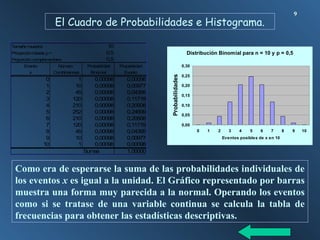
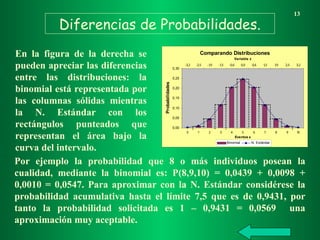
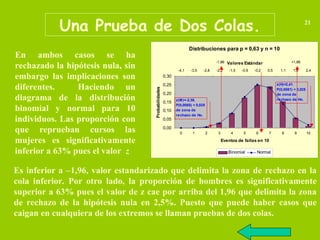
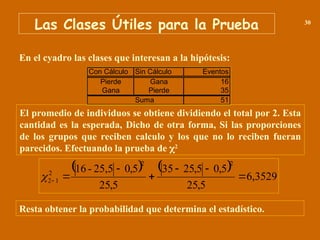
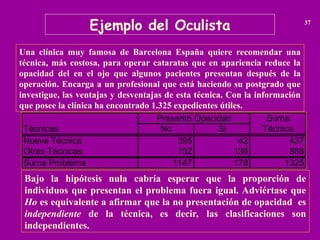
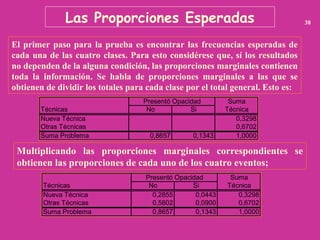
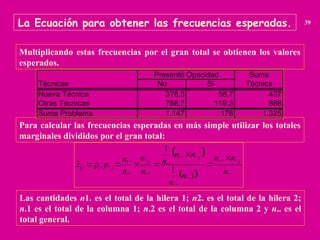
La estadística chi-cuadrado (χ²) es una prueba estadística utilizada para determinar si existe una asociación significativa entre variables categóricas. Se utiliza para comparar las frecuencias observadas con las frecuencias esperadas bajo la hipótesis nula de independencia entre variables. En resumen, evalúa si las diferencias entre lo que se observa y lo que se espera son suficientemente grandes para rechazar la hipótesis de independencia