Descargado 28 veces



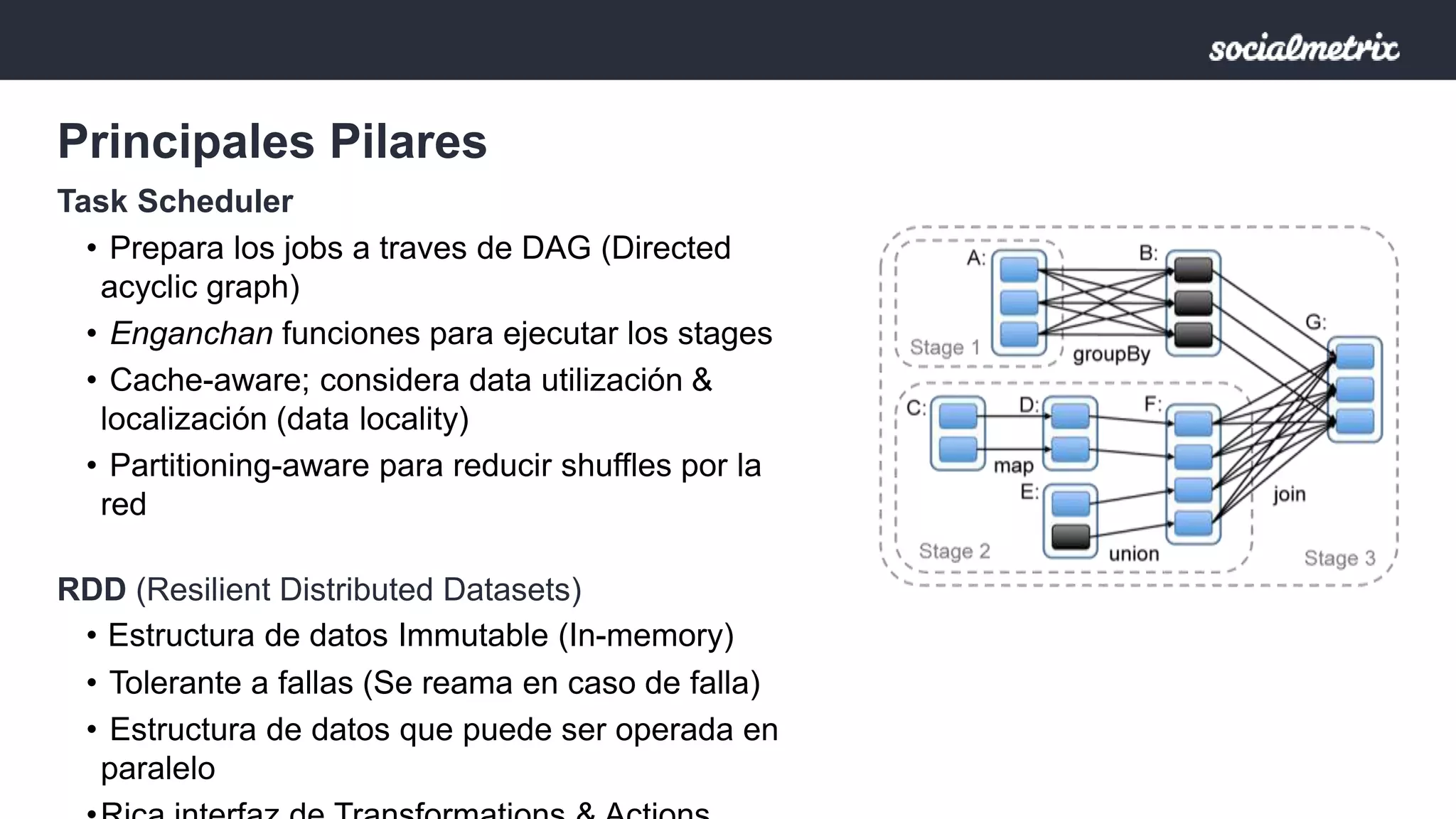

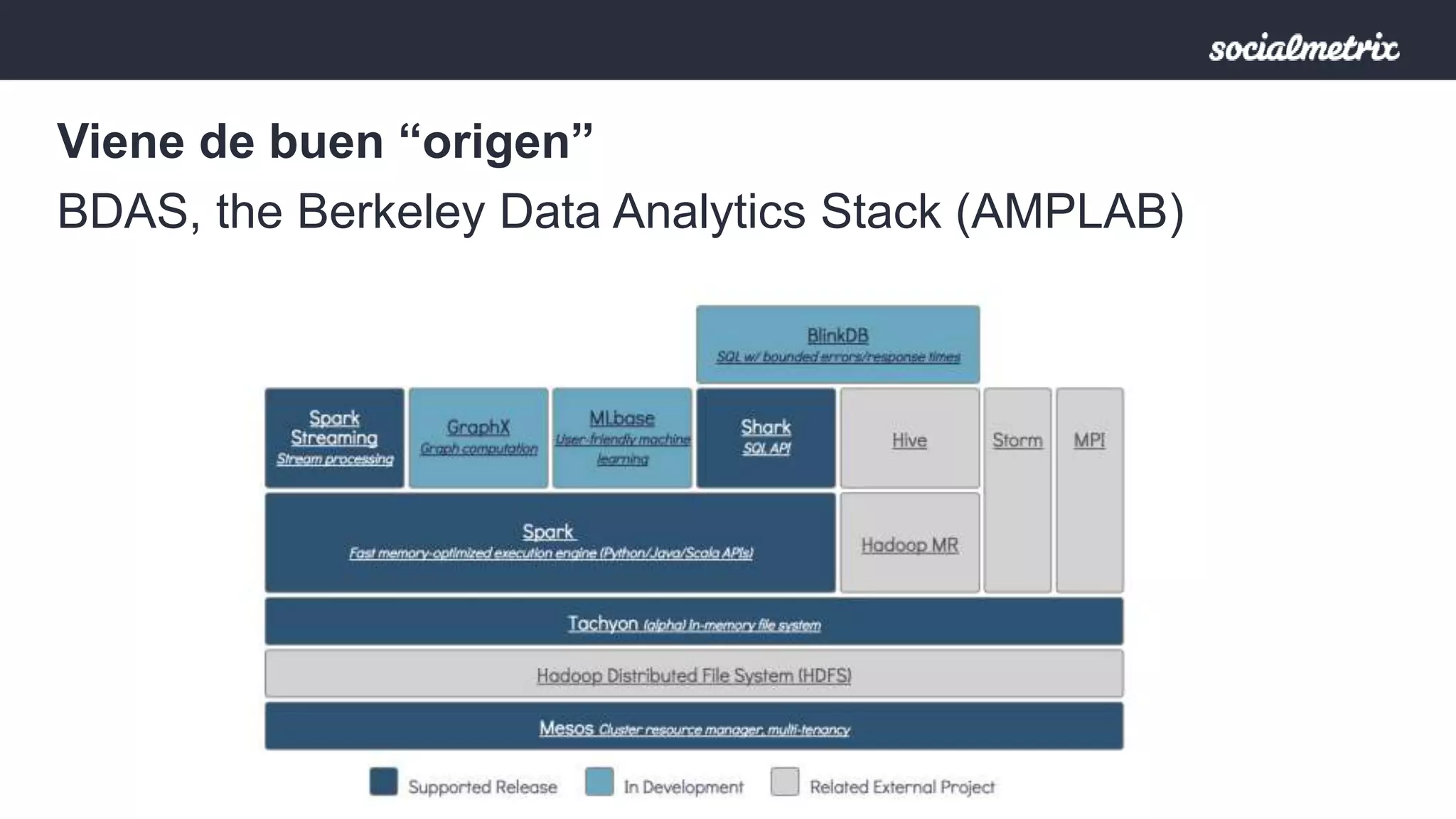
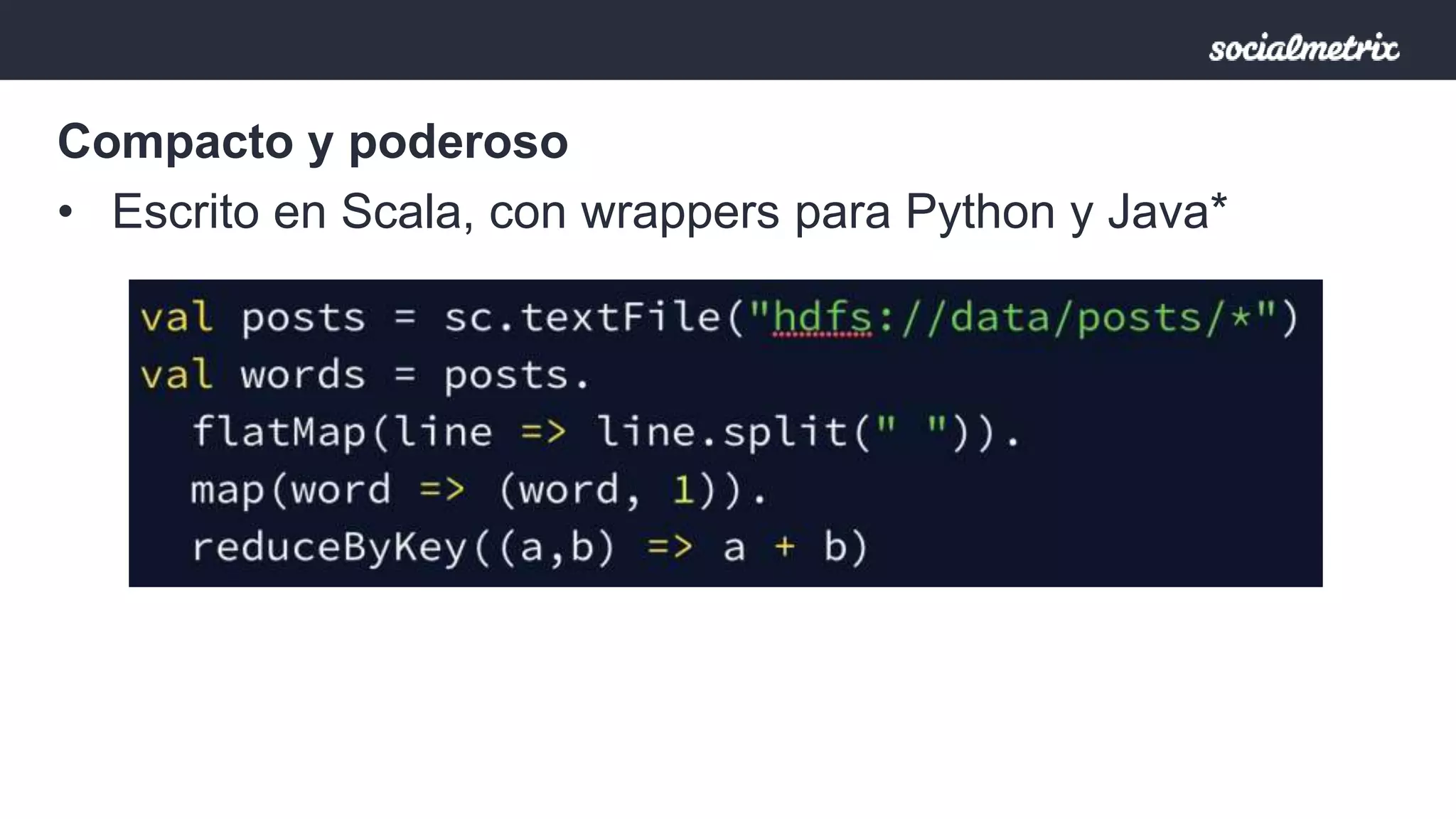

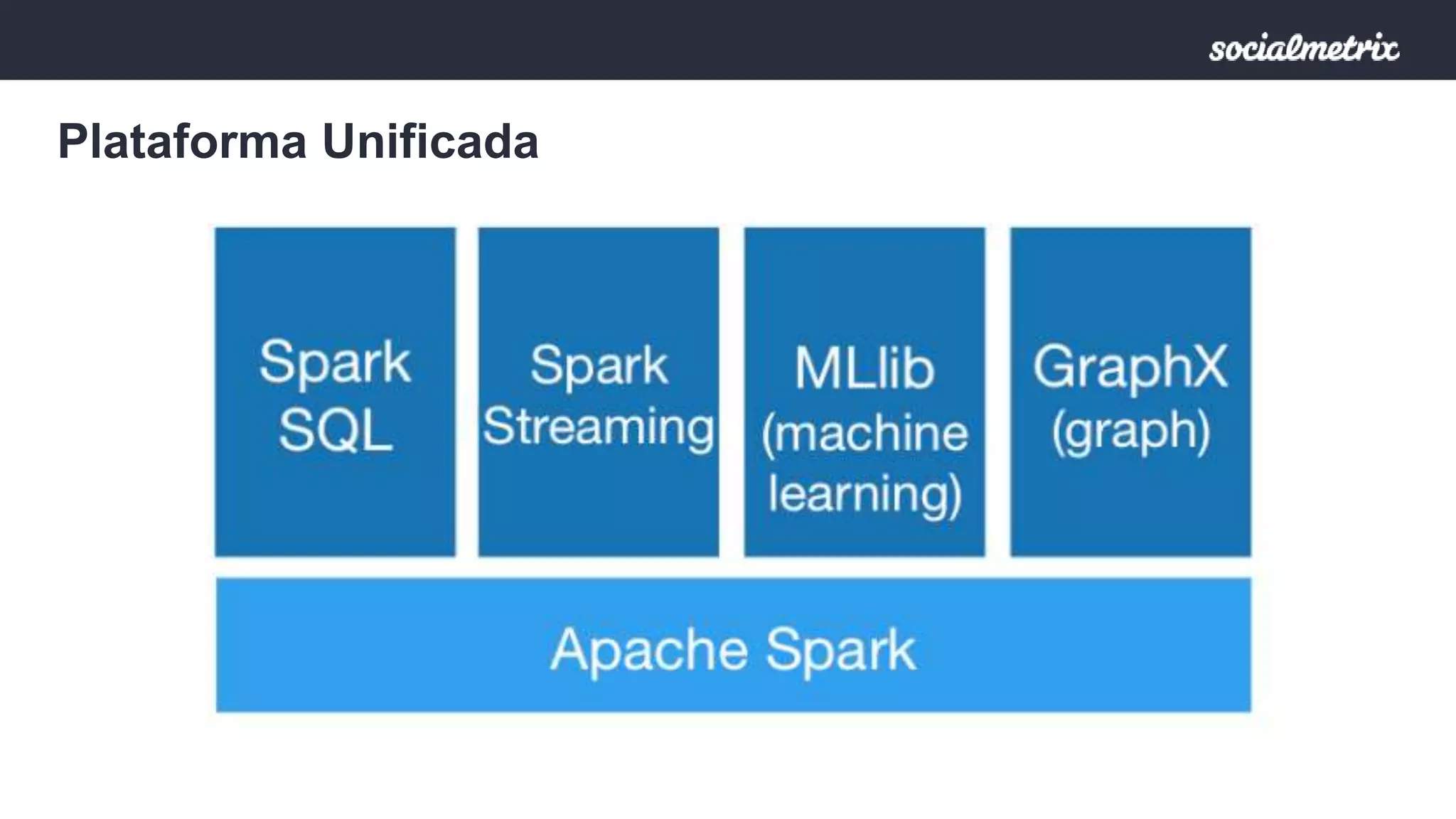
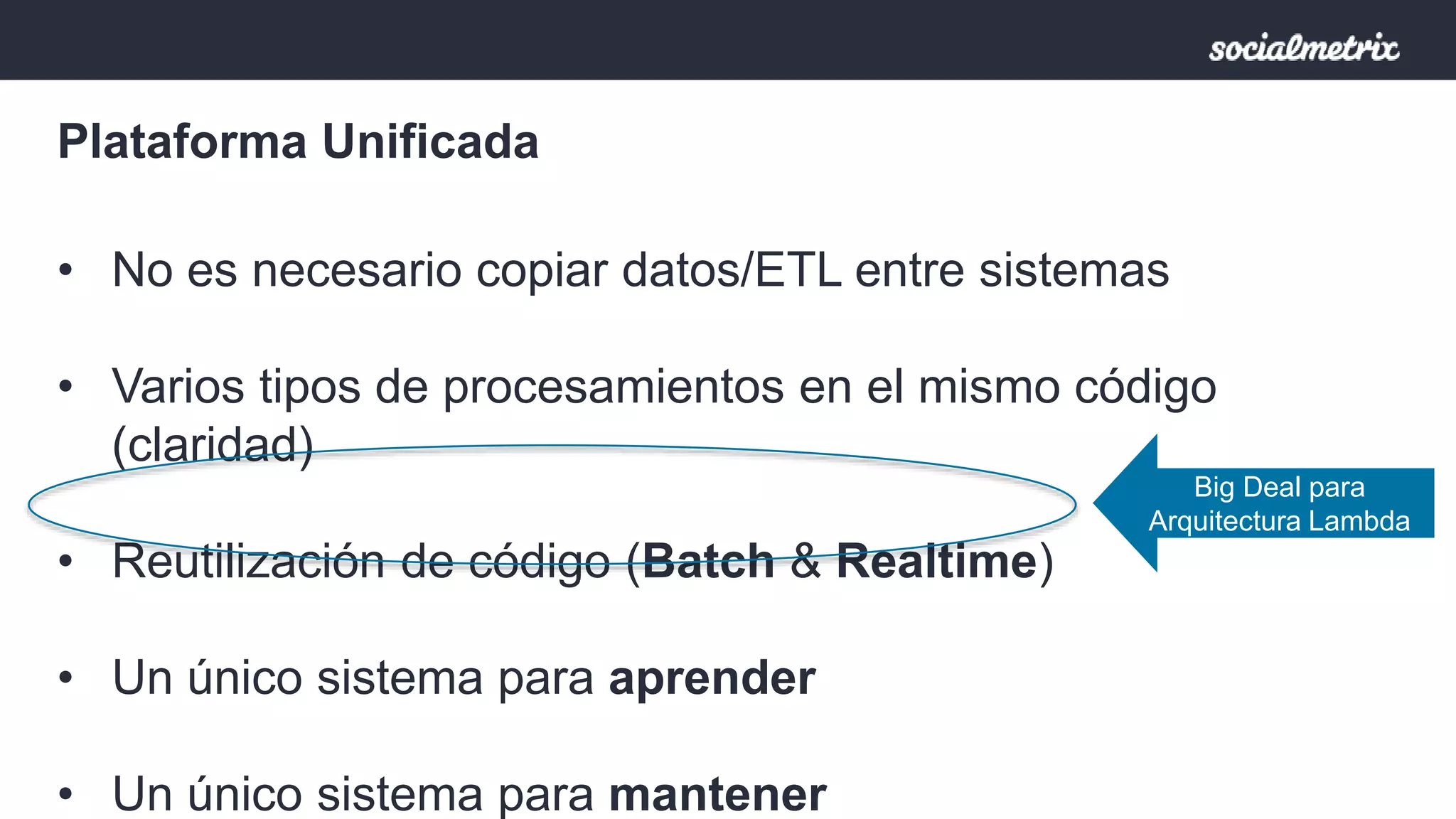
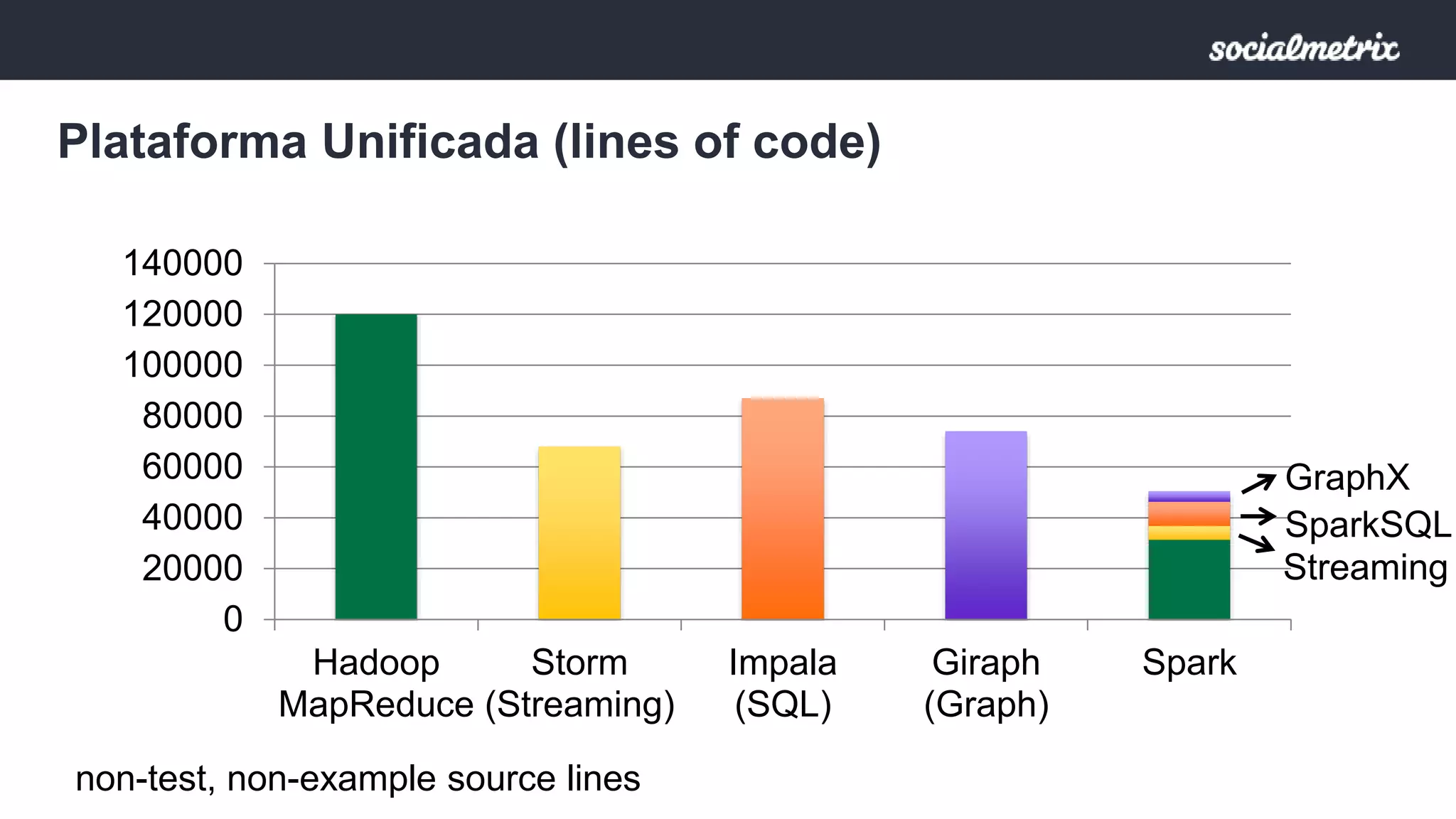
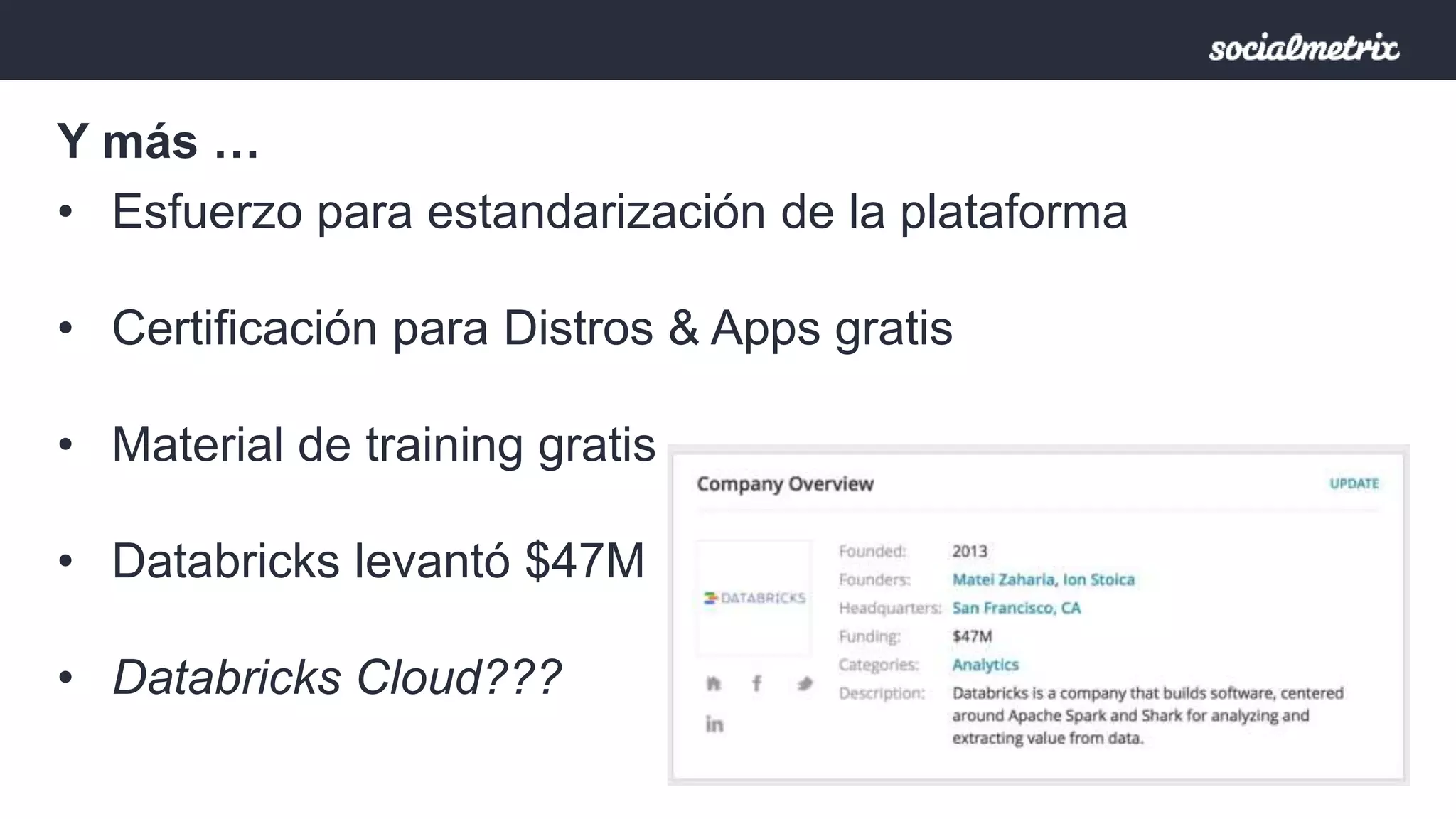

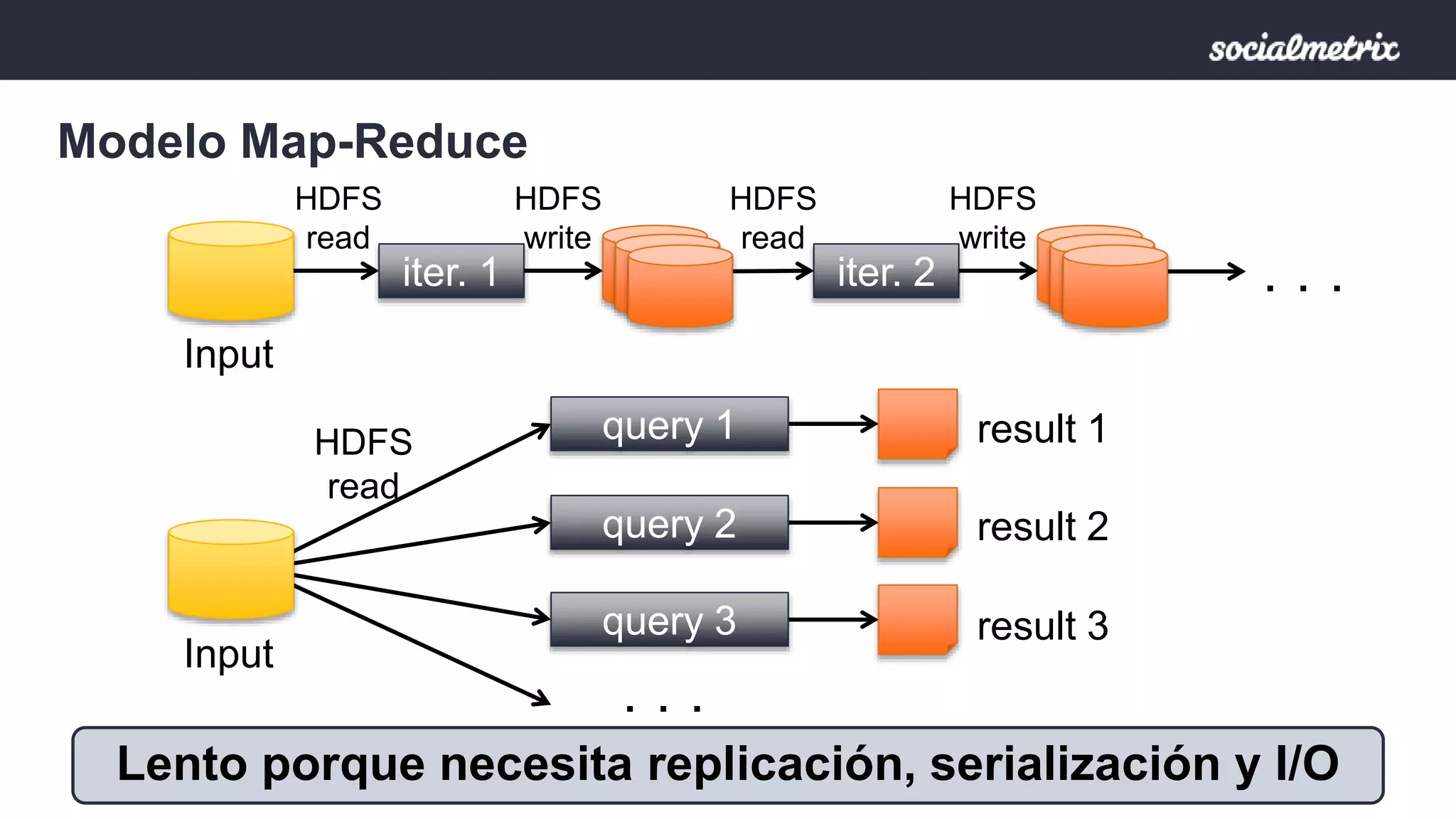
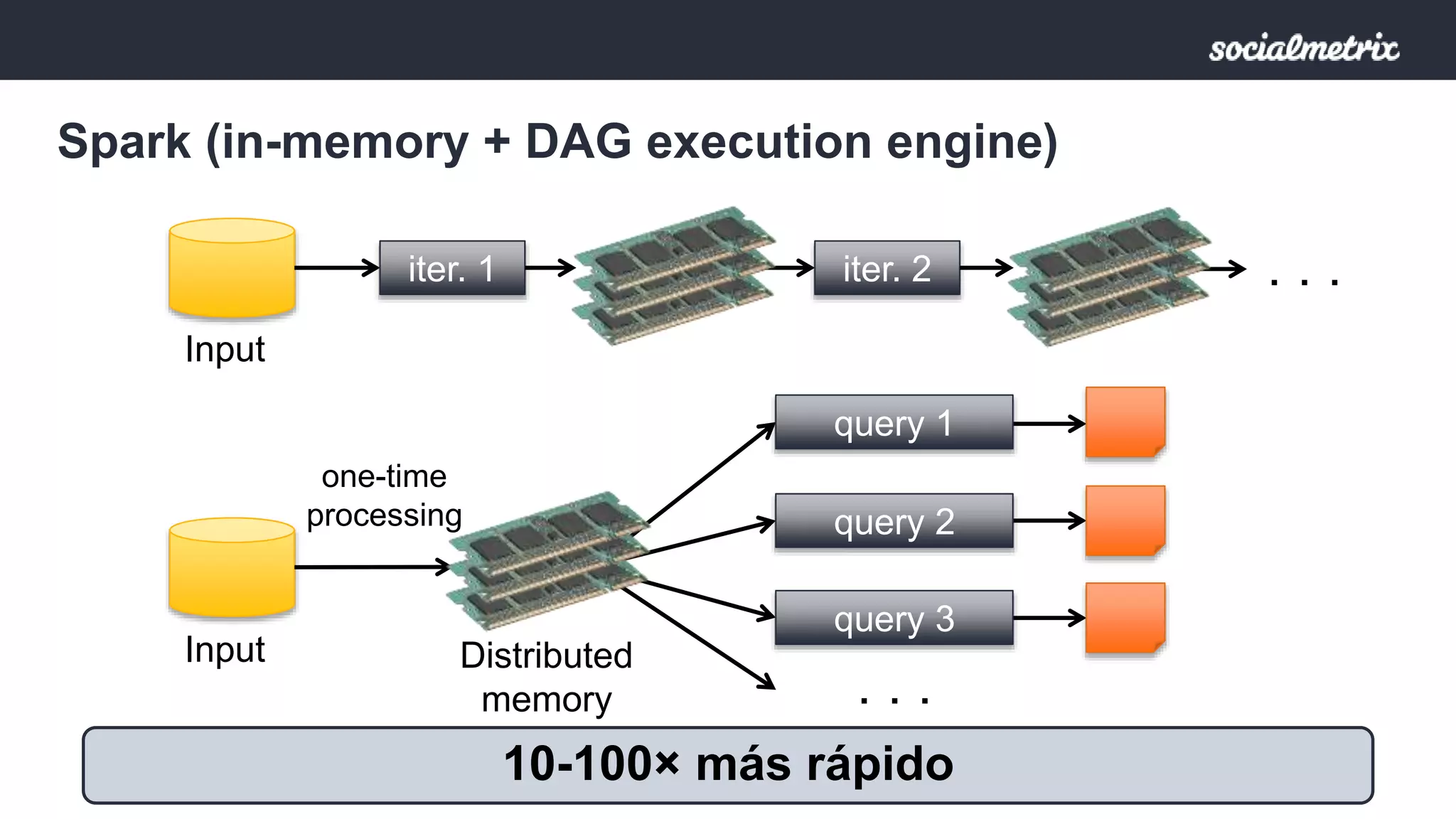
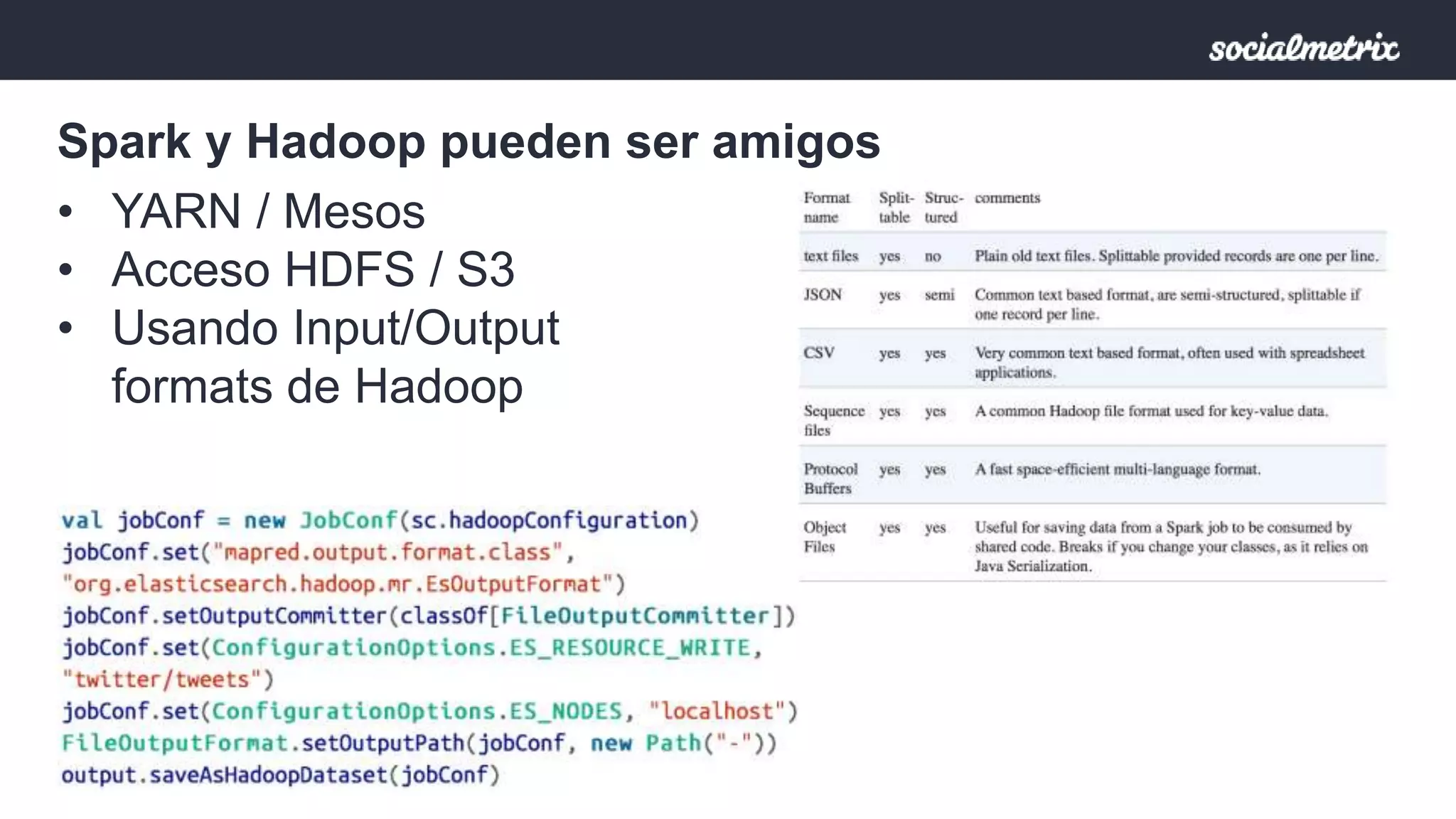





Apache Spark es un motor de procesamiento de datos rápido y general para grandes volúmenes de información, con capacidades de procesamiento in-memory y un marco unificado para ingenieros y científicos de datos. Ofrece una interfaz rica para transformaciones y acciones a través de RDD, es tolerante a fallas, y permite la reutilización de código para diversos tipos de procesamiento. Su arquitectura permite un rendimiento notable, siendo 10-100 veces más rápido que Hadoop debido a su ejecución basada en DAG y uso de memoria distribuida.





























































