Descargar como PDF, PPTX













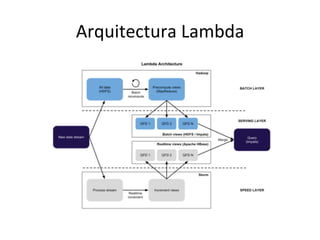

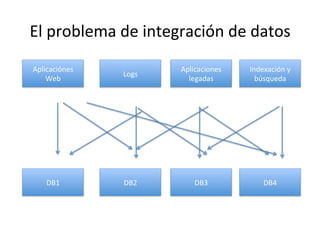


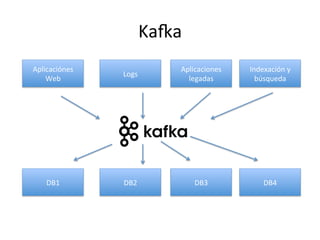
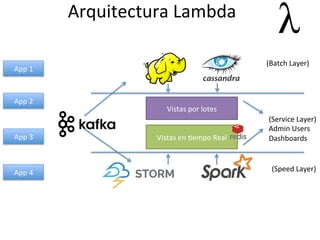









Este documento describe la arquitectura Lambda, la cual consta de tres capas (batch, servicio y velocidad) para procesar datos por lotes y en tiempo real. También explica cómo tecnologías como KaRa, Spark y Redis pueden usarse para integrar datos de múltiples fuentes, procesar flujos de datos y mostrar métricas en tiempo real.
























































