Descargar como PDF, PPTX















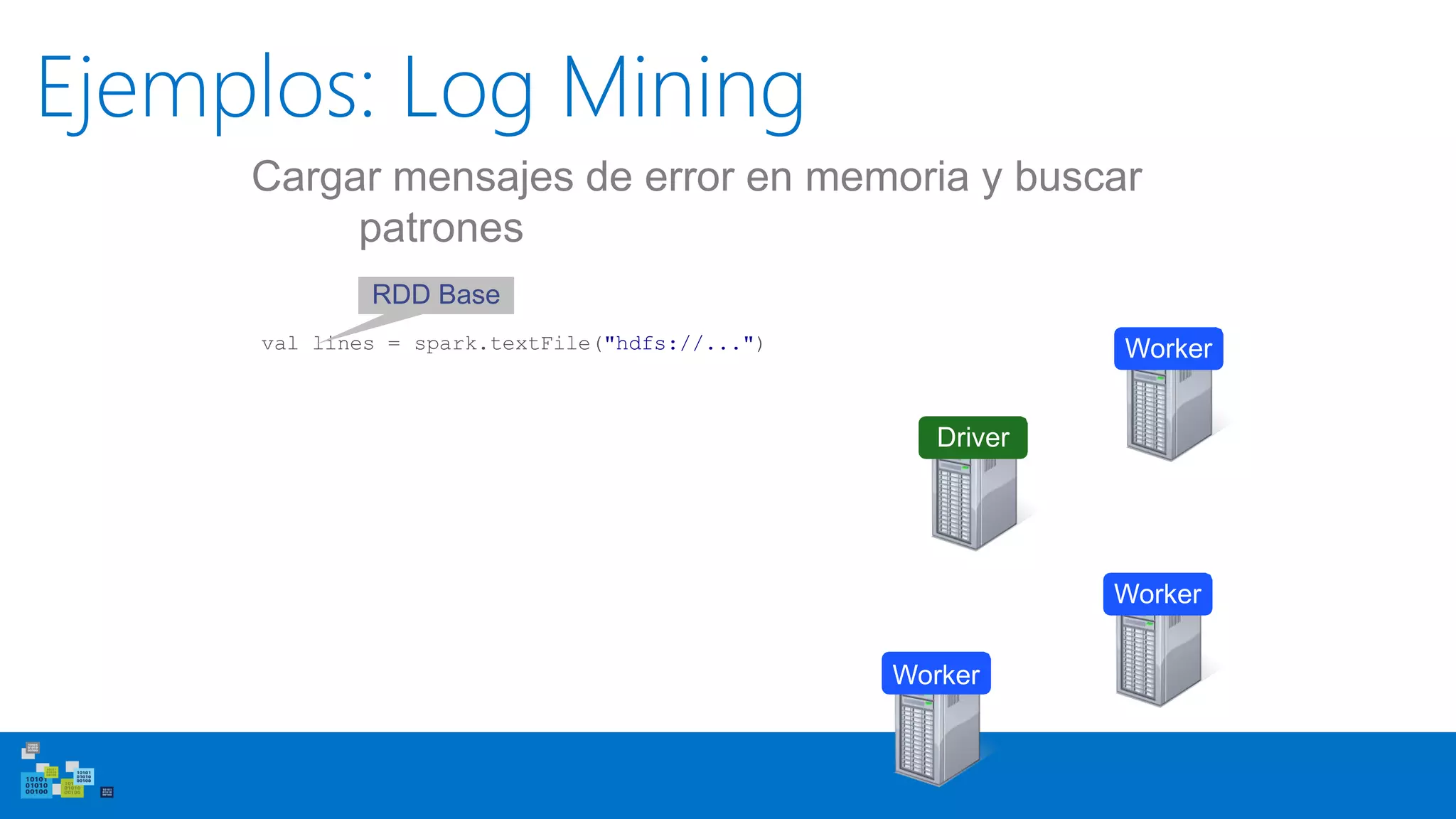

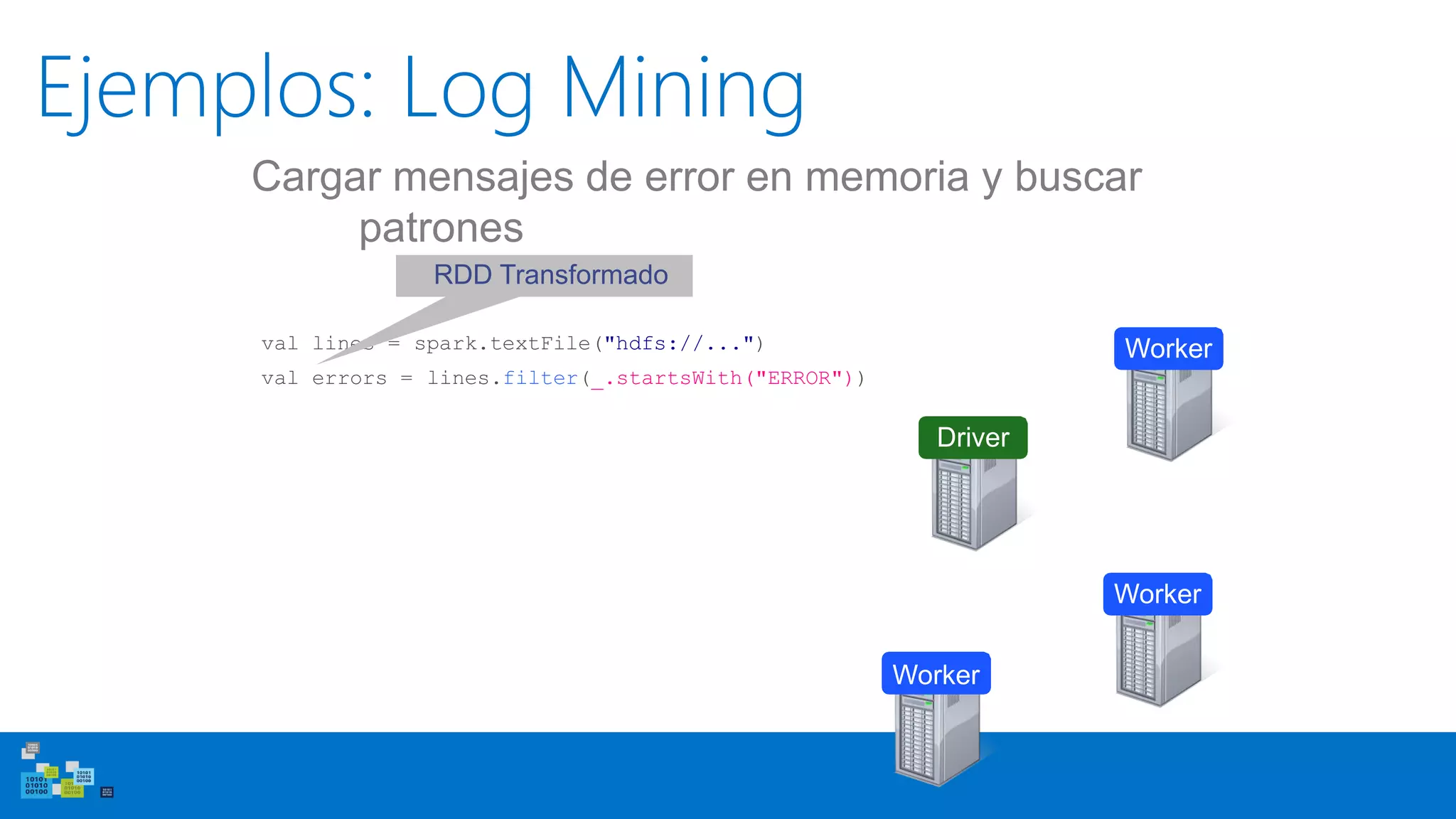




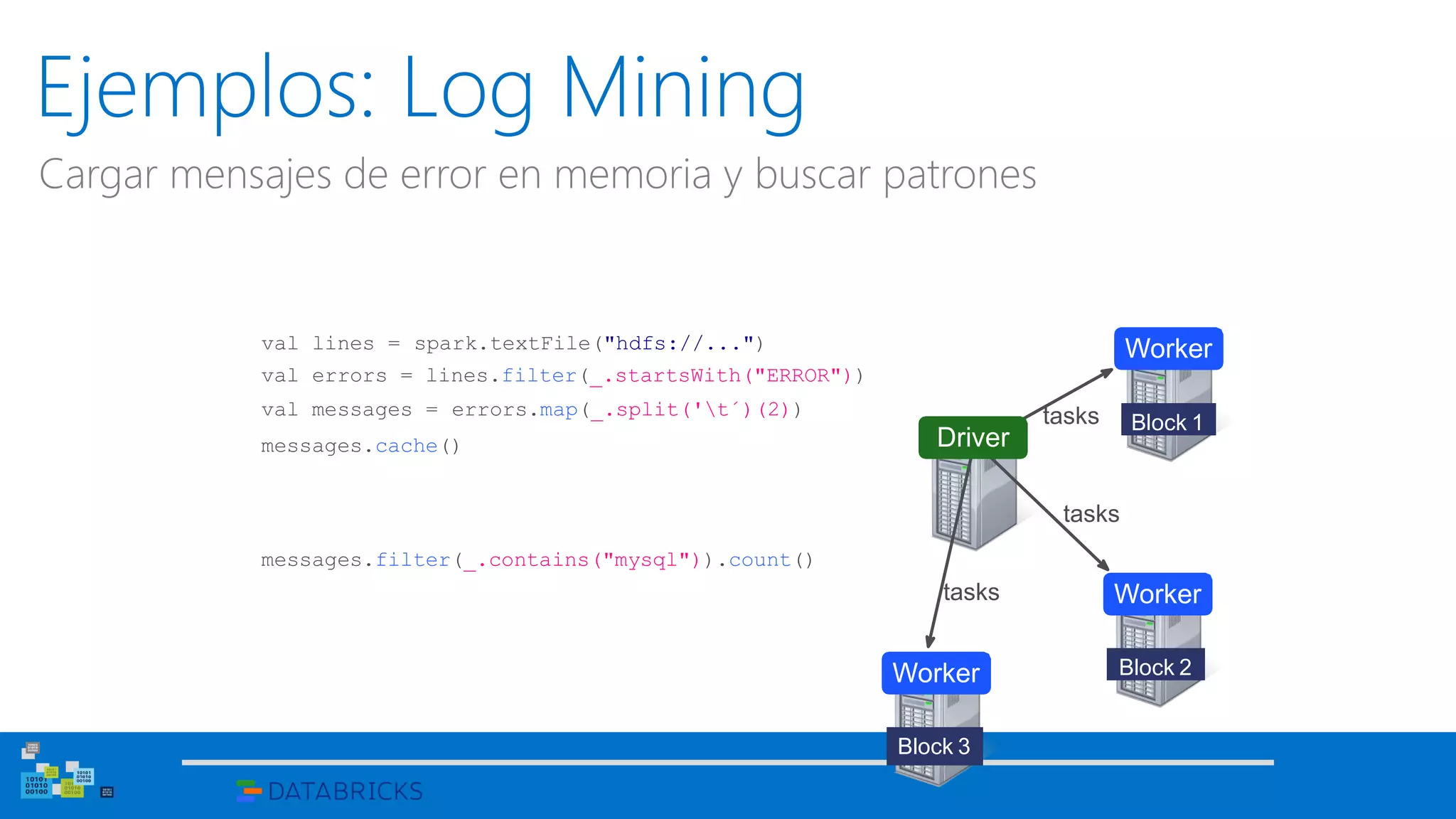


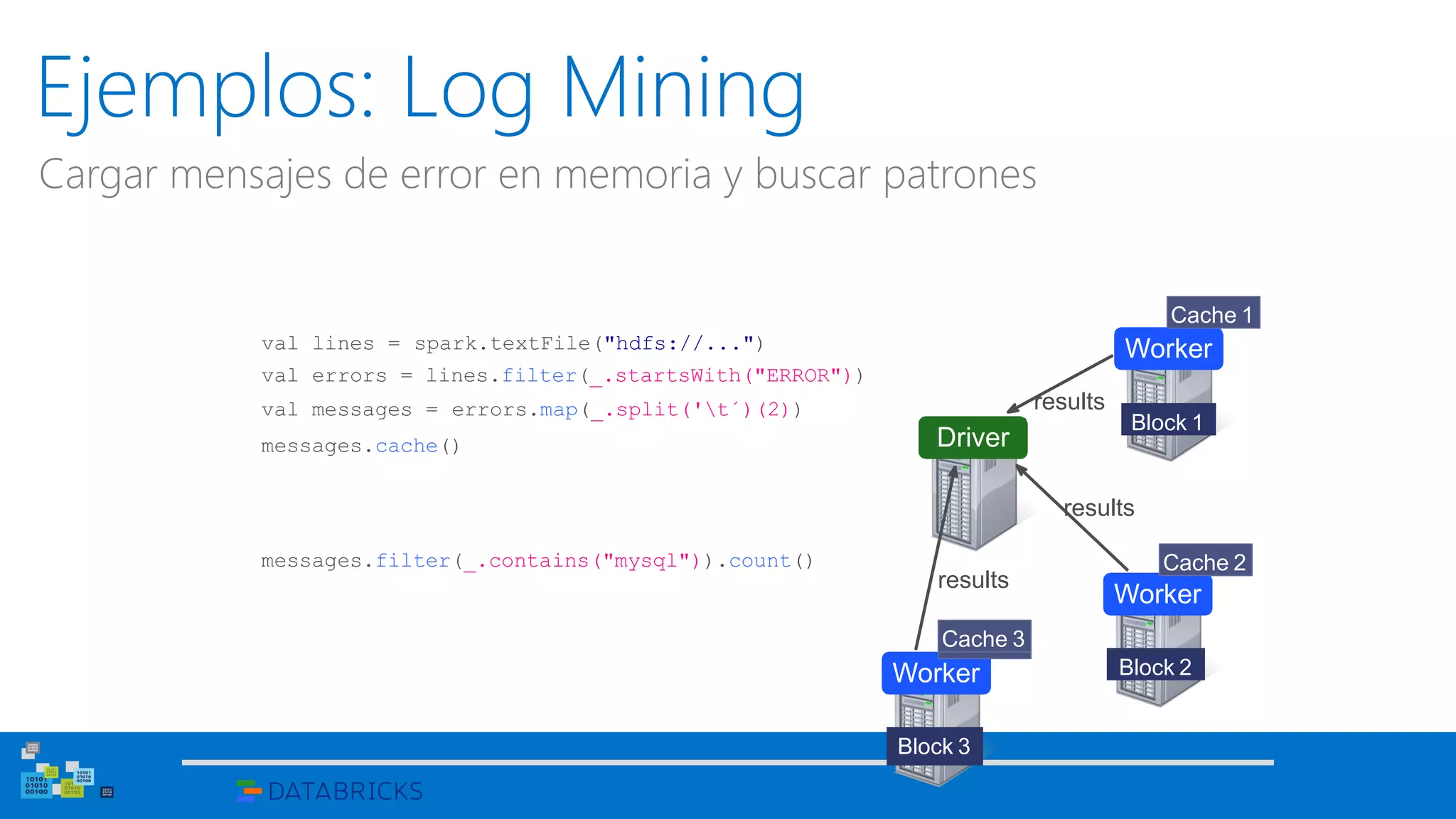











![Uso del Shell
Modes:
MASTER=local ./spark-shell
MASTER=local[2] ./spark-shell
# local, 1
# local, 2
thread
threads
MASTER=spark://host:port ./spark-shell # cluster
Launching:
spark-shell
pyspark (IPYTHON=1)](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-56-2048.jpg)
![Creación de RDDs
# Load text file from local FS, HDFS, or S3
> sc.textFile(“file.txt”)
> sc.textFile(“directory/*.txt”)
> sc.textFile(“hdfs://namenode:9000/path/file”)
# Use existing Hadoop InputFormat (Java/Scala only)
> sc.hadoopFile(keyClass, valClass, inputFmt, conf)
# Turn a Python collection into an RDD
> sc.parallelize([1, 2, 3])](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-57-2048.jpg)
![Transformaciones básicas
> nums = sc.parallelize([1, 2, 3])
# Pass each element through a function
> squares = nums.map(lambda x: x*x) // {1, 4, 9}
zero or more others# Map each element to
> nums.flatMap(lambda
> # => {0, 0, 1, 0, 1,
x: => range(x))
2}
Range object (sequence
of numbers 0, 1, …, x-‐1)
# Keep elements passing a predicate
> even = squares.filter(lambda x: x % 2 == 0) // {4}](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-58-2048.jpg)
![Acciones base
> nums = sc.parallelize([1, 2, 3])
# Retrieve RDD contents as
> nums.collect() # => [1,
a local collection
2, 3]
# Count number of elements
> nums.count() # => 3
# Merge elements with function
> nums.reduce(lambda
an associative
x, y: x + y) # => 6
# Write elements to a text file
> nums.saveAsTextFile(“hdfs://file.txt”)
# Return first K elements
> nums.take(2) # => [1, 2]](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-59-2048.jpg)
![Trabajo con Key-Value Pairs
Spark’s “distributed reduce” transformaciones para
operar sobre RDDs de key-value pairs
Python: pair = (a, b)
pair[0] # => a
pair[1] # => b
Scala: val pair = (a, b)
pair._1 // => a
pair._2 // => b
Java: Tuple2 pair = new Tuple2(a, b);
pair._1 // => a
pair._2 // => b](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-60-2048.jpg)
![Operaciones Key-Value
> pets = sc.parallelize(
[(“cat”, 1), (“dog”, 1), (“cat”, 2)])
> pets.sortByKey() # => {(cat, 1), (cat, 2), (dog, 1)}
reduceByKey implementa combinadores del
map
> pets.reduceByKey(lambda x, y:
# => {(cat,
x +
3),
y)
(dog, 1)}
> pets.groupByKey() # => {(cat, [1, 2]), (dog, [1])}](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-61-2048.jpg)

![Key-Value Operaciones Adiconales
> visits = sc.parallelize([ (“index.html”,
(“about.html”,
(“index.html”,
“1.2.3.4”),
“3.4.5.6”),
“1.3.3.1”) ])
> pageNames = sc.parallelize([ (“index.html”,
(“about.html”,
“Home”),
“About”) ])
>
visits.join(pageNames
)
> visits.cogroup(pageNames)
# (“index.html”, ([“1.2.3.4”, “1.3.3.1”],
[“Home”]))
# (“about.html”, ([“3.4.5.6”], [“About”]))
#
#
(“index.html”,
(“index.html”,
(“1.2.3.4”,
(“1.3.3.1”,
“Home”))
“Home”))
# (“about.html”, (“3.4.5.6”, “About”))](https://image.slidesharecdn.com/anlisisdedatosconapachespark-170401151206/75/Analisis-de-datos-con-Apache-Spark-63-2048.jpg)




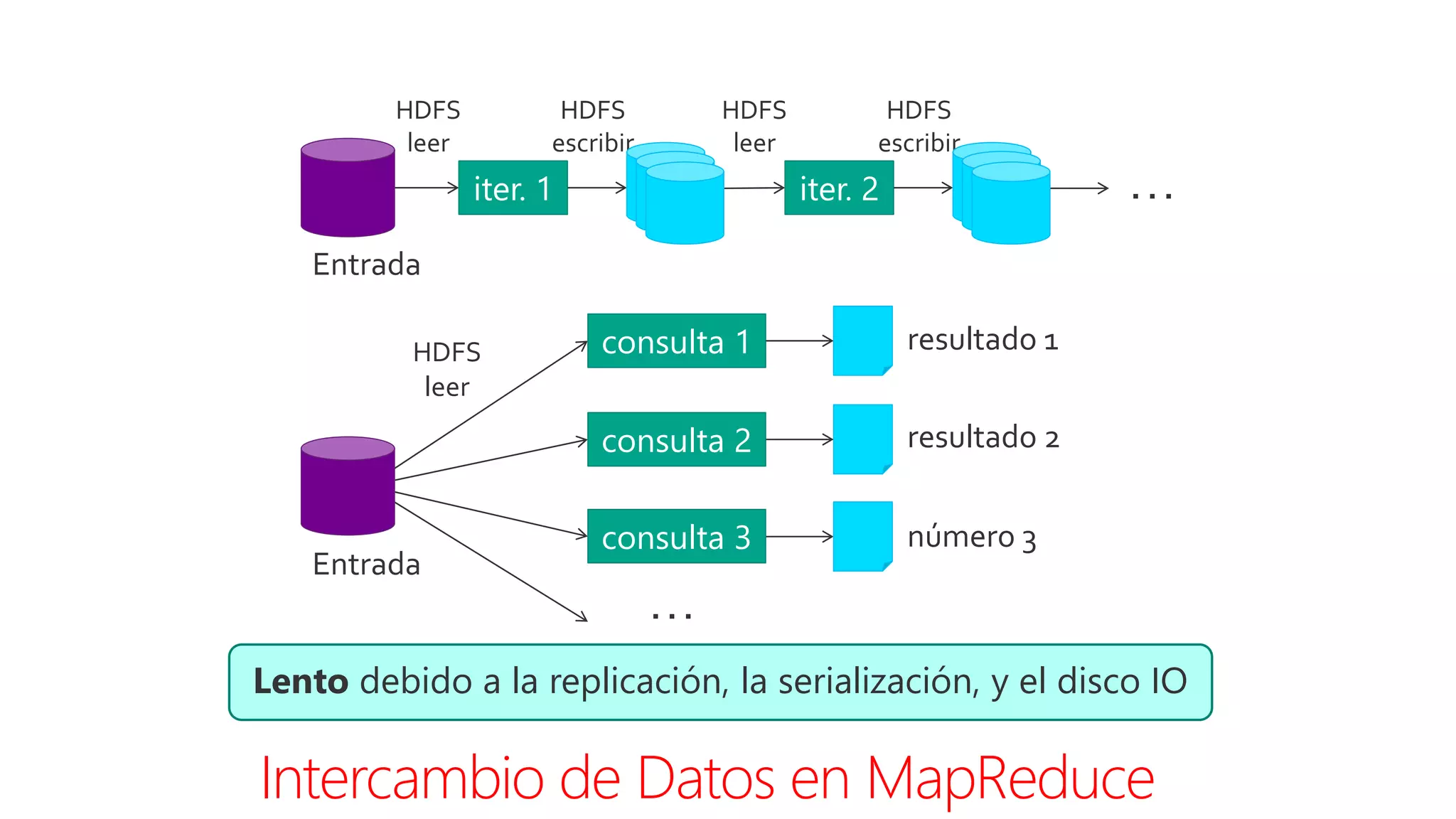
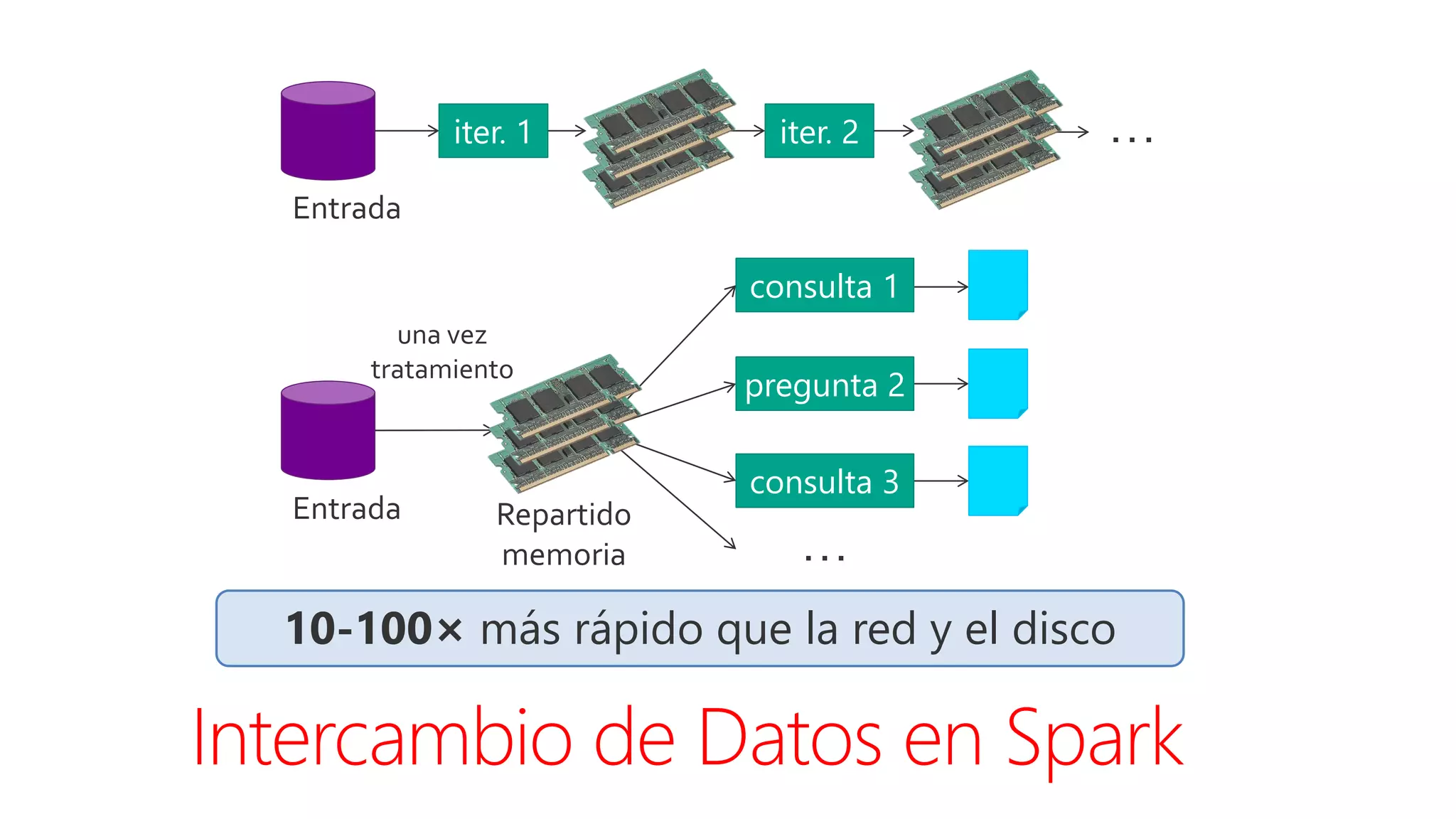
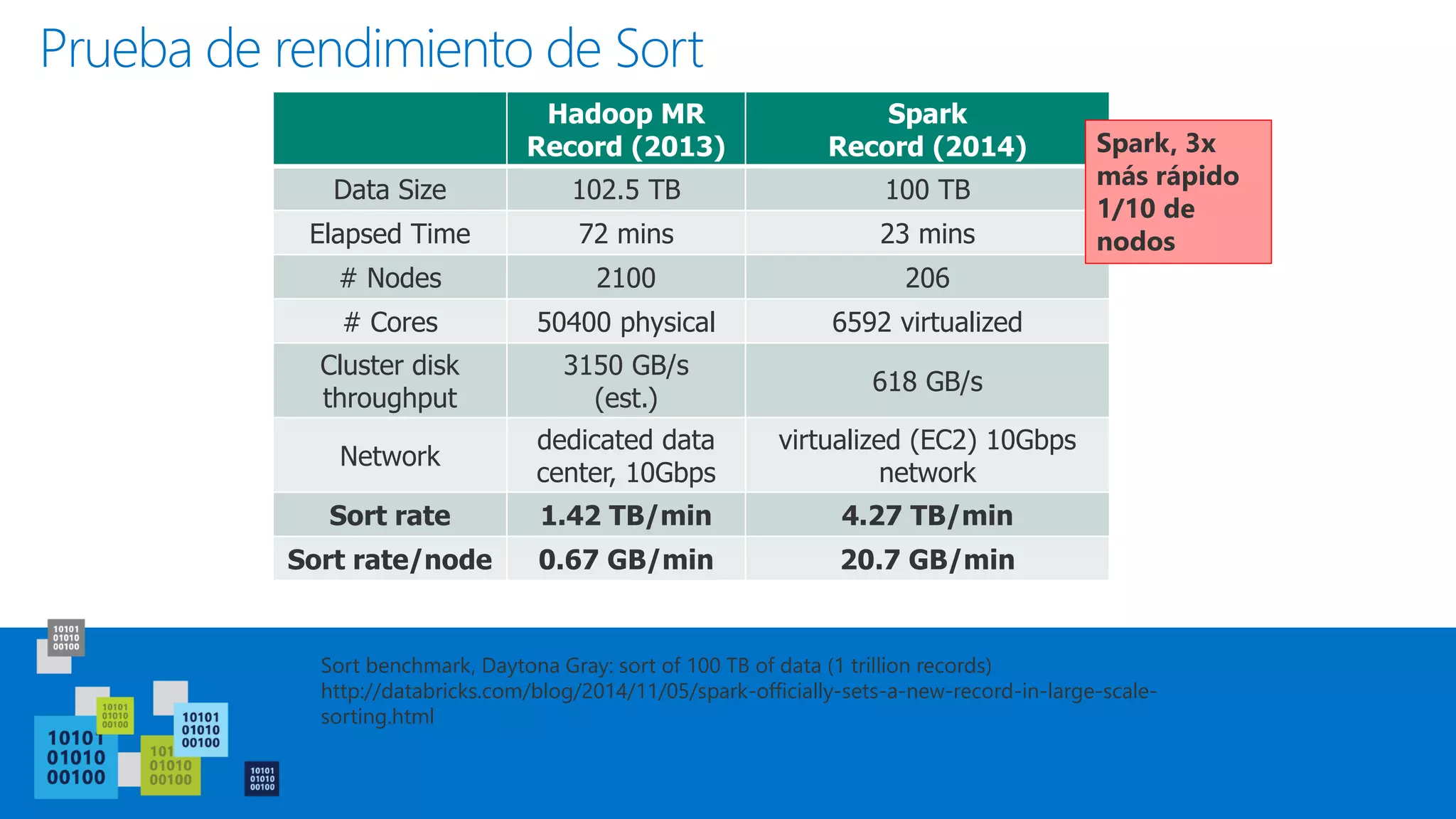
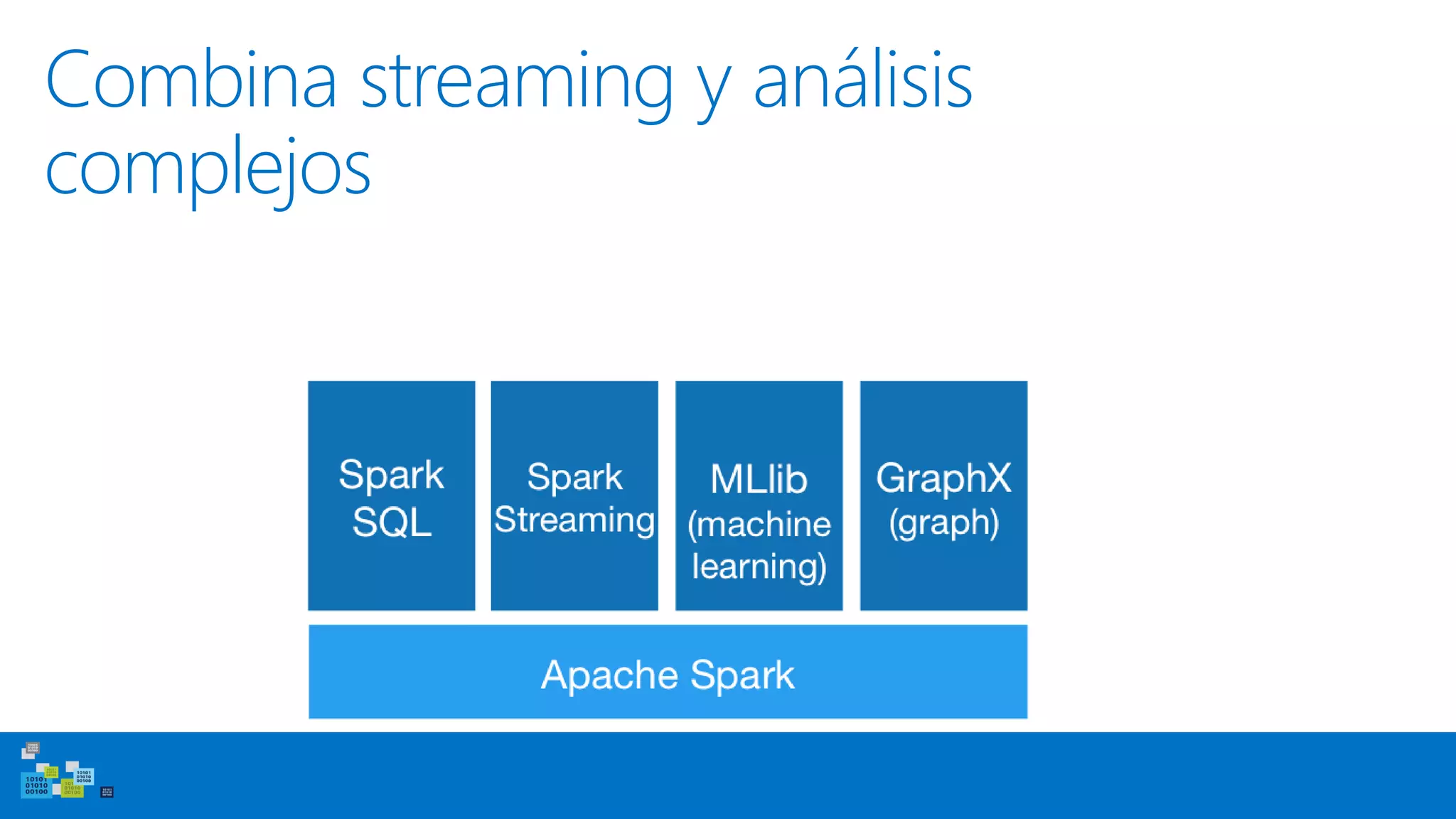
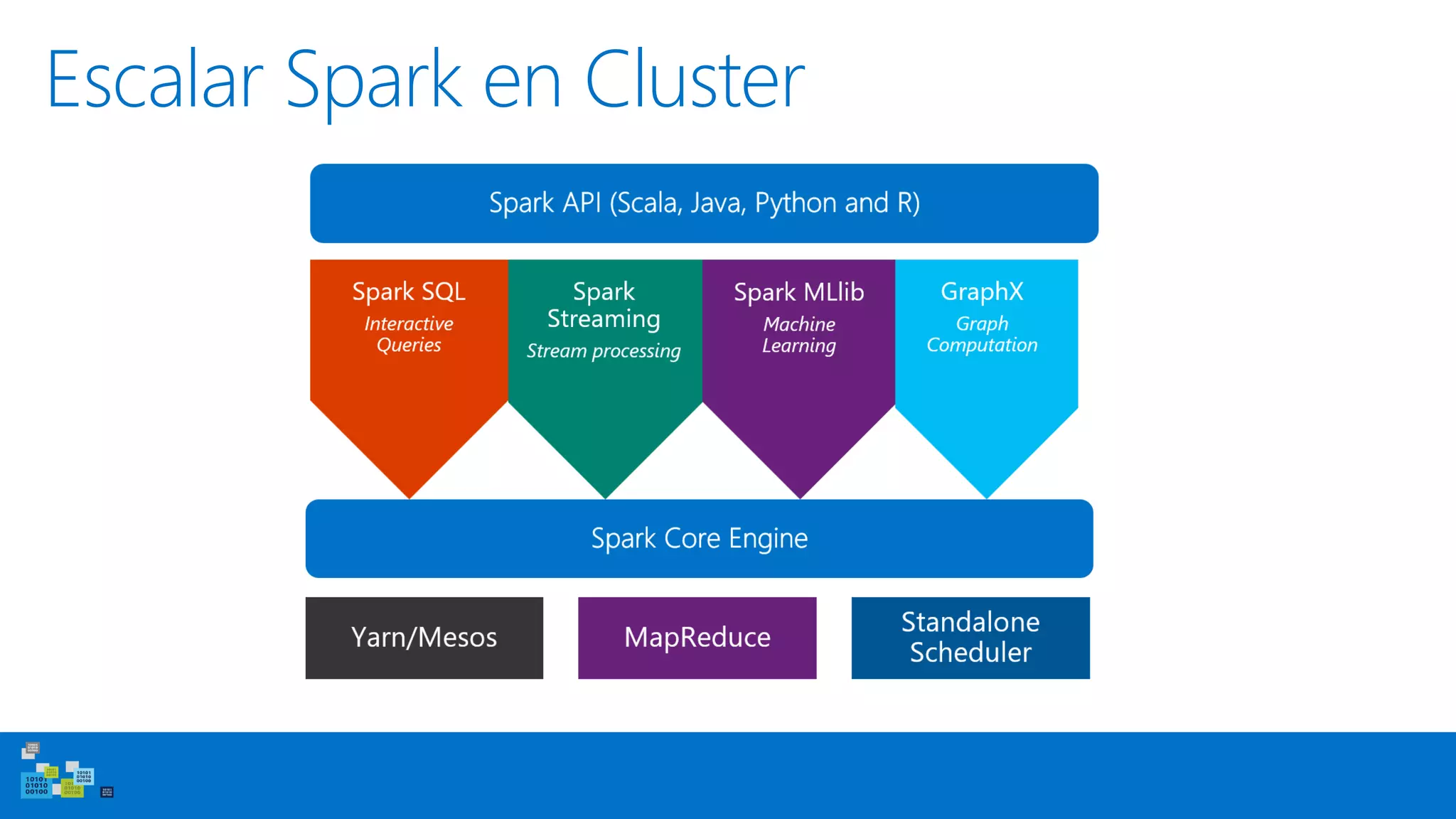
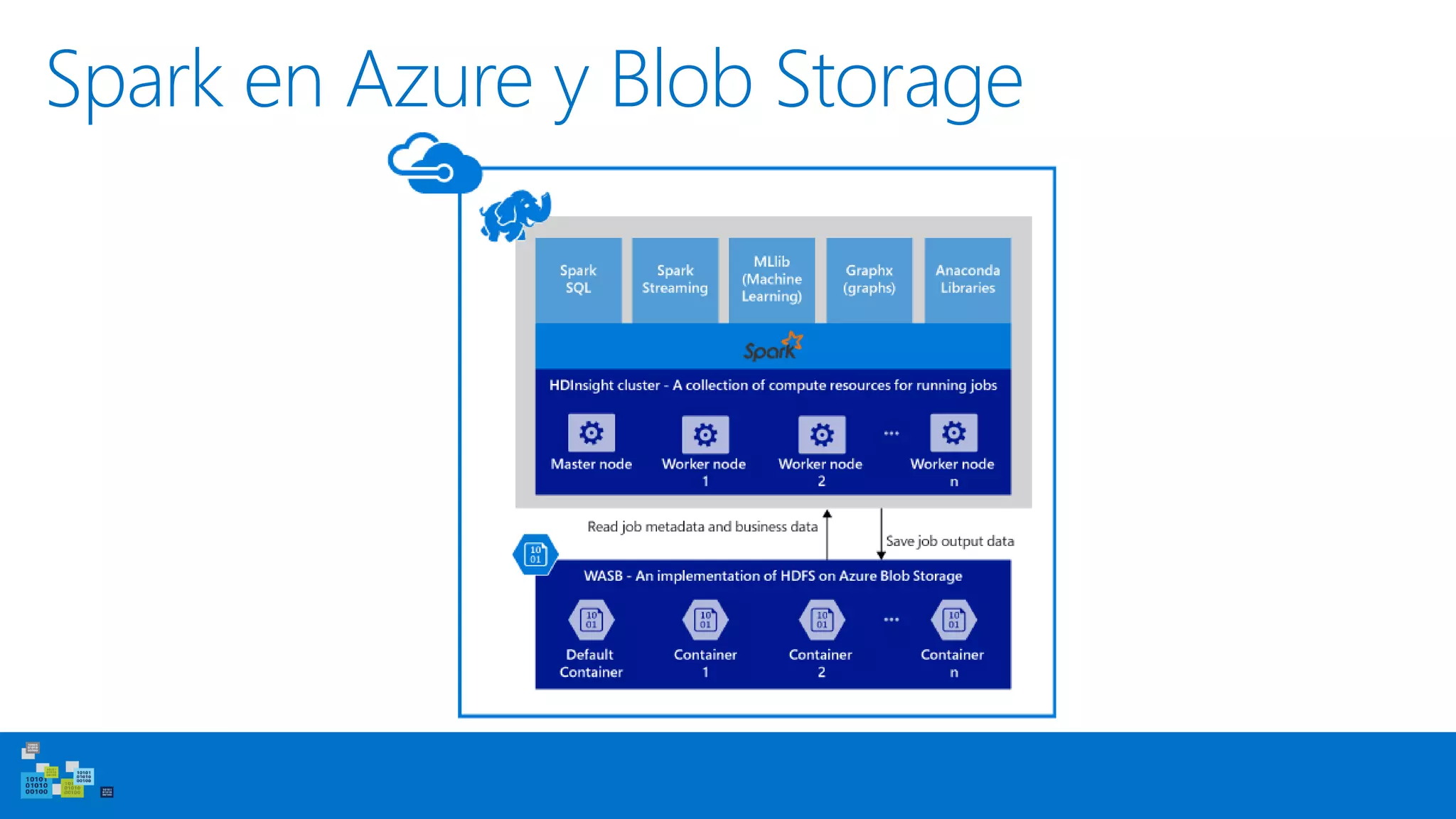
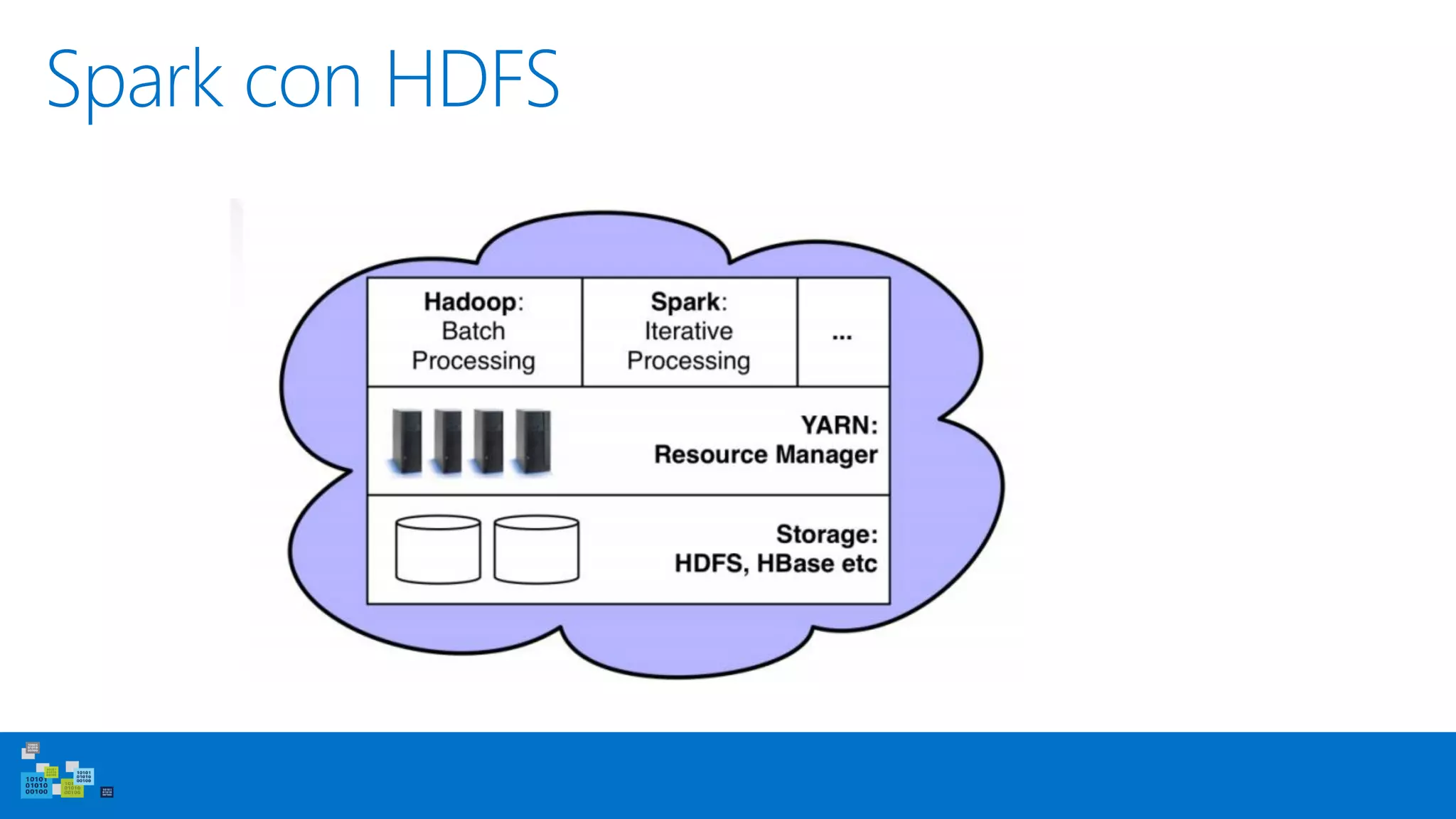
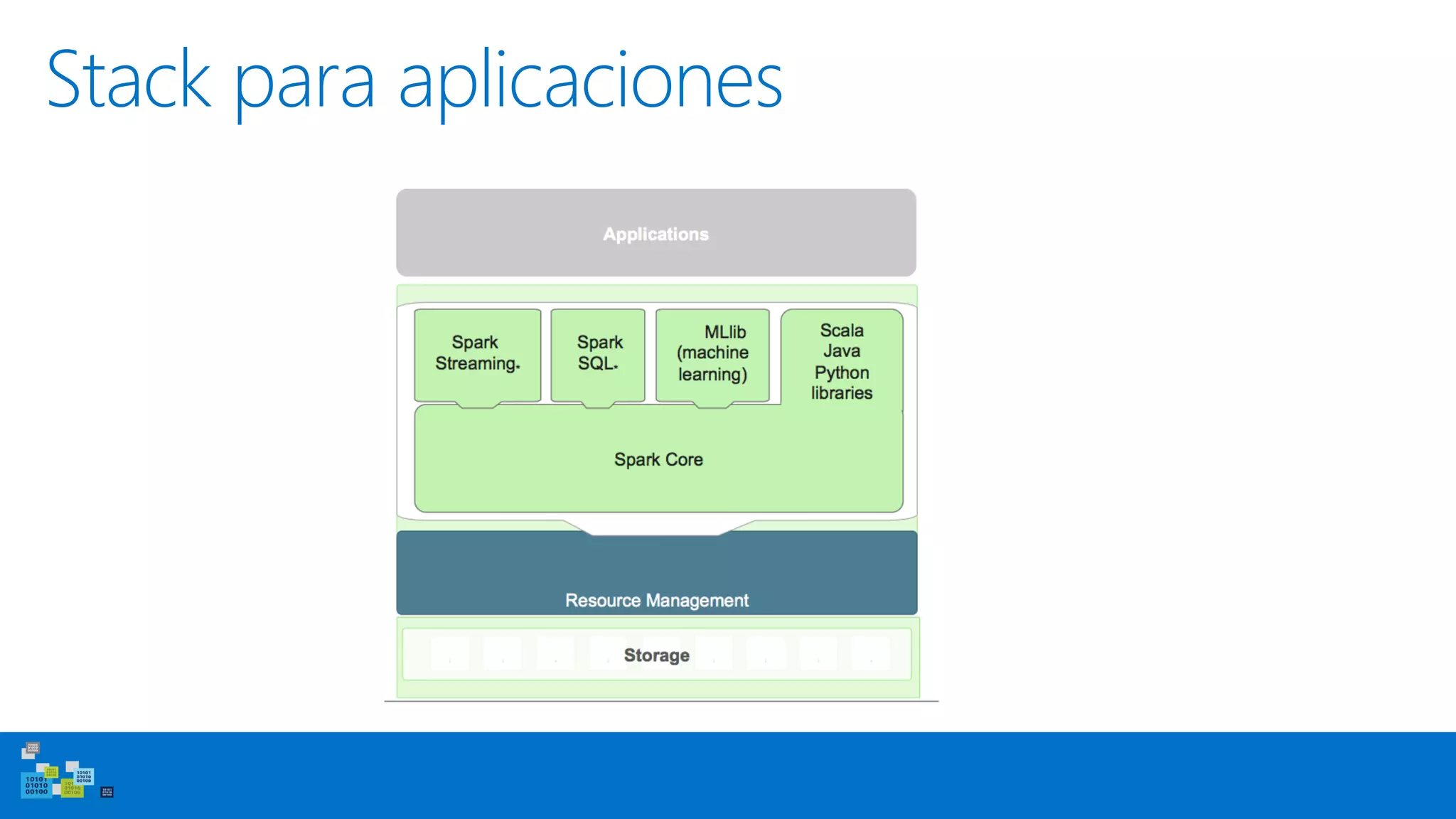
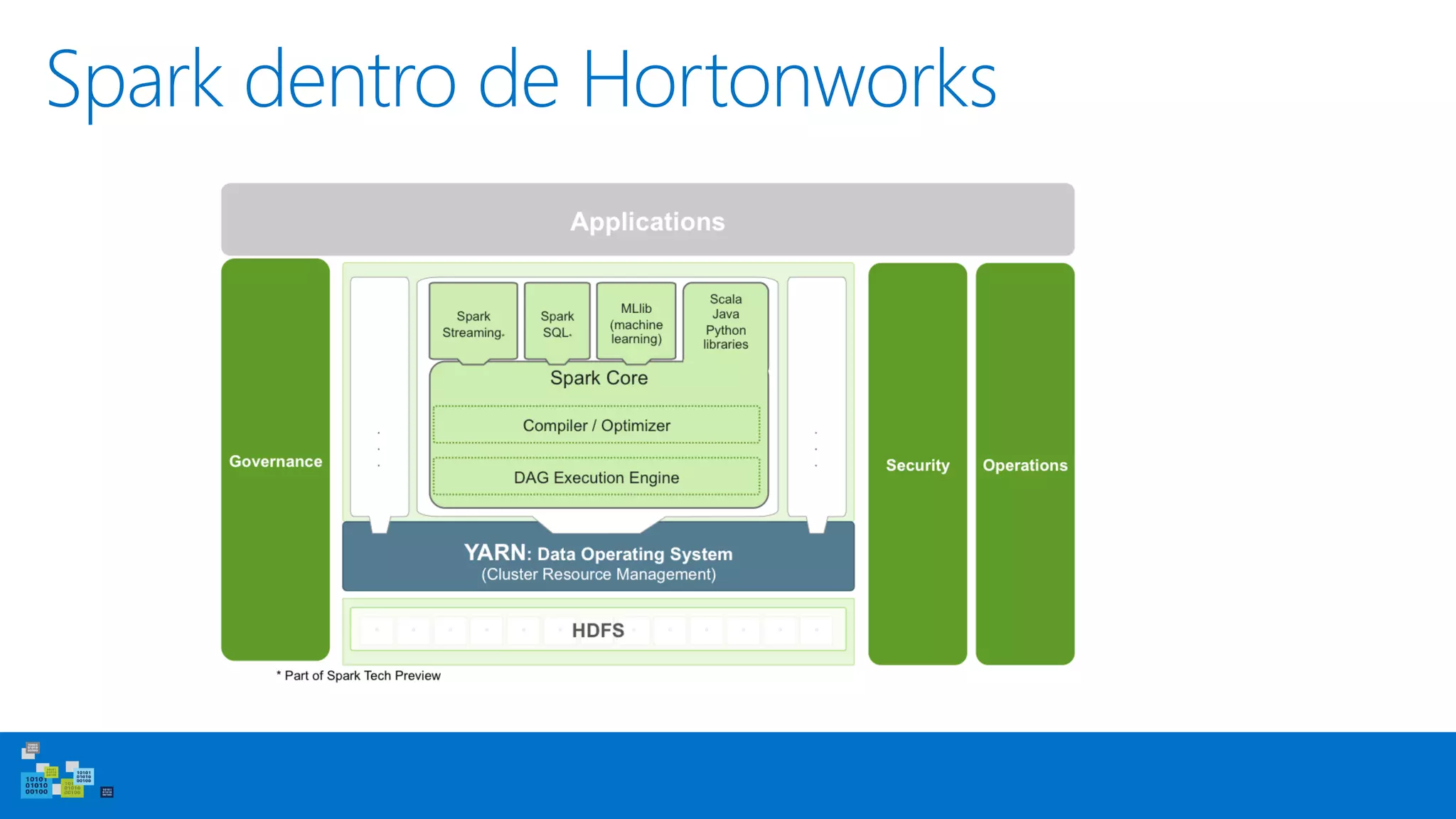
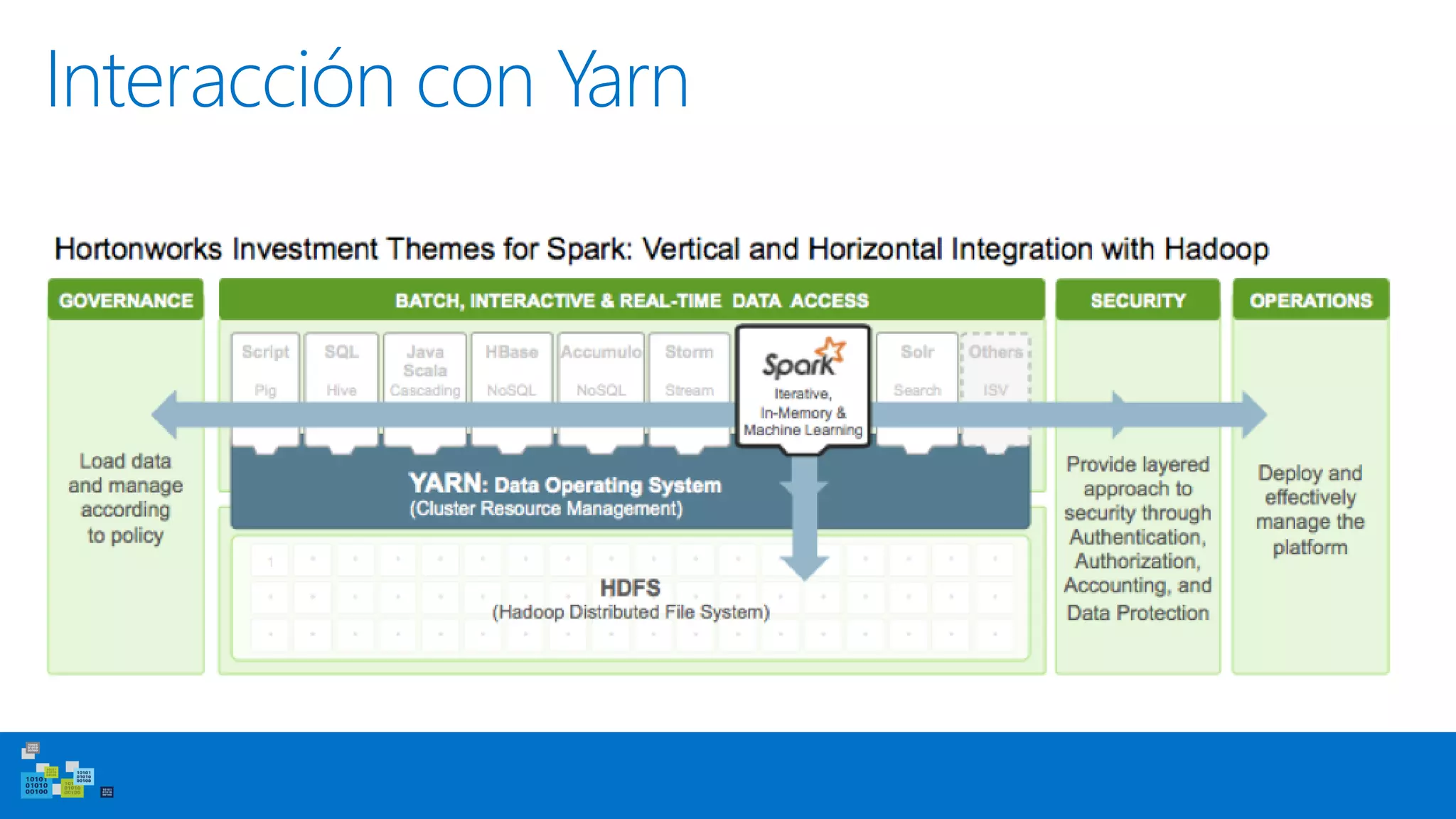
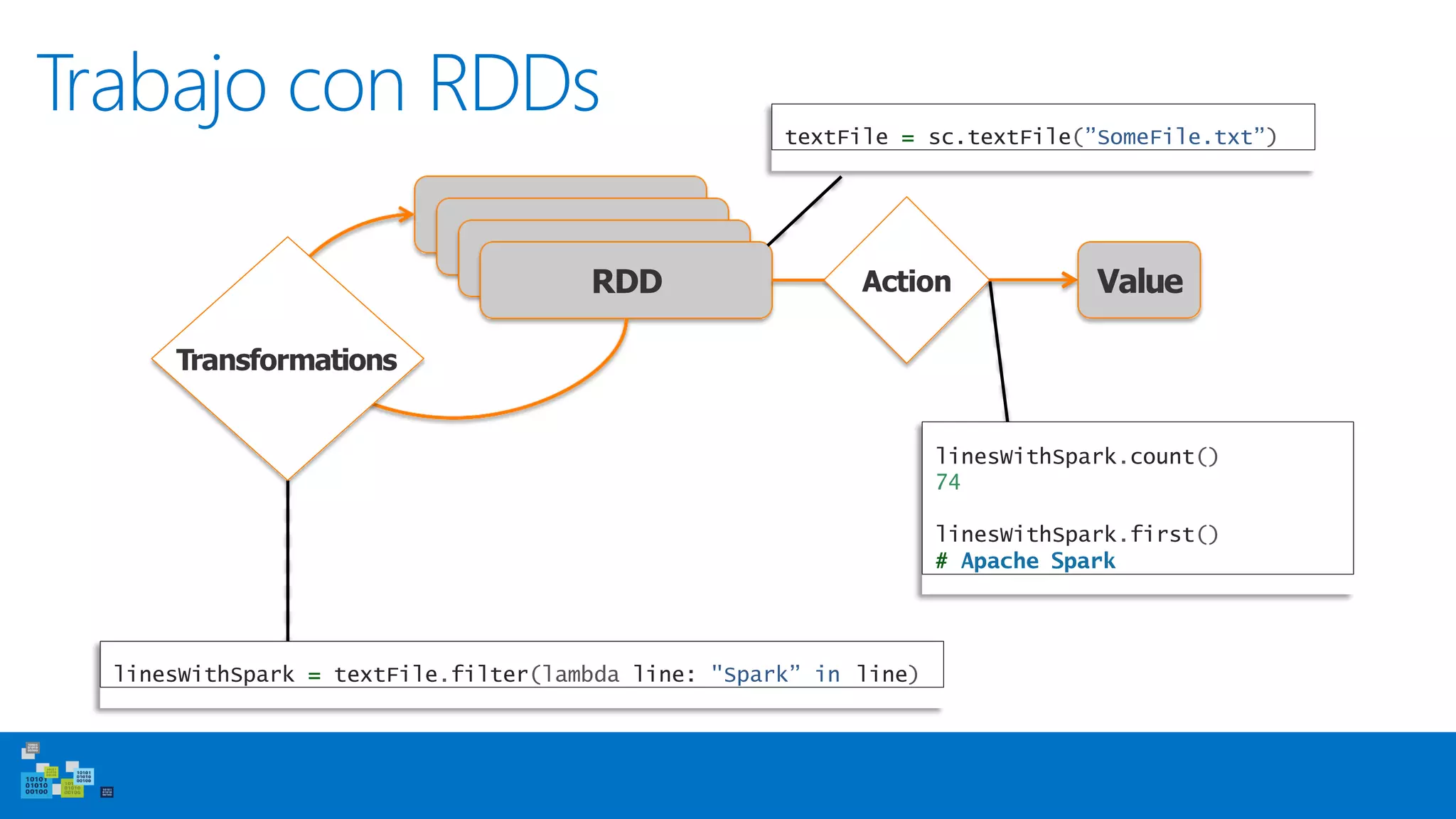
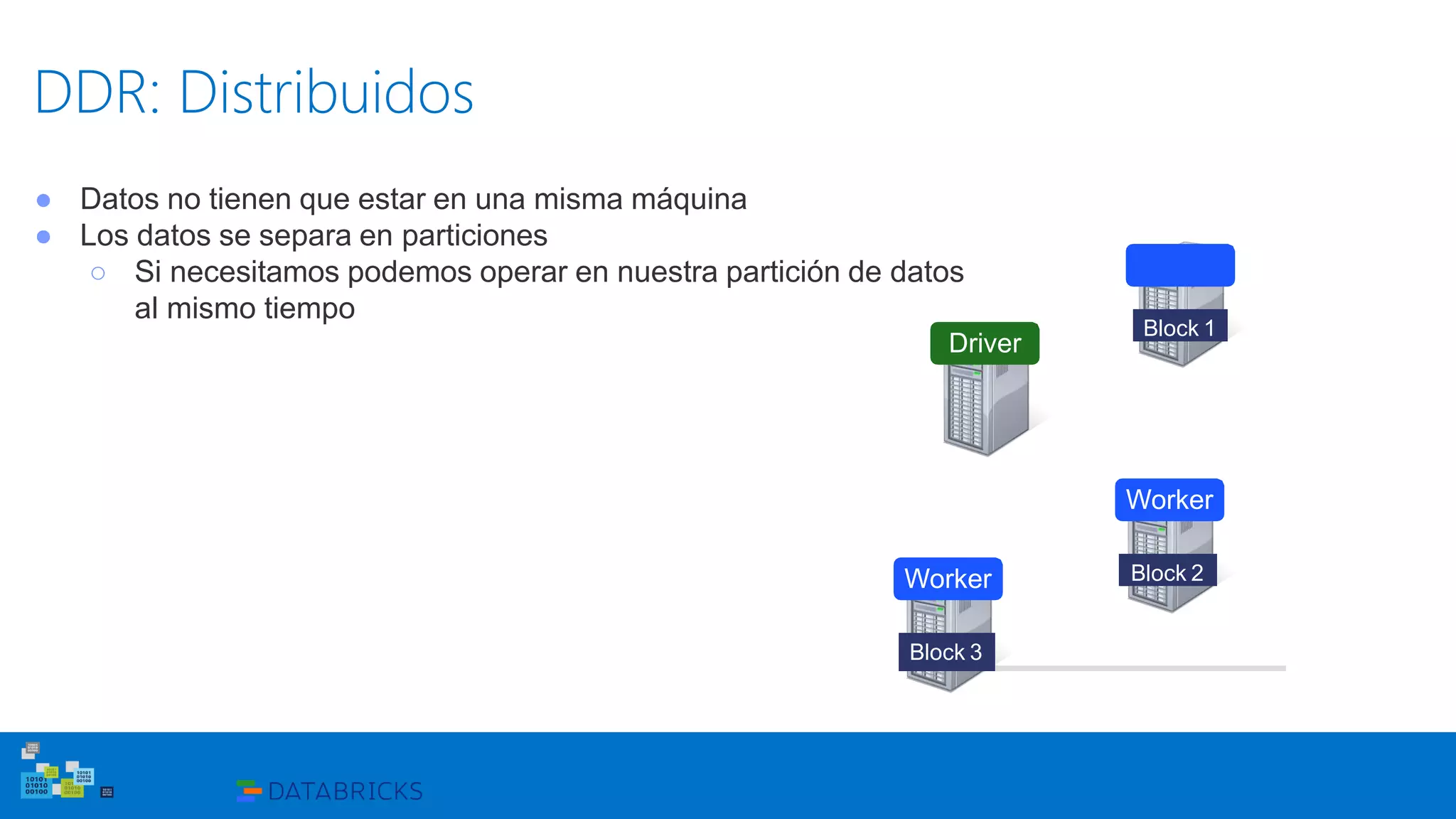
Este documento introduce Apache Spark, un sistema de computación de clústeres rápido y expresivo. Spark es más rápido que Hadoop, ya que almacena datos en memoria para consultas iterativas. Spark es compatible con Hadoop y puede leer y escribir datos en cualquier sistema soportado por Hadoop como HDFS. Spark usa Resilient Distributed Datasets (RDD) que permiten transformaciones paralelas sobre colecciones distribuidas de datos.



































































