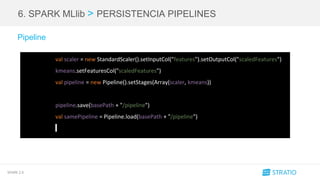



El documento presenta las características y optimizaciones de Spark 2.0, destacando la gestión de memoria, nuevas funcionalidades en Spark SQL y mejoras en Spark Streaming. Además, se menciona el uso de acumuladores, la integración de algoritmos aproximados en dataframes, y la persistencia de modelos en Spark MLlib. José Carlos García Serrano, arquitecto Big Data en Stratio, proporciona su contacto y un enlace para obtener más información.
![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)




















































