Este documento presenta un libro sobre estadística aplicada a las ciencias sociales. El libro contiene capítulos sobre la organización y representación gráfica de datos, medidas descriptivas básicas, la distribución normal, tipos de puntuaciones individuales y correlación y covarianza. El documento incluye el índice del libro con una lista de los temas cubiertos en cada capítulo.
































![CAPÍTULO 2
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA
CENTRAL Y DE DISPERSIÓN
1. MEDIDAS DE TENDENCIA CENTRAL
1.1. La media aritmética
Todos estamos familiarizados con la media aritmética como valor repre-
sentativo de un conjunto de puntuaciones; con frecuencia describimos un
grupo de manera sintética diciendo cuál es su media; si estamos hablando de
una clase no es lo mismo decir esta clase tiene una media de 7, que decir en
esta clase la media es 5…
La fórmula de la media no necesita demostración porque expresa el mis-
mo concepto de media: cuánto correspondería a cada sujeto (u objeto) si to-
dos tuvieran el mismo valor: sumamos todos los valores y dividimos esta su-
ma por el número de sujetos.
兺X
Media aritmética: X= –––– [1]
N
El símbolo habitual de la media es el mismo utilizado en las puntuaciones
directas (generalmente una X mayúscula) con una raya horizontal encima
(pero también se utilizan otros símbolos como la letra M).
De la media podemos enunciar dos propiedades que también nos podrían
servir para definirla.
a) Si a cada sujeto le calculamos su diferencia con respecto a la media (X-
X), la suma de estas diferencias es igual a cero: la suma de las diferen-
cias positivas es igual a la suma de las diferencias negativas.
35](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-35-320.jpg)







![Fórmulas
Distinguimos dos fórmulas según se trate de la desviación típica de la
muestra o de una estimación de la desviación típica de la población represen-
tada por esa muestra.
1º Cuando se trata de la desviación típica que describe la dispersión de
una muestra (que es lo que hacemos normalmente) utilizamos la fór-
mula [3]:
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
43
s = desviación típica de la muestra
S = sumatorio, suma de (letra ese griega
mayúscula)
X = cada una de las puntuaciones individua-
les (X mayúscula),
X = media aritmética
N =número de sujetos
[3]
[4]
La fórmula de la desviación típica también suele expresarse así:
(d = desviaciones con respecto a la media) o también
La letra x (equis minúscula) es un símbolo habitual de la puntuación di-
ferencial de cada sujeto, que es simplemente la desviación o diferencia de ca-
da sujeto con respecto a la media, d = x = X
2º Cuando se trata de la estimación de la desviación típica de la pobla-
ción representada por una muestra se utiliza la fórmula [4].
La fórmula es casi idéntica; dividimos por N-1 (en
vez de por N) con lo que el valor de la desviación
típica será algo mayor.
En este caso se trata de la estimación de la desviación típica de una pobla-
ción calculada a partir de los datos de una muestra. Al dividir por N-1 (y dis-
minuir el denominador) aumenta el cociente: la desviación típica de una po-
blación suele ser mayor que la desviación típica de una muestra, porque al
aumentar el número de sujetos es más probable que haya sujetos con puntua-
ciones muy extremas (o muy altas o muy bajas) y consecuentemente aumenta-](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-43-320.jpg)
![De estas fórmulas es de especial utilidad la [6] porque algunos programas
de ordenador dan rutinariamente la desviación típica de la población (sn-1)
cuando la que con frecuencia interesa es la desviación típica que describe la
dispersión de la muestra (sn).
2.2.2. La varianza
1. La varianza es simplemente la desviación típica elevada al cuadrado:
rá la desviación típica. Con números grandes apenas hay diferencia (a efectos
prácticos da lo mismo dividir por 100 que dividir por 99), pero con números
muy pequeños la diferencia puede ser importante3
.
De la fórmula [3] (dividiendo por N) a la [4] (dividiendo por N-1) y vice-
versa se pasa con facilidad. La desviación típica [3] la simbolizamos ahora co-
mo sn y la desviación típica de la fórmula [4] la simbolizamos como sn-1 para
evitar confusiones.
El paso de [3] a [4] se capta con facilidad. Si despejamos S(X - X)2
en la
fórmula [3] tenemos que y substituyendo S(X - X)2
por
en la fórmula [4] tendremos que:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
44
3
En EXCEL (herramientas) en análisis de datos (estadística descriptiva) calcula la
desviación típica de la población (dividiendo por N-1) lo mismo que en el SPSS (por defecto).
[5] y de manera análoga tenemos que [6]
Podemos ver estas transformaciones en un sencillo ejemplo:
Tenemos estas tres puntuaciones 8, 12 y 14 (N = 3) cuyas desviaciones
son: sn = 2.494
sn-1 = 3.055
sn a partir de sn-1:
sn-1 a partir de sn](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-44-320.jpg)




![puntuación máxima posible - puntuación más baja posible
–––––––––––––––––––––––––––––––––––––––––––––––––– [8]
2
Por ejemplo hacemos un pregunta con cinco respuestas (5 = totalmente de
acuerdo, 4 = de acuerdo, 3 = indiferente, 2 = en desacuerdo y 1 = en total
desacuerdo), la puntuación máxima posible es 5 y la puntuación más baja po-
sible es 1; en este caso la desviación típica mayor posible es (5 - 1)/2 = 2.
Esta referencia suele ser poco útil porque este valor máximo es difícilmen-
te alcanzable en la mayoría de las situaciones. Cuando los valores son 1 y 0 (sí
o no, bien o mal, etc.), la desviación típica mayor posible es (1 - 0)/2 = .50.
Esta referencia con este tipo de datos es especialmente útil, porque en estos
casos (respuesta 1 ó 0) sí es más frecuente que la desviación típica obtenida
sea la mayor posible o se aproxime mucho a la mayor posible (ampliamos es-
tos comentarios al tratar después de las puntuaciones dicotómicas).
4. La desviación típica indica qué puntuación parcial pesa más en una me-
dia final; a mayor desviación típica, mayor peso en la media final. En determi-
nadas situaciones esta información puede ser muy útil.
El que la puntuación parcial con una mayor desviación típica pese más en
una media final es por otra parte lógico: si todos reciben la misma o casi la
misma puntuación (lo que supone una desviación típica muy pequeña), no se
establecen diferencias; si por el contrario se asignan puntuaciones muy distin-
tas a los sujetos (desviación típica grande) en una puntuación parcial, las dife-
rencias en la media final dependerán más de esas ocasiones en las que se asig-
naron puntuaciones (o notas) muy distintas.
Lo podemos ver intuitivamente con un ejemplo ficticio (tabla 7). Suponga-
mos que tres examinadores (A, B y C) califican a tres sujetos en lo mismo (en-
tre paréntesis el número de orden de cada sujeto con cada examinador y en
la media final):
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
49
Tabla 7
Podemos observar que el orden (entre paréntesis) de los alumnos en la
media final coincide con el orden del examinador A, que es el que tiene una
mayor desviación típica.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-49-320.jpg)

![La media (X) de los datos dicotómicos es igual a la proporción de res-
puestas correctas o de unos, y el símbolo que suele utilizarse es p.
El concepto de media es el mismo que cuando se trata de otros tipos de pun-
tuaciones: calculamos la media sumando todas las puntuaciones individuales
(que en este caso serán 1 ó 0) y dividimos esta suma por el número de sujetos.
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
51
Figura 2:
EJEMPLOS DE DATOS DICOTÓMICOS
número de unos
Por lo tanto la media es: p = proporción de unos =––––––––––––––– [9]
N
La proporción de ceros (de respuestas incorrectas, de noes, etc.) se sim-
boliza como q, y es igual al número de ceros dividido por el número de suje-
tos, o más sencillamente, q = 1-p, ya que p + q = 1 (ó síes + noes o unos +
ceros = el 100% de las respuestas).
número de ceros
q = proporción de ceros = ––––––––––––––– [10]
N
Si, por ejemplo, de 50 sujetos 30 responden sí (o bien en la pregunta de
un examen) y 20 responden no (o mal a una pregunta):
30
La media será: p =–––––= .60
50
20
El valor de q será: q =–––––= .40
50
Si multiplicamos por cien la proporción de respuestas correctas (p), tene-
mos un tanto por ciento o un porcentaje: el 60% ha respondido correcta-
mente (o ha respondido sí). Si los 50 sujetos responden sí (o correctamente),](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-51-320.jpg)
![ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
52
la proporción de unos (la media) será 50/50 = 1 (ó el 100% de los sujetos ha
respondido correctamente o ha respondido sí).
La desviación típica y la varianza de los datos dicotómicos (unos o ceros)
se puede calcular a partir de los valores de p y q:
Desviación típica: [11] Varianza: s2
= pq [12]
Es habitual utilizar pq como símbolo de la varianza de los datos dicotómi-
cos.
En el mismo ejemplo anterior, la desviación típica será igual a
= .489, y la varianza será igual a .4892
= .239 (ó .24 redondeando los decimales).
La varianza mayor posible se dará cuando el 50% responde correctamen-
te (o responde sí) y el otro 50% responde incorrectamente (o responde no),
es decir, cuando el 50% de las respuestas se codifica con un uno y el otro 50%
con un cero. Es entonces cuando se da el mayor número de diferencias inter-
individuales.
En este caso tenemos que p = q = .50;
la media es p =.50,
la desviación típica será igual a
la varianza será igual a .50
2
= .25,
También se utilizan los símbolos convencionales (X, s); sin embargo los
símbolos p (media), pq (varianza) y (desviación típica) son muy utiliza-
dos con este tipo de datos; realmente tanto pq como son las fórmulas
que también se utilizan como símbolos.
En los ítems dicotómicos el valor máximo que puede alcanzar la desviación tí-
pica es .50 y el valor máximo de la varianza es .502
=.25. Como ya se indicó an-
tes, el valor máximo que puede alcanzar la desviación típica (con cualquier tipo
de puntuación) es igual a la diferencia entre la puntuación máxima posible y la
puntuación más baja posible dividida por dos; en este caso (1-0)/2 = .50.
El que la máxima varianza con estos datos (1 ó 0) es .25 podemos verlo de
manera intuitiva en los datos simulados de la tabla 8, donde tenemos todos
los posibles resultados que podemos obtener si cuatro sujetos (N = 4) res-
ponden a una pregunta (respuestas: sí = 1, no = 0).
Si todos responden sí (1) o todos responden no (0), nadie se diferencia de
nadie y la varianza es cero. Si la mitad (el 50%) responde sí y la otra mitad res-
ponde no es cuando tenemos el máximo número de diferencias y la máxima va-
rianza. Si multiplicamos el número de los que responden sí por el número de
los que responden no tenemos el número de diferencias entre los sujetos, y si
multiplicamos las proporciones tenemos la varianza. La unanimidad (todos
responden sí o todos responden no) coincide con la varianza cero, y la máxima
diversidad coincide con la varianza máxima, que es (.50)(.50) = .25.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-52-320.jpg)
![Cuando las muestras son de idéntico tamaño calculamos la media de las
medias:
Cuando las muestras son de tamaño desigual:
La fórmula [13] es obvia (se trata de una media ponderada por el núme-
ro de sujetos):
Si la media es
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
54
tenemos que SX = XN; que es el numerador
de esta fórmula [13] (suma de todas las pun-
tuaciones); el denominador (SN) es la suma
de todos los sujetos de todos los grupos.
Cuando el número de sujetos es el mismo en todas las muestras, la media
total es simplemente la media de las medias.
Lo vemos en dos ejemplos (tabla 9), que utilizaremos también para ver có-
mo se combinan desviaciones típicas.
Tabla 9
2º Para combinar dos o más desviaciones típicas o varianzas:
Lo que no se puede hacer es calcular la media de las desviaciones típicas;
para combinar las desviaciones típicas de varios grupos como si se tratara de
un solo grupo aplicamos las fórmulas [14] (muestras desiguales) y [15]
(muestras iguales).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-54-320.jpg)
![a) Muestras de tamaño desigual
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
55
5
El numerador se calcula fácilmente con una calculadora con programación estadís-
tica, introduciendo todas las medias y todas las desviaciones típicas, en la función Sx2
.
stotal = desviación típica total, de todos los grupos unidos en uno solo;
Xtotal = media del total, de todos los grupos unidos en uno solo. 1º En
cada grupo multiplicamos cada N por la suma de la media y de
la desviación típica elevadas al cuadrado [N(X2
+ s2
)], 2º suma-
mos estos productos; 3º dividimos esta suma por el número to-
tal de sujetos (SN) y restamos la media total elevada al cuadra-
do (y que se supone calculada previamente). Si no extraemos la
raíz cuadrada, lo que tenemos es la varianza común a todos
los grupos.
b) Muestras de idéntico tamaño
Si las muestras son de idéntico tamaño, en la fórmula [14] tendríamos que
el denominador será Nk, donde N es el número de sujetos que hay en cada
grupo y k es el número de grupos, por lo que la fórmula [14] queda simplifi-
cada como se indica en [15].
En el numerador nos limitamos a sumar todas las medias y todas las
desviaciones previamente elevadas al cuadrado.
Con los datos mismos datos de la tabla 9 calculamos las desviaciones típi-
cas uniendo todas las muestras.
Muestras de tamaño desigual [14]:
Muestras de idéntico tamaño [15]5
:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-55-320.jpg)
![¿De dónde vienen estas fórmulas para combinar desviaciones típicas a
partir de los valores de las desviaciones, medias y número de sujetos de diver-
sos grupos?
La fórmula [14]6
es fácilmente demostrable, y no sobra conocer esta de-
mostración porque nos introduce en otras fórmulas frecuentes de la desvia-
ción típica.
La fórmula más directa de la desviación típica es
Esta fórmula no se demuestra en sentido propio (lo mismo que la de la
media aritmética), simplemente expresa el concepto.
Hay otras fórmulas, que se derivan de [16], para calcular la desviación típi-
ca sin necesidad de calcular las puntuaciones diferenciales (X-X). Lo que su-
cede es que estas fórmulas que simplifican operaciones son menos útiles, ya
que disponemos de programas informáticos y calculadoras con programación
estadística.
Una de estas fórmulas para calcular la desviación típica a partir de las pun-
tuaciones directas y de la media, es la que nos interesa para poder demostrar
la fórmula que nos permite combinar desviaciones típicas de varios grupos;
es la fórmula [17] que viene en muchos textos; a partir de esta fórmula [17]
llegamos con facilidad a la fórmula [14] para combinar desviaciones típicas o
varianzas.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
56
Vamos a ver cómo de la fórmula [17] llegamos a la fórmula [14], que es la
propuesta para combinar desviaciones típicas; después veremos de dónde sa-
le esta fórmula [17].
Para simplificar esta demostración utilizamos la varianza en vez de la des-
viación típica, así si elevamos al cuadrado la desviación típica expresada en
[17] tendremos que la varianza será
Si en [18] despejamos SX2
tendremos SX2
=N(s2
+ X2
) [19]
La expresión que tenemos en [19] podemos verla ya en la fórmula [14]. Si
de dos muestras conocemos los valores de N, X y s, podemos utilizar la fór-
6
Esta fórmula la tomamos de McNemar (1962, pág. 24).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-56-320.jpg)
![mula [17] para calcular la desviación típica de las dos muestras combinadas
en una única muestra. En esta fórmula [17] utilizada para combinar dos (o
más) desviaciones típicas tenemos ahora que:
N = N1 + N2;
La media será la media total de las dos (o más) muestras
SX
2
será la expresión [19] calculada en las dos (o más) muestras y su-
madas.
Es decir, substituyendo [19] en [18] tenemos la fórmula [14] para combi-
nar desviaciones típicas.
Podemos preguntarnos ahora de dónde viene la fórmula [17], que es la
que estamos utilizando para llegar a la fórmula [14] y calcular la desviación tí-
pica de dos (o más) muestras combinadas en una sola.
En la fórmula de la desviación típica tenemos en el numerador un binomio
elevado al cuadrado. No hay más que aplicar la fórmula usual: (a - b)2
= a2
-
2ab + b2
, y así llegamos a [18] y [17]:
Utilizando la varianza para simplificar, tenemos que:
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
57
Como en [17] tenemos que y que
Tendremos que y así llegamos a [18]
y [17]
2.3. El coeficiente de variación (V)
Otra medida de dispersión, menos utilizada, es el coeficiente de varia-
ción. En principio se utiliza para comparar dispersión cuando los instrumen-
tos o unidades de medida son distintas, o cuando las medias de dos grupos
son muy desiguales.
La desviación típica viene expresada en las mismas unidades empleadas en
la medición, por lo tanto dos desviaciones calculadas con instrumentos y uni-
dades distintas no son comparables entre sí directamente. Lo mismo sucede
cuando las medias son muy distintas (por ejemplo cuando las medias de dos
exámenes son muy distintas porque el número de preguntas es distinto).
En estos casos se utiliza el coeficiente de variación o de variabilidad rela-
tiva: consiste sencillamente en dividir la desviación típica por la media (es de-
cir, se trata de la desviación relativa a la media); es habitual multiplicar por
100 este cociente.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-57-320.jpg)
![Coeficiente de variación: [21]
Por ejemplo, en dos grupos, de chicos y chicas, tenemos estos datos (pe-
so en Kg.)
media desviación
chicos 66.87 6.99
chicas 51.06 5.10
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
58
Aparentemente los chicos difieren
más entre sí que las chicas entre sí (su
desviación típica es mayor; los chicos
tienen de manera natural más ámbito
de variación), pero también es ver-
dad que las medias son muy distintas.
Si calculamos el coeficiente de variación (haciendo las desviaciones relati-
vas a la media) tenemos estos resultados:
6.69
V (chicos) =––––– (100) = 10.45
66.87
5.51
V (chicas) =––––– (100) = 10.79
51.06
Teniendo en cuenta la diferencia en-
tre las medias, entre las chicas encon-
tramos más variabilidad en peso (aun-
que no mucha más).
El uso de este coeficiente de variación en medidas educacionales o psico-
lógicas es muy cuestionable, porque su valor depende de la media, que a su
vez depende de la facilidad o dificultad de las preguntas, test, etc. Su inter-
pretación se presta a ambigüedades. Si por ejemplo a un test de 10 preguntas
le añadimos otras 10 muy fáciles, subirá la media y bajará el valor de V
.
Este coeficiente puede utilizarse y es especialmente útil cuando se dan es-
tas circunstancias:
1º Cuando las unidades lo son en sentido propio (como peso, altura,
con una unidad clara); menos aconsejable es utilizarlo en las medi-
das educacionales y psicológicas habituales;
2º Cuando las medias son muy desiguales (como en el ejemplo ante-
rior, peso en chicos y chicas).
3º Cuando las medidas son distintas (por ejemplo; ¿dónde hay más va-
riabilidad, en peso o en altura?).
En el campo de los tests en general, puede ser útil para comparar la varia-
bilidad de un grupo en el mismo test aplicado en circunstancias distintas.
2.4. La desviación semi-intercuartílica
Nos hemos centrado fundamentalmente en la desviación típica y en la
varianza porque se trata de dos conceptos fundamentales para el resto de](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-58-320.jpg)
![los análisis estadísticos. Son medidas de dispersión que se utilizan cuando se
utiliza la media aritmética como medida de tendencia central.
Se utilizan también otros pares de medidas, tanto de tendencia central
(que ya hemos visto, como la mediana y la moda) como de dispersión, que
son ya de utilidad más limitada, aunque tienen su lugar como descriptores de
un conjunto de puntuaciones.
La desviación semi-intercuartílica es la medida de dispersión apropiada
cuando la medida de tendencia central es la mediana, y expresa la disper-
sión del 50% central del grupo, por lo que, lo mismo que la mediana, se pres-
cinde también de las puntuaciones extremas.
El concepto es claro y podemos verlo en la distribución de frecuencias de
la tabla 10.
Hemos dividido la muestra en cuatro partes con idéntico número de suje-
tos (el 25% en cada una); los límites de estas cuartas partes se denominan
cuartiles:
Límite superior del cuartil 3 (queda por debajo el 75 % del total) (Q3) = 12.5
Límite superior del cuartil 1 (queda por debajo el 25 % del total) (Q1) = 6.5
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
59
Tabla 10
Es decir, y dicho de manera más sencilla, entre 6.5 y 12.5 está el 50% cen-
tral de los sujetos; la desviación semi-intercuartílica (Q) será:
[22] en este ejemplo tendríamos
Este ejemplo está puesto para explicar el concepto; lo normal es que los lí-
mites del 50% central no estén tan claros a simple vista; el cálculo exacto lo
veremos al tratar de los percentiles, pues se trata simplemente de calcular por
interpolación los percentiles 25 y 75, como se explica en su lugar.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-59-320.jpg)
![2.5. La amplitud o recorrido
La amplitud o recorrido (ambos términos son usuales)7
es la medida de
dispersión que se utiliza cuando la moda es la medida de tendencia central.
Su cálculo es muy simple:
Amplitud = (puntuación más alta menos la puntuación más baja) + 1 [23]
En el ejemplo de la tabla 10: amplitud = (15-4) + 1 =12
Observaciones sobre la amplitud:
1. Sumamos una unidad a la diferencia entre las puntuaciones extremas
(se trata de una convención aceptada) porque nos situamos en los lí-
mites extremos de ambas puntuaciones: el límite superior de 15 sería
15.5 y el límite inferior de 4 sería 3.5; la amplitud será pues 15.5 - 3.5 =
12 (ó 15 - 4 + 1).
2. Como indicador de dispersión es una medida débil, pues se basa en só-
lo dos puntuaciones, que además pueden ser atípicas, poco represen-
tativas, y grupos semejantes pueden parecer muy distintos en disper-
sión, simplemente porque en algún grupo hay uno o dos sujetos con
puntuaciones inusualmente altas o bajas.
2.6. Relación entre la amplitud y la desviación típica
En muestras relativamente grandes (de 500 o 600 sujetos) la amplitud o
recorrido suele comprender unas seis desviaciones típicas (entre -3 y +3),
por lo que un cálculo aproximado de la desviación típica consiste en dividir
la amplitud entre seis. Según va bajando N (número de sujetos, tamaño de la
muestra) la amplitud comprende menos desviaciones típicas y si sube N
la amplitud suele comprender más de seis desviaciones.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
60
7
A veces, y de manera errónea, se denomina rango a la amplitud, por confusión con
el inglés (amplitud o recorrido en inglés es range). El término rango significa propiamen-
te número de orden (rank en inglés).
Tabla 11](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-60-320.jpg)


![de tendencia central de dispersión
MEDIDAS DESCRIPTIVAS BÁSICAS DE TENDENCIA CENTRALY DE DISPERSIÓN
63
Moda: puntuación con una
frecuencia mayor
La moda es simplemente la puntua-
ción con la mayor frecuencia, la ob-
tenida por el mayor número de suje-
tos. Puede haber varias puntuaciones
con esta característica (distribuciones
bimodales, plurimodales). Como me-
dida de tendencia central es poco ri-
gurosa, sobre todo en distribuciones
asimétricas. Se basa en las puntuacio-
nes de dos sujetos que si son muy ex-
tremas y atípicas desvirtúan la infor-
mación.
La moda y la amplitud son las medi-
das menos rigurosas aunque pueden
tener su interés descriptivo.
Amplitud = [valor más alto - valor
más bajo] +1
La amplitud (o recorrido, y mal lla-
mada a veces rango) es igual a la dife-
rencia entre la puntuación más alta y
la puntuación más baja. Habitualmen-
te se suma una unidad a esta diferen-
cia porque se calcula a partir de los lí-
mites de los valores extremos (si las
puntuaciones extremas son, por
ejemplo, 20 y 5, la amplitud no es
igual a 20 - 5 sino igual a 20.5 - 4.5 =
[(20 - 5) + 1]. Es una medida muy in-
estable porque depende solamente
de los dos valores extremos. En
muestras semejantes la amplitud pue-
de ser muy diferente; basta que haya
sujetos muy atípicos en los extremos.
En la distribución normal (simétrica, acampanada) media, mediana y moda
coinciden en un idéntico valor.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-63-320.jpg)







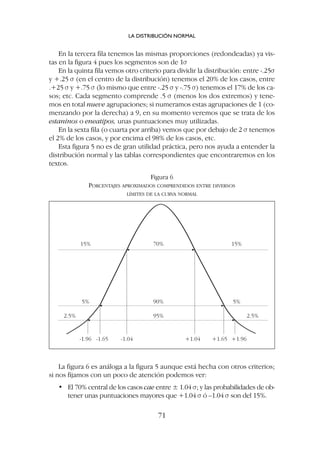
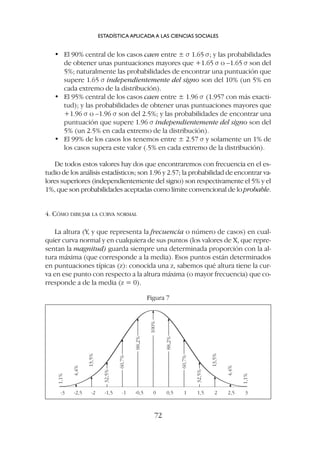
![En la figura 7 se dan las alturas de algunos puntos concretos; son unos
puntos de referencia suficientes para dibujar la curva. Si por ejemplo la altu-
ra máxima es de 8 cm (la altura absoluta se escoge arbitrariamente), la altura
correspondiente a +1 y -1 desviaciones típicas (los puntos de inflexión) será
el 60.7% de 8cm, que es igual a 4.85 cm ([8/100]x 60.7).
5. CÓMO UTILIZAR LAS TABLAS DE LA DISTRIBUCIÓN NORMAL
Las tablas de la distribución se pueden presentar de maneras distintas y
hay que examinarlas en cada caso, pero la información es siempre la misma.
Lo que habitualmente interesa conocer es la probabilidad de obtener una
puntuación mayor o menor que una determinada puntuación típica.
Recordamos que una puntuación típica indica la distancia o diferencia de
una puntuación (u observación) con respecto a la media expresada en desvia-
ciones típicas. La media corresponde siempre a z = 0; las puntuaciones típi-
cas superiores a la media tienen el signo más y las puntuaciones típicas infe-
riores a la media tienen el signo menos.
Cómo se utilizan las tablas de la distribución normal lo veremos con unos
ejemplos3
.
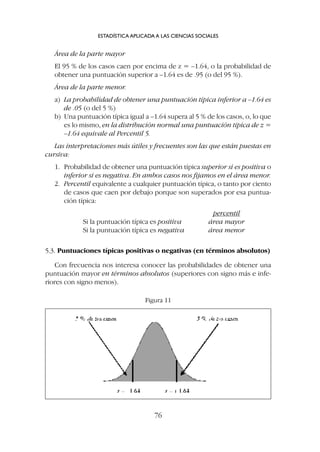
5.1. Puntuaciones típicas positivas (superiores a la media)
Por ejemplo z = +1.64
1. Lo primero que tenemos que hacer es imaginar o dibujar una curva
normal (figura 8) en la que la media (z = 0) divide la distribución en
dos áreas de idéntico tamaño; por encima de la media cae el 50% de los
casos y por debajo tenemos el otro 50% de los casos.
LA DISTRIBUCIÓN NORMAL
73
3
Las tablas de la distribución normal se encuentran al final de esta publicación.
Figura 8](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-73-320.jpg)
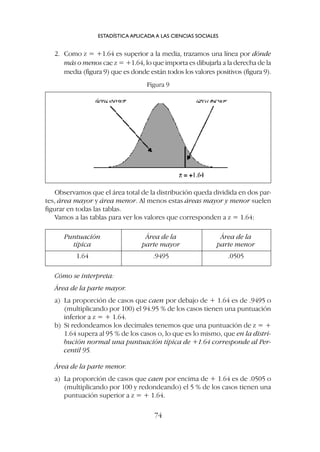
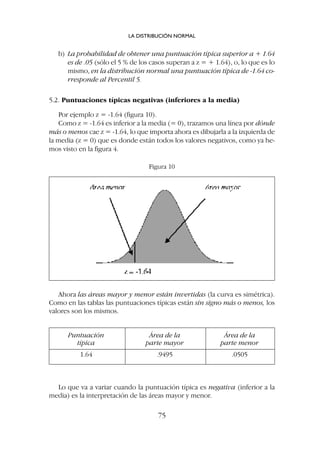
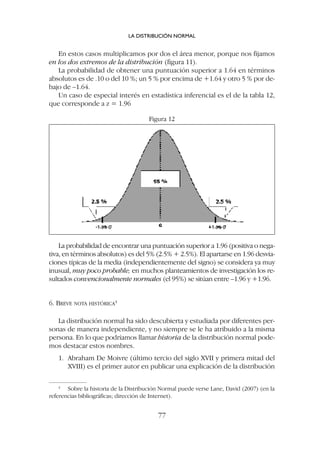






![El símbolo de las puntuaciones típicas es z (zeta minúscula); también
suelen denominarse simplemente puntuaciones zeta y a veces puntuaciones
estandarizadas (standard score en inglés). Su fórmula es:
Puntuación obtenida-media
Puntuación típica (z) = ––––––––––––––––––––––
desviación típica
Y en símbolos convencionales [1]
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
84
El valor de z indica por lo tanto cuántas desviaciones típicas contiene la di-
ferencia X - X (a cuántas desviaciones típicas equivale esa diferencia); la des-
viación típica es ahora nuestra unidad de medición; el dato individual lo ex-
presamos en términos de desviaciones típicas por encima o por debajo de la
media.
Por ejemplo imaginemos los resultados de tres sujetos (suponemos que la
muestra es mayor) en un examen; la media es X = 10 y la desviación típica es
s = 2 (tabla 1)
Tabla 1
La puntuación directa de estos tres sujetos ha quedado transformada en
un nuevo valor.
En este ejemplo ya podemos ir viendo que:
a) Si un sujeto tiene un resultado igual a la media, su puntuación típica
será igual a cero; al restar a todos la media, el que tenga como resulta-
do personal la media se queda en cero.
b) Todos los que tengan una puntuación directa superior a la media, ten-
drán una puntuación típica con signo positivo;
c) Todos los que tengan una puntuación directa inferior a le media, ten-
drán una puntuación típica con signo negativo.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-84-320.jpg)

![El que la desviación típica de las puntuaciones típicas sea igual a 1 tiene
consecuencias importantes. En una combinación de puntuaciones parciales,
la que pesa más en la media final es aquella con una mayor desviación típica.
Si calculamos una media a partir de las puntuaciones típicas, todas las puntua-
ciones parciales pesarán lo mismo, porque todas tendrán idéntica desviación
típica.
4º Si sumamos a todas las puntuaciones directas una constante, la des-
viación típica permanece idéntica, porque se mantienen idénticas las
distancias con respecto la media.
Lo podemos ver en las tres series de puntuaciones puestas en la tabla [2].
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
86
En B hemos sumado 12 puntos a cada sujeto con respecto a A, y en C he-
mos sumado 80 a las puntuaciones de B. Naturalmente las medias son distin-
tas, pero las desviaciones típicas son idénticas porque las distancias inter-indi-
viduales son las mismas: el grado de homogeneidad (diferencias de los
sujetos con respecto a su media) de los tres grupos es el mismo.
5º Si multiplicamos todas las puntuaciones directas por una constante,
la desviación típica queda multiplicada por esa constante, porque
en esa cantidad ha aumentado la diferencia con respecto a la media.
Lo vemos en este ejemplo:
grupo A: 8 10 12 media: 10 s = 1.63
grupo B (= Ax2): 16 20 24 media: 20 s = 3.26
Al multiplicar por dos las puntuaciones del grupo A, la desviación típica (lo
mismo que la media) también queda multiplicada por dos (1.63 x 2 = 3.26).
Estas dos propiedades son importantes porque nos permiten transformar
las puntuaciones típicas en otras más cómodas; son las puntuaciones tipifi-
cadas que veremos más adelante.
Tabla 2](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-86-320.jpg)



![teniendo siempre en cuenta que se trata de puntuaciones relativas al gru-
po, por lo que es discutible utilizarlas para establecer el nivel mínimo para
el apto (que es preferirle determinar con otros criterios; el que sabe menos
puede saber lo suficiente). Es menos cuestionable su uso para asignar las
calificaciones más altas (una puntuación típica en torno a +2, e incluso me-
nor, indica ya un resultado excelente para lo que de hecho da de sí un de-
terminado grupo).
6. Para interpretar debidamente las puntuaciones típicas hay que tener en
cuenta de qué tipo de datos se trata: no es lo mismo número de respuestas
correctas en una prueba objetiva que las calificaciones puestas por el profe-
sor al corregir un examen abierto, notas, etc.
En principio estos cálculos son de interpretación más clara cuando están
hechos a partir de puntuaciones o resultados directos más que cuando los
números expresan calificaciones o juicios de valor.
4.4. Puntuaciones tipificadas (puntuaciones típicas transformadas)
Las puntuaciones tipificadas son puntuaciones derivadas de las puntuacio-
nes típicas. El símbolo general de las puntuaciones tipificadas es Z (zeta ma-
yúscula); algunas puntuaciones tipificadas tienen sus símbolos particulares.
Las puntuaciones típicas son incómodas para expresar resultados porque:
a) Prácticamente siempre tienen decimales,
b) Más o menos la mitad de las puntuaciones típicas tienen signo menos
(todas las inferiores a la media).
Por estas razones, y sobre todo para poder expresar resultados de tests de
manera más fácilmente comprensible, suelen transformarse en otras puntua-
ciones más cómodas.
Se trata de una transformación linear, cuya fórmula genérica es
Z = (z • a) + b [2] donde a y b son dos constantes.
Es decir, todas las puntuaciones típicas:
1º Se multiplican por una cantidad constante (a) y así se eliminan los de-
cimales (estas puntuaciones se redondean y se expresan sin decima-
les);
2º Se les suma una cantidad constante (b) y así se elimina el signo menos.
Entre las puntuaciones tipificadas son muy utilizadas las puntuaciones T:
T = 10z + 50 [3]
También es frecuente hacer estas transformaciones: Z = 20z + 100
Z = 15z + 100
Z = 100z + 500
TIPOS DE PUNTUACIONES INDIVIDUALES
91](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-91-320.jpg)
![Al tipificar una serie de puntuaciones, automáticamente tenemos una nue-
va media y una nueva desviación típica, que son siempre las mismas cual-
quiera que sea la escala métrica de las puntuaciones directas originales:
1. La nueva media es igual a la constante que se suma a todas las pun-
tuaciones.
Un sujeto cuya puntuación directa coincidiera con la media de la distri-
bución, tendría z = 0, y su puntuación T (fórmula [3]) sería 10(0) + 50
= 50; si la constante que se suma es 100, la media sería 100, etc.
2. La nueva desviación típica es igual a la constante por la que se han
multiplicado las puntuaciones típicas.
Un sujeto cuya puntuación directa supere en una desviación típica a la
media, tendría una puntuación típica de z = 1, y su puntuación T sería
T = 10(1) + 50 = 60 (la media, 50, + 1s = 50 +10).
Podemos establecer que los valores de la media y de la desviación sean los
que queramos. Si deseamos transformar las puntuaciones de manera que la
media sea 20 y la desviación típica valga 5, tendremos que Z = 5z + 20, etc.
Lo mismo que en las puntuaciones típicas, a cada puntuación tipificada le
corresponde en la distribución normal el mismo percentil.
Las puntuaciones tipificadas resultan mucho más fáciles de interpretar que
las puntuaciones directas, sobre todo cuando se trata de tests. Si los resulta-
dos de un test de inteligencia se han transformado de esta manera (como es
frecuente) Z = 20z + 100:
Un sujeto con una puntuación de 100 está en la media (porque a la media
le corresponde una z igual a 0: (20)(0)+100 = 100.
Un sujeto que tenga 160 supera a la media en tres desviaciones típicas
(100 +20 +20 +20); que es ya excepcional.
Un sujeto que tenga 60 (100 - 20 -20) está a dos desviaciones típicas por
debajo de la media, y ya se va apartando mucho de la normalidad.
5. PERCENTILES
5.1. Concepto e interpretación
1º Los percentiles indican el tanto por ciento de sujetos que están por deba-
jo de cada puntuación.
Los percentiles son por lo tanto fáciles de interpretar, de entender y de co-
municar. Si un sujeto con una puntuación de 19 (en un test, en una prueba
objetiva, etc.) supera al 45% de su grupo:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
92](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-92-320.jpg)

![test. En cualquier caso este tipo de normas de interpretación (percentiles y
otras) hay que renovarlos cada cierto tiempo (como ya hemos indicado, la
edad media de un test, o más bien de sus baremos o normas de interpreta-
ción, puede no ser superior a 10 años; con el tiempo pueden variar actitudes
sociales, niveles educativos, capacidad lectora, etc.).
Con frecuencia es preferible calcular unos nuevos percentiles para mues-
tras quizás muy distintas de las que sirvieron para hacer los baremos origina-
les (y esta observación es válida también para otros tipos de normas de los
tests, no sólo para los percentiles).
3º Algunos percentiles tienen nombres y símbolos específicos:
1. Deciles: son los percentiles 10, 20, etc., y se simbolizan D1, (= P10), D2,
(= P20), etc.
2. Cuartiles: son los percentiles que dividen al grupo en cuatro partes
con idéntico número de sujetos (el 25%):
Q3 (tercer cuartil) = P75: por encima está el 25 % de la muestra;
Q2 (segundo cuartil) = P50; se trata de la mediana, que se utiliza
como medida de tendencia central; divide al
grupo en dos partes iguales
Q1 (primer cuartil) = P25: por debajo está el 25% de la muestra
Estos tres valores se calculan a veces como puntos de referencia y para ha-
cer determinadas representaciones gráficas (como los diagramas de cajas).
4º Con los valores de Q1 y Q3 se calcula la desviación semi-intercuartílica:
Desviación semi-intercuartílica: [4]
a) La desviación semi-intercuartílica Q es la medida de dispersión que
se utiliza cuando la medida de tendencia central es la mediana. Mi-
de la dispersión en el 50% central de la muestra. Lo podemos ver con
los datos concretos de un test en la figura 1.
b) Tanto los deciles como los cuartiles se calculan por el método de inter-
polación que veremos más adelante.
c) Los valores de Q1 y Q3 se calculan con decimales cuando se van a utili-
zar en el cálculo de Q.
d) La mediana y Q, como medidas de tendencia central y dispersión, se
utilizan preferentemente con distribuciones muy asimétricas y en cual-
quier caso son medidas descriptivas complementarias, aunque menos
utilizadas que la media y la desviación típica;
e) La mediana y Q, como medidas de tendencia central y dispersión, son
especialmente útiles siempre que se prefiera que sujetos con puntua-
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
94](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-94-320.jpg)



![tervalos; unos 10 ó 12 es lo normal; más de 15 puede ser ya excesi-
vo (cómo hacer esta agrupación está explicado al comienzo, al tra-
tar de la distribución de frecuencias).
i = Valor o amplitud del intervalo; aquí i = 3 porque las puntuaciones
están agrupadas de tres en tres. Si las puntuaciones estuvieran sin
agrupar (una sola puntuación en cada intervalo) tendríamos i =1.
No hay que confundir el número de intervalos (10 en este caso),
con el valor del intervalo (que interviene en algunas fórmulas, co-
mo en el cálculo de percentiles por interpolación).
f = Frecuencia, o número de casos en cada intervalo.
fa = Frecuencias acumuladas: se van sumando las frecuencias de abajo
arriba. La frecuencia acumulada en el intervalo superior debe ser
igual al número de sujetos (es útil caer en la cuenta para detectar
posibles errores; en este caso N = 40 = fa en el intervalo más alto).
fam= Frecuencias acumuladas al punto medio; a cada frecuencia acu-
mulada se le resta la mitad de su f correspondiente.
También se calculan a veces los percentiles a partir de las frecuencias
acumuladas (P = [fa/N] 100), pero lo convencional es hacerlo a par-
tir de las frecuencias acumuladas al punto medio. La razón de hacer-
lo así es porque suponemos que cada uno de los que están en cada
intervalo (si pudiéramos matizar mucho la medición) superan a la
mitad de los que tienen idéntica puntuación y tienen por encima a la
otra mitad. Se supone que los que aparecen igualados en realidad
son distintos y así aparecerían si los midiéramos matizando más.
P = Percentil, o tanto de por ciento de sujetos que caen debajo de ca-
da puntuación. Los percentiles se redondean y se presentan sin
decimales.
En la tabla 6 vemos que un sujeto con una puntuación directa (número de
respuestas correctas, suma de todas sus respuestas, etc.) que esté entre 26 y
28, tiene un rango percentil de 72, o tiene por debajo (supera) al 72% del
grupo en el que se han calculado los percentiles.
5.2.2. Cálculo por interpolación
Con frecuencia interesa conocer el valor de determinados percentiles; por
ejemplo:
La mediana o P50, y los percentiles 75 y 25 (P75 o Q3 y P25 o Q1) como
datos descriptivos o para calcular la medida de dispersión Q,
Los deciles (P10, P20, P30, etc. también simbolizados como D1, D2, D3,
etc.) para simplificar la interpretación de un test, dando sólo estos
percentiles como referencia.
TIPOS DE PUNTUACIONES INDIVIDUALES
99](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-99-320.jpg)

![Tenemos 42 y necesitamos 43.5, por lo tanto nos faltan 1.5 sujetos (=
número de sujetos que necesito [paso 1º] menos número de sujetos
que tengo [paso 2º]).
5º Del intervalo siguiente tomamos la parte proporcional de sujetos que
necesitamos; para esto dividimos el número de sujetos que nos faltan
por la frecuencia (o número de sujetos) del intervalo inmediatamen-
te superior: 1.5/8 = .1875
6º Esta cantidad la multiplicamos por el valor del intervalo. El valor del
intervalo es igual al número de puntuaciones que hay en cada interva-
lo; en este caso este valor es igual a 1 porque las puntuaciones van de
una en una. Si estuvieran agrupadas de dos en dos (9-10, 11-12, etc.) el
valor del intervalo sería igual a dos.
7º La cantidad calculada en el paso anterior la sumamos al límite su-
perior del intervalo inferior al que contiene el percentil buscado (pa-
so 3º), con lo que el valor del Percentil 75 será igual a 16.5 +.1875 =
16.69.
Expresando todas las operaciones hechas tendríamos que:
Si vamos a utilizar este valor para interpretar las puntuaciones de un test o
como dato descriptivo, redondeamos los decimales y obtendremos P75 = 17.
Si vamos a utilizar este valor para otros cálculos (por ejemplo para calcular le
valor de Q), dejamos los decimales.
La fórmula de los percentiles calculados por interpolación podemos ex-
presarla tal como se indica en la figura 3
TIPOS DE PUNTUACIONES INDIVIDUALES
101
Figura 3
5.2.3. Cálculo de los percentiles mediante la representación
gráfica de las frecuencias relativas acumuladas
Una representación gráfica frecuente de las puntuaciones directas es la de
las frecuencias relativas acumuladas. La utilidad de esta representación grá-
fica está en que permite un localizar de manera muy aproximada, sin hacer](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-101-320.jpg)


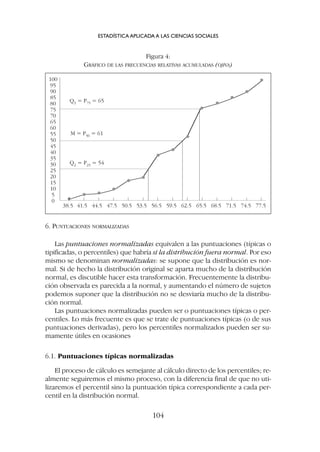






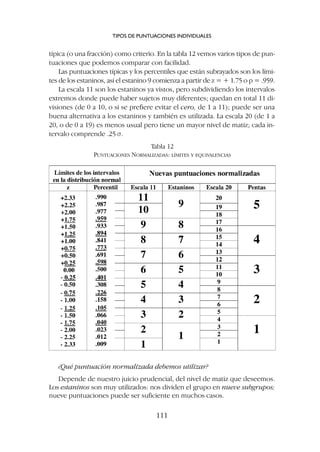
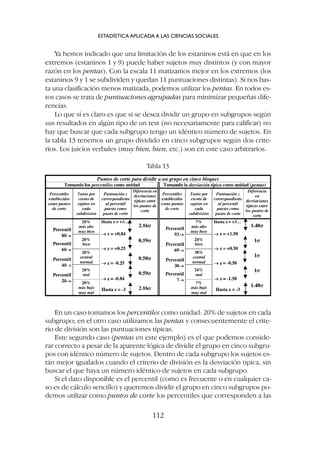

![c) Si la distribución de las puntuaciones reales, observadas, se aparta no-
tablemente de la distribución normal, estos percentiles pueden quedar
muy distorsionados. Con muestras razonablemente grandes el cálculo
de estos percentiles normalizados tiene más sentido.
d) Una utilidad clara de estos percentiles normalizados, y que es la que
realmente justifica este apartado, la tenemos cuando de un grupo só-
lo conocemos la media y la desviación típica en algún test o escala, y
deseamos preparar unas normas o baremos para interpretar las pun-
tuaciones individuales.
En estos casos nos puede bastar buscar las puntuaciones directas que
corresponden a una serie de percentiles previamente escogidos como
referencia suficiente. En la tabla 14 tenemos una serie de percentiles y
las puntuaciones típicas que les corresponden en la distribución nor-
mal; nuestra tarea será localizar las puntuaciones directas (X) que co-
rresponden a esas puntuaciones típicas.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
114
Tabla 14
Ahora tenemos que calcular la puntuación directa (X) que corresponda a
las puntuaciones típicas seleccionadas:
X - X
Si z =––––––– tendremos que X = (s)(z)+X [6]
s
Como en [6] conocemos todos los valores (s, y z lo buscamos en la tabla
14), podemos calcular el valor de X, o puntuación directa que corresponde a
determinados percentiles.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-114-320.jpg)











![3º. La suma de los productos cruzados de las puntuaciones diferenciales
(directas Sdxdy ó típicas Szxzy), ya nos está indicando el grado de relación; la
suma será mayor (con signo más o signo menos) cuando haya una mayor re-
lación porque habrá más sumandos de idéntico signo. La mera suma de estos
productos no nos es muy útil porque no podemos compararla con otras su-
mas, pero si la dividimos por el número de sujetos lo que tenemos es una me-
dia comparable con cualquier otra media obtenida con un número distinto de
sujetos (esta explicación figura en la figura 3).
Si dividimos esta suma por el número de sujetos (= media de los produc-
tos cruzados) tenemos la fórmula de la covarianza (utilizando puntuaciones
directas) o de la correlación (utilizando puntuaciones típicas).
Covarianza: [1] Correlación: [2]
Por lo tanto correlación (símbolo rxy o simplemente r) y covarianza (sím-
bolo sxy) expresan lo mismo: cuantifican el grado de covariación y a ese gra-
do de covariación le denominamos relación. Realmente el coeficiente de
correlación no es otra cosa que la covarianza calculada con puntuacio-
nes típicas.
Correlación y covarianza se relacionan mediante estas fórmulas:
sxy
rxy (correlación) = ––––– [3] sxy (covarianza) = rxy sxsy [4]
sx sy
Como medida de relación se pueden utilizar tanto la covarianza como el
coeficiente de correlación (r de Pearson). El utilizar preferentemente el coe-
ficiente de correlación se debe a estas razones:
1) El utilizar puntuaciones típicas permite comparar todo con todo; dos
coeficientes de correlación son comparables entre sí cualquiera que
sea la magnitud original de las puntuaciones directas. La magnitud
de la covarianza va a depender de la unidad utilizada y no se pueden
comparar dos covarianzas, para comprobar dónde hay mayor relación,
cuando las unidades son distintas.
2) El coeficiente de correlación r varía entre 0 (ausencia de relación) y un
valor máximo de 1 (con signo + ó -). El que los valores extremos sean
0 y 1 facilita el uso y la valoración de la magnitud de estos coeficientes.
La demostración de que el valor máximo de r es igual a 1 (±1) es sencilla:
1º La suma de las puntuaciones típicas elevadas al cuadrado es igual al
número de sujetos (N):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
126](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-126-320.jpg)
![2º Si se diera una relación perfecta, tendríamos que para cada sujeto
zx = zy con lo que zxzy sería igual a z2
, y como Sz2
= N, tendríamos
que:
2.2. Otras fórmulas y procedimientos
Hay muchas fórmulas, pero todas equivalen a la fórmula básica (fórmula
[2]: rxy = (Szxzy)/N). Esta fórmula básica es muy laboriosa de cálculo. Hay
otras fórmulas más sencillas en las que sólo se utilizan puntuaciones directas,
pero tampoco resultan prácticas, ya que la correlación puede encontrarse ya
programada en muchas calculadoras sencillas (y en hojas de cálculo y en pro-
gramas de ordenador o de Internet).
Si se dispone de una calculadora con la desviación típica programada, una
fórmula sencilla es ésta:
[5]
Para el cálculo disponemos los datos tal como están en la tabla 4
CONCEPTO DE CORRELACIÓNYCOVARIANZA
127
Tabla 4
Se calculan las desviaciones de las dos variables y de la suma de ambas y se
aplica la fórmula anterior [5]:
Esta fórmula puede ser la más cómoda cuando tenemos pocos sujetos y
una calculadora con programación estadística; con muestras grandes, o cuan-
do hay calcular varios coeficientes con los mismos datos, hay que acudir a ho-
jas de cálculo o a programas de ordenador, que es lo que haremos habitual-
mente.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-127-320.jpg)





![[6]
Tenemos, por ejemplo, estos dos coeficientes de correlación calculados en
las mismas dos variables en dos muestras distintas:
En una muestra de N = 60 r = .45
En una muestra de N = 120 r = .30
Correlación media:
Esta media ponderada es de cálculo sencillo, de fácil comprensión y no
distorsiona más la verdadera media que lo que la distorsiona la transforma-
ción de Fisher4
. Si el número de sujetos es el mismo se calcula directamente
la media aritmética.
También es frecuente utilizar la mediana en vez de la media (el uso de la
mediana es siempre apropiado) cuando se dispone de una serie de coeficien-
tes de correlación y se quiere indicar una medida de tendencia central.
Como siempre que se utiliza la mediana en vez de la media hay que re-
cordar dónde está la diferencia entre ambos estadísticos. Como la mediana es
simplemente el valor central que divide a la muestra (de coeficientes en este
caso) en dos mitades iguales, no se ve afectada por valores extremos que sí se
influyen y se notan en la media. Unos pocos coeficientes atípicos (o muy al-
tos o muy bajos), o un solo coeficiente muy atípico, pueden sesgar la media
como valor representativo en una dirección. En estos casos puede ser prefe-
rible utilizar la mediana, o ambos valores, la media y la mediana.
3.4. El coeficiente de determinación
El coeficiente de correlación elevado al cuadrado (r2
) se denomina coefi-
ciente de determinación e indica la proporción (o porcentaje si multipli-
camos por 100) de variabilidad común: indica la proporción de varianza de
una variable determinada por o asociada a la otra variable.
En términos más simples, r2
indica el tanto por ciento (r2
x 100) de acuer-
do, de área común o de variabilidad común entre ambas variables. Un co-
eficiente de r = .50 indica un 25% de varianza común entre ambas variables
(.502
=.25). Una correlación de r = .50 entre un test de inteligencia abstracta
CONCEPTO DE CORRELACIÓNYCOVARIANZA
133
4
La transformación de Fisher tiene un sesgo positivo: la media resultante es ligeramen-
te mayor de lo que debería ser. Con la media ponderada por el número de sujetos (fórmula
[6]) la media que resulta es ligeramente menor, pero la desviación es menor en términos ab-
solutos que la que provoca la transformación de Fisher, y con muestras grandes (a partir de N
= 40) el margen de error es muy bajo y sólo afecta al tercer decimal (Hunter y Schmidt, 1990).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-133-320.jpg)


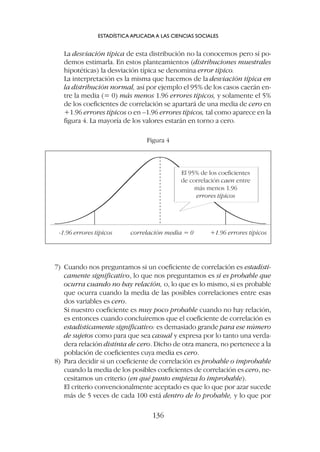


![Vemos .576 en la columna correspondiente a .05; esto quiere decir que
con 12 sujetos (10 grados de libertad) una correlación tan alta como .576 la
obtendríamos por azar, sin que hubiera relación entre las dos variables, 5 ve-
ces de cada 100 (y nuestra conclusión será que sí hay relación; no ha sido
una casualidad).
Debajo de .01 vemos r = .7079, que es el valor de la correlación que podría-
mos obtener por azar 1 vez cada 100, y debajo de .001 vemos r = .8233, la co-
rrelación que podríamos obtener por azar 1 vez cada 1000 veces.
azar (en la hipótesis de no relación); la consecuencia es que podemos suponer
que en la población (en otras muestras semejantes) seguiremos encontrando
una correlación distinta de cero. Esto lo veremos también después desde otra
perspectiva al tratar de los intervalos de confianza de la correlación.
La teoría subyacente a esta comprobación es la misma que la de plantea-
mientos semejantes en estadística (¿cuándo podemos considerar que una di-
ferencia entre dos medias es mayor de lo puramente casual y aleatorio?). Lo
que hacemos es dividir nuestro coeficiente de correlación (o con más propie-
dad |r – 0|, la diferencia entre la correlación obtenida y una correlación me-
dia de cero) por el error típico de la correlación (fórmulas [10] y [11]) pa-
ra ver en cuántos errores típicos se aparta nuestro coeficiente de una
correlación media de cero7
.
a) Con muestras de 100 sujetos o menos
Lo más práctico es consultar las tablas apropiadas (anexo I, al final del ca-
pítulo)8
, en las que se indica la probabilidad de obtener un determinado coe-
ficiente por azar, sin que haya relación entre las dos variables.
Para consultar las tablas tenemos que tener en cuenta los grados de liber-
tad, que en el caso de la correlación son N-2.
Por ejemplo, con N = 12 los grados de libertad son 10. En las tablas y con
10 grados de libertad vemos:
CONCEPTO DE CORRELACIÓNYCOVARIANZA
139
7
Aunque consultemos tablas o vayamos a direcciones de Internet que nos lo dan re-
suelto, conviene entender qué estamos haciendo.
8
Tablas semejantes figuran en muchos textos; también podemos consultar las direc-
ciones de Internet puestas en el Anexo II.
Grados de libertad = N -2 .05 .01 .001
10 .5760 .7079 .8233](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-139-320.jpg)
![Siempre que el valor de nuestra correlación sea igual o mayor que el valor
indicado en la columna .05, podemos concluir que la correlación es estadís-
ticamente significativa (improbable por azar; ese coeficiente de correlación
lo podríamos encontrar, sin que se dé relación, 5 veces o menos de cada 100).
Si supera los valores de las columnas .01 ó .001 se indica de esta manera: p
.01 ó p .001.
Ya hemos indicado en el apartado anterior que este 5% es el límite conven-
cional y aceptado para rechazar el azar (el error muestral en términos más
apropiados) como explicación, por lo que podríamos concluir que sí hay re-
lación aunque ésta puede ser pequeña y de poco valor práctico. Una corre-
lación estadísticamente significativa no significa una correlación grande.
El poner un 5% de probabilidades de error (para afirmar que sí hay rela-
ción) es un criterio usual aunque arbitrario; si uno desea más seguridad pue-
de poner como límite un 1% de probabilidad de error; son los dos límites
convencionales más utilizados.
b) Con muestras de más de 100 sujetos
Vemos en cuántas desviaciones típicas (errores típicos) se aparta nuestro co-
eficiente de correlación de una correlación media de cero; es decir calculamos
la puntuación típica (z) correspondiente a nuestro coeficiente de correlación:
[7]
Lo que tenemos en el denominador es la fórmula del error típico de los
coeficientes de correlación (en muestras grandes).
Esta fórmula queda simplificada así: [8]
En la tabla 6 están los valores críticos para interpretar los resultados.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
140
Tabla 6
En el numerador de la fórmula [7] tenemos la diferencia entre nuestra co-
rrelación y una correlación media de cero; lo que tenemos en el denomina-](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-140-320.jpg)
![dor es el error típico (o desviación típica) de la distribución de las correlacio-
nes cuando la correlación media es cero. Lo que hemos hecho es por lo
tanto calcular una puntuación típica: nos indica, utilizando los términos con-
vencionales, en cuántas desviaciones típicas (o errores típicos) se aparta
nuestra correlación de una correlación media de cero. Y ya sabemos (por las
tablas de la distribución normal) que un valor que se aparte de la media en
más de 1.96 desviaciones (fijándonos en ambos extremos de la distribución)
sólo ocurre por azar 5 veces de cada 100 o menos.
Por ejemplo: encontramos una correlación de r = .14 en una muestra de
275 sujetos; aplicando la fórmula [8] (más sencilla que la [7]) tendremos que
que supera el valor de z = 1.96 por lo que podemos
concluir que una correlación de r = .14 en esa muestra, en el caso de no rela-
ción, la obtendríamos por azar menos de cinco veces de cada 100 (p .05);
nuestra conclusión será que esa correlación es estadísticamente significativa.
c) Cuando de los mismos sujetos tenemos varios coeficientes de
correlación
En vez de aplicar la fórmula [7] o la fórmula [8] a cada coeficiente, pode-
mos construir nuestras propias tablas, cuando el número de sujetos es siem-
pre el mismo y los valores de z de interés también son siempre los mismos
(los que figuran en la tabla 6). En la fórmula [7] podemos despejar los valores
de r que nos interesan:
Si podemos despejar r;
Esta fórmula queda simplificada de esta manera: [9]
Por ejemplo, si nuestros sujetos son N = 212, nuestras tablas serán estas9
:
Para p ⭐ .05
Para p ⭐ .01
Para p ⭐ .001
CONCEPTO DE CORRELACIÓNYCOVARIANZA
141
9
Dado un número determinado de sujetos (N) los valores correspondientes a .05,
.01 y .001 nos lo da directamente Department of Obstetrics and Gynaecology, The Chine-
se University of Hong Kong http://department.obg.cuhk.edu.hk/ResearchSupport/Correla-
tion.asp, buscando minimum r to be significant. Esta dirección, y otras que nos dan la
misma información, también está en el Anexo II.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-141-320.jpg)
![3.6. Los intervalos de confianza: magnitud de la correlación en la
población
Si calculamos el coeficiente de correlación, por ejemplo, entre una medi-
da de motivación y otra de rendimiento escolar, encontraremos un valor de-
terminado en nuestra muestra. Puede ser que nuestro interés no esté en co-
nocer el grado de relación entre estas dos variables en una muestra concreta,
sino en la población más general representada por esa muestra10
.
Si lo que nos interesa es la magnitud de la correlación en la población (y
no solamente en nuestros sujetos), el valor exacto de la correlación en la po-
blación no podemos saberlo, pero sí podemos estimar entre qué valores má-
ximo y mínimo se encuentra. Estos valores extremos se denominan, muy
apropiadamente, intervalos de confianza.
El modelo teórico es semejante al visto antes para ver si una correlación es
estadísticamente significativa; la diferencia está en que antes (figura 4) supo-
níamos una correlación media de cero en la población y ahora (figura 5) la co-
rrelación media estimada en la población es la obtenida en una muestra.
Si calculamos el coeficiente de correlación entre las mismas dos variables
en un gran número de muestras, tendríamos una distribución normal de los
coeficientes de correlación entre las dos variables.
La correlación calculada en nuestra muestra la tomamos como una esti-
mación de la media en la población. Esta estimación será más ajustada si la
muestra es realmente representativa.
El error típico (desviación típica) de esta distribución lo estimamos a par-
tir de los datos de una muestra concreta y las fórmulas son:
para muestras grandes sr = [10]
para muestras pequeñas sr = [11]
El error típico, lo mismo que una desviación típica, nos indica el margen
de variabilidad probable (de oscilación) de los coeficientes de correlación si
los calculáramos en muchas muestras. Como suponemos una distribución
normal, el 95% de los casos de los coeficientes de correlación caen entre la
correlación obtenida en la muestra (la media de la distribución) más 1.96
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
142
10
En este apartado, lo mismo que en el anterior, no nos limitamos a hablar de la co-
rrelación obtenida en una muestra concreta que describe la relación entre dos variables en
esa muestra, sino que estamos tratando de la correlación en la población. Cuando a par-
tir de los datos obtenidos en una muestra deducimos los valores probables en la población
(extrapolamos) estamos ya en estadística inferencial y no meramente descriptiva.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-142-320.jpg)
![Por ejemplo: en una muestra de 102 sujetos encontramos una correlación
de r = .20;
Aplicando la fórmula [8] tendríamos z = = 2.01, p .05 (su-
peramos el límite de 1.96, tabla 6). La correlación de .20 en una muestra de
102 sujetos es estadísticamente significativa (no es cero en la población).
Si calculamos la correlación entre las mismas dos variables en una serie in-
definida de muestras ¿Entre qué límites oscilarían los coeficientes de correla-
ción?
El error típico de los coeficientes de correlación (con N = 102) sujetos es
(fórmula [10]):
errores típicos y la correlación obtenida menos 1.96 errores típicos. Estos son
los intervalos de confianza de la correlación, como podemos ver represen-
tado en la figura 5 (con un nivel de significación de .05).
CONCEPTO DE CORRELACIÓNYCOVARIANZA
143
-1.96 errores típicos
Correlación obtenida en la muestra =
estimación de la correlación en la población
+1.96 errores típicos
Límite máximo
probable en la
población
95% de los
coeficientes
de correlación en
muestras de la
misma población
Límite mínimo
probable en la
población
Figura 5
Límite más bajo de la correlación en la población:
.20 (media) – (1.96)(.099) = .005
Límite más alto de la correlación en la población:
.20 (media) + (1.96)(.099) = .394
Asumiendo la correlación que hemos encontrado de r = .20 como una esti-
mación de la correlación media, podemos afirmar que el coeficiente de corre-
lación en la población representada por esta muestra estará entre.005 y .394.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-143-320.jpg)
![Vemos que entre estos límites extremos probables no se encuentra el ce-
ro, por eso la correlación es estadísticamente significativa (distinta de cero
en la población), aunque el límite inferior es casi cero.
Vamos a ver un ejemplo de correlación no estadísticamente significativa.
En una muestra de N = 120 y r = .14 vemos que (fórmula [8])
z = .14 120 – 1 = 1.53
Como no llegamos al valor crítico de 1.96 concluimos que p .05; la pro-
babilidad de obtener un coeficiente de esa magnitud es superior al 5%. Nues-
tra conclusión será que esta correlación no es estadísticamente significativa.
Calculamos ahora los límites extremos (intervalos de confianza) de ese
coeficiente en la población:
1
Límite inferior: .14 – 1.96 (–––––––––) = .14 - .179 = -.04
120 – 1
1
Límite superior: .14 + 1.96 (–––––––––) = .14 + .179 = +.319
120 – 1
En la población esa correlación estará entre -.04 y + .319; como el límite
inferior es negativo (-.04) entre esos intervalos está la posibilidad de encon-
trar r = 0, por eso decimos que no es estadísticamente significativa; porque
puede ser r = 0 en la población. Siempre que los límites extremos son de dis-
tinto signo, la correlación no es estadísticamente significativa (el cero es un
valor probable porque está comprendido entre esos límites).
Cuando un coeficiente de correlación calculado en una muestra es esta-
dísticamente significativo, la información que tenemos sobre la magnitud
de la correlación en la población representada por esa muestra es por lo
tanto muy imprecisa, aunque podemos afirmar que no es cero. Para esti-
mar la magnitud de la correlación en la población con una mayor preci-
sión (entre unos límites estrechos) nos hacen falta muestras muy grandes
porque al aumentar el tamaño de la muestra disminuye el error típico.
Podemos verlo de manera más gráfica calculando los intervalos de confian-
za (límites máximo y mínimo en la población) de un coeficiente de .20 calcu-
lado en muestras de tamaño progresivamente mayor (tabla 7).
Un coeficiente de correlación de r = .20 calculado con una muestra gran-
de nos da una idea más precisa (límites extremos más estrechos) de dónde se
encuentra este valor en la población.
Con frecuencia vemos en la literatura experimental resultados conflictivos:
correlaciones grandes y positivas en una muestra y bajas o incluso negativas en
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
144](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-144-320.jpg)
![otras muestras… esta conflictividad suele ser aparente como podemos com-
probar si calculamos entre qué límites pueden oscilar estos coeficientes: cual-
quiera de los dos coeficientes podrían caer dentro de los límites del otro11
.
Aquí es oportuno hacer dos observaciones:
1. Cuando calculamos los intervalos de confianza de un coeficiente de
correlación (o de cualquier otro estadístico) estamos comprobando también
si ese coeficiente de correlación es estadísticamente significativo (si está
dentro de lo probable una correlación igual a cero en la población).
Por ejemplo, con N = 120 obtenemos una correlación de r = .15. Este co-
eficiente lo hemos calculado en una muestra concreta y ahora nos pregunta-
mos entre qué límites se encuentra ese coeficiente de correlación en la pobla-
ción representada por esa muestra.
El error típico es (fórmula [10]) 1 / 120 –1 = .0916, luego los límites es-
tarán entre .15 ± (1.96)(.0916); como (1.96)(.0916) = .179, los límites estarán
entre .15 ± .179:
Límite mínimo: .15-.179 = -.03 Límite máximo: .15 + .179 = .33
En la población esa correlación de .15, calculada en 120 sujetos, se en-
cuentra entre -.03 y + .33, el límite mínimo tiene signo menos, luego cero es
un valor posible; no se trata por lo tanto de una correlación estadísticamente
CONCEPTO DE CORRELACIÓNYCOVARIANZA
145
11
Los intervalos de confianza del coeficiente de correlación también podemos cal-
cularlos muy fácilmente en programas de Internet (Anexo II; uno muy cómodo es el de
VassarStats).
Tabla 7](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-145-320.jpg)







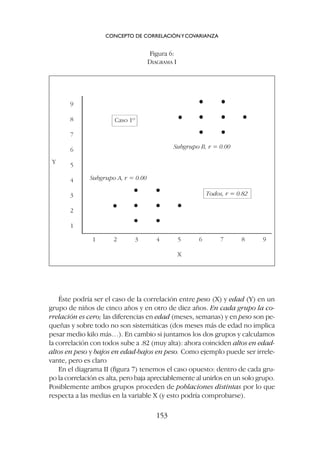
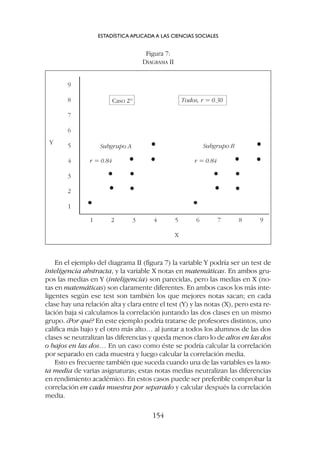
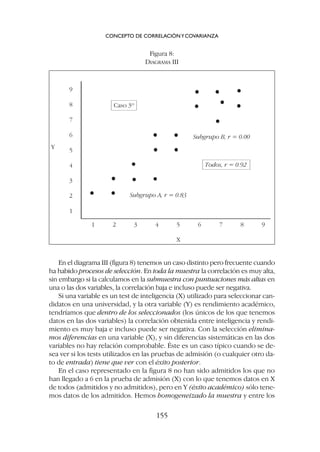
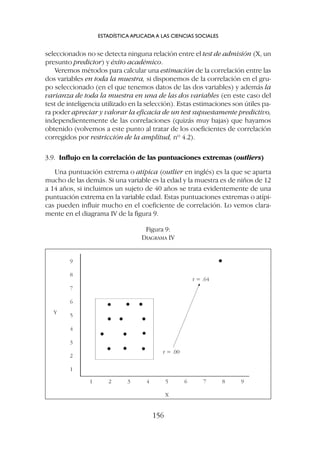
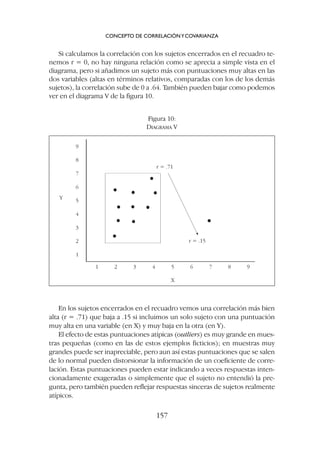

![las diferencias en una de las variables y naturalmente bajan los coefi-
cientes de correlación (explicado antes a propósito del diagrama III, fi-
gura 8).
3º Cuando calculamos la correlación entre una parte y el todo (como en-
tre un ítem y la puntuación total de la que forma parte ese ítem) en es-
te caso la correlación sube artificialmente y da una idea incorrecta so-
bre la verdadera relación entre esa parte y el todo.
Para estas situaciones, que son frecuentes, disponemos de fórmulas co-
rrectoras que nos dan una estimación de la verdadera correlación (o la corre-
lación exacta como en el caso 3º).
4.1. Correlación y fiabilidad: los coeficientes de correlación
corregidos por atenuación
Ya hemos indicado antes que la verdadera relación puede ser mayor que la
que muestra un determinado coeficiente, debido a la falta de fiabilidad de los
instrumentos de medición. Si el instrumento (test, escala, etc.) no detecta con
precisión las diferencias que hay entre los sujetos, la correlación calculada pue-
de ser inferior a la real (o superior en el caso de las correlaciones parciales)23
.
Este apartado, que es importante situarlo en el contexto de los coeficien-
tes de correlación, supone un estudio previo de lo que son los coeficientes de
fiabilidad, pero se puede entender con sólo una noción básica de lo que es
la fiabilidad (precisión en la medida).
4.1.1. Fórmula de corrección por atenuación
Disponemos de unas fórmulas que nos permiten estimar cual sería el co-
eficiente de correlación si la fiabilidad fuera perfecta. Se denominan fórmulas
de corrección por atenuación porque el coeficiente de correlación está ate-
nuado (disminuido) por la falta de fiabilidad de los instrumentos.
La fórmula general de la correlación corregida por atenuación es:
CONCEPTO DE CORRELACIÓNYCOVARIANZA
159
23
Una buena exposición de los efectos de la baja fiabilidad en los coeficientes de co-
rrelación y de la corrección por atenuación puede verse en Osborne (2003).
rxx y ryy son los coeficientes de fiabilidad
de cada medida; en el denominador pue-
de estar también sólo la fiabilidad de uno
de los instrumentos si la del otro nos es
desconocida, como aparece más adelante
en la fórmula [13].](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-159-320.jpg)





![Rxy = estimación de rxy si la calculáramos en toda la muestra inicial;
rxy = correlación entre X e Y obtenida en la muestra seleccionada;
si = desviación típica en X calculada en toda la muestra inicial (ad-
mitidos y no admitidos)
ss = desviación típica calculada en X en la muestra seleccionada (ad-
mitidos solamente)
Ésta es la fórmula que suele encontrarse en los textos (y por esta razón la
ponemos aquí), pero esta otra expresión [17] de la misma fórmula [16] pue-
de resultar más sencilla28
:
prueba objetiva de rendimiento). Podemos encontrarnos con que la correla-
ción es muy pequeña y concluir que el test no es válido (hay una relación muy
pequeña entre el predictor y el criterio). Esta conclusión puede ser discutible:
la correlación la hemos calculado solamente con los alumnos admitidos y no
con todos los que se presentaron inicialmente y de los que tenemos datos en
el test X. La varianza en X de los admitidos es lógicamente más pequeña que
la varianza calculada en todos los que se presentaron, admitidos y no admiti-
dos, y una varianza menor (grupo más homogéneo) hace bajar la correlación
entre X e Y.
En estas situaciones podemos estimar la correlación entre X e Y en el ca-
so de que todos hubieran sido admitidos. Esta correlación (se trata de una es-
timación), calculada con todos los presentados, es la que podría darnos una
idea mejor sobre la validez predictiva del test X.
Esta correlación estimada se puede calcular mediante esta fórmula:
CONCEPTO DE CORRELACIÓNYCOVARIANZA
165
28
Puede verse comentada en Hunter y Schmidt (1990, pp.125ss); los coeficientes de
correlación corregidos por restricción de la amplitud están bien tratados en Guilford y
Fruchter (1973)
si
donde U = ––––
ss
y Rxy y rxy como antes](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-165-320.jpg)
![Por ejemplo: en un test de selección para entrar en una universidad en-
contramos que
En la muestra inicial (todos los candidatos que se presentan a la selec-
ción, incluidos naturalmente los que no admitidos) la desviación típica es
sinicial = 6
En la muestra seleccionada la desviación típica es
sseleccionada = 3
La correlación entre el test de selección y un criterio (por ejemplo, nota
media al terminar el primer curso) es de .30; esta correlación la calculamos
solamente en la muestra seleccionada, como es natural. Podemos preguntar-
nos ¿Cuál hubiera sido esta correlación si la hubiéramos podido calcular en
toda la muestra que se presentó al examen de admisiones?
Substituyendo tenemos:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
166
En la primera fórmula [16]:
En la segunda fórmula [17] (U = 6/3 = 2)
El diferente redondeo de los decimales en los diferentes pasos hace que
los resultados no sean siempre exactamente iguales, pero la diferencia es pe-
queña. Vemos que la correlación ha subido de .31 (calculada con los seleccio-
nados) a .41 (una estimación de la que hubiéramos obtenido si todos hubie-
ran sido admitidos).
4.3. Corrección de las correlaciones de una parte con el todo
A veces nos interesa conocer la correlación entre una parte y un total al
que esa parte también contribuye.
El ejemplo más común (no el único posible) es cuando calculamos la co-
rrelación entre cada uno de los ítems de un test o escala y el total del test. Es-
te cálculo es interesante: a mayor correlación entre un ítem y el total, más tie-
ne que ver ese ítem con lo que miden los demás ítems (son los que](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-166-320.jpg)
![ri(T-i) = Correlación entre un ítem (o parte de un total) y el total me-
nos ese ítem (o correlación entre un ítem y la suma de todos
los demás)
riT = Correlación ítem-total
si y sT: desviaciones típicas del ítem y del total
Sobre esta corrección:
a) Suponemos que la correlación de cada ítem con el total (con la suma
de todos los ítems, riT) está calculada con un programa de ordenador,
lo mismo que las desviaciones típicas de los ítems y de los totales. Con
estos datos es fácil aplicar esta fórmula [18] (o programarla).
b) Cuando los ítems son muchos la diferencia entre riT y ri(T-i)
es pequeña.
c) En estas situaciones y para valorar estos coeficientes, es útil estimar cuál
sería el valor medio de la correlación de cada ítem con el total cuando 1)
realmente no hay relación (correlación cero entre los ítems) y 2) todos
los ítems o partes tuvieran igual varianza; en este caso la fórmula [18]
nos da la estimación de la correlación de cada ítem con el total 31
:
donde k es el número de ítems
discriminan más, y los que mejor representan el constructo subyacente o ras-
go que se desea medir). En la construcción y análisis de instrumentos de me-
dición este paso es de mucho interés.
El problema surge del hecho de que ese ítem también está sumado en el
total, con lo que la correlación resultante es artificialmente alta. En realidad lo
que nos interesa es la correlación de cada ítem con la suma de todos los de-
más, es decir, con el total menos el ítem en cuestión.
En algunos programas de ordenador29
ya está programada la correlación
de cada ítem con el total menos el ítem, pero no siempre disponemos de es-
tos programas. A veces lo más cómodo (cuando no se dispone de un progra-
ma adecuado) es calcular la correlación de cada ítem con el total, sin más30
.
En este caso estas correlaciones artificialmente altas podemos dejarlas en su
magnitud exacta aplicando después la fórmula [18].
CONCEPTO DE CORRELACIÓNYCOVARIANZA
167
29
Como en el SPSS, en Analizar-Escalas-Análisis de la Fiabilidad.
30
Podemos hacerlo fácilmente con una hoja de cálculo tipo EXCEL.
31
Guilford y Fruchter, 1973:321.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-167-320.jpg)












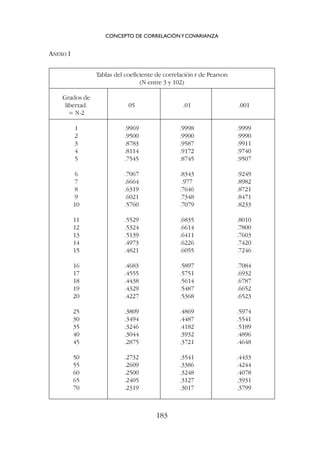










![puntuaciones totales (al sumar todas sus respuestas a los ítems) son distin-
tas, se deben:
1º En parte a que los sujetos son distintos en aquello que se les está mi-
diendo; si se trata de un examen hay diferencias porque unos saben
más y otros saben menos.
2º Las diferencias observadas se deben también en parte a lo que llama-
mos genéricamente errores de medición; por ejemplo, en este caso,
las respuestas distintas pueden estar ocasionadas por preguntas ambi-
guas, por la diferente capacidad lectora de los sujetos, etc.; no todo lo
que hay de diferencia se debe a que unos saben más y otros saben
menos.
La puntuación total de un sujeto podemos por lo tanto descomponerla
así:
Xt = Xv + Xe [1]
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
194
Xt = puntuación total de un sujeto, puntua-
ción observada;
Xv = puntuación verdadera, que representa
lo que un sujeto realmente sabe o sien-
te (depende de qué se esté preguntan-
do o midiendo).
Xe = puntuación debida a errores de medi-
ción, que puede tener signo más o sig-
no menos.
Lo que decimos de cada puntuación individual lo podemos decir también
de las diferencias entre todos los sujetos:
Diferencias
observadas
entre los sujetos
= +
Diferencias verdaderas
los sujetos son distin-
tos en lo que estamos
midiendo.
Diferencias falsas
(errores de medición)
Hablando con propiedad, más que de diferencias concretas hay que hablar
de varianza, que cuantifica todo lo que hay de diferencia entre los sujetos.
La fórmula básica de la fiabilidad parte del hecho de que la varianza se puede
descomponer. La varianza de las puntuaciones totales de un test podemos
descomponerla así [2]:
s2
t = s2
v + s2
e [2]](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-194-320.jpg)
![s2
v = Varianza total, expresa todo lo que hay de diferente en las puntua-
ciones totales; unos sujetos tienen puntuaciones totales más altas,
otros más bajas, etc.; la varianza será mayor si los sujetos difieren mu-
cho entre sí. Si lo que pretendemos con un instrumento de medida es
clasificar, detectar diferencias, una varianza grande estará asociada
en principio a una mayor fiabilidad.
s2
e = Varianza verdadera; expresa todo lo que hay de diferente debido a
que los sujetos son distintos en lo que pretendemos medir, o dicho
de otra manera, expresa todo lo que hay de diferente debido a lo que
los ítems tienen en común, de relación, y que es precisamente lo
que queremos medir. El término verdadero no hay que entenderlo
en un sentido cuasi filosófico, aquí la varianza verdadera es la que
se debe a respuestas coherentes (o respuestas relacionadas), y esta
coherencia (o relación verificada) en las respuestas suponemos que
se debe a que todos los ítems del mismo test miden lo mismo.
s2
t = Varianza debida a errores de medición, o debida a que los ítems mi-
den en parte cosas distintas, a lo que no tienen en común. Puede ha-
ber otras fuentes de error (respuestas descuidadas, falta de motiva-
ción al responder, etc.), pero la fuente de error que controlamos es la
debida a falta de relación entre los ítems, que pueden medir cosas
distintas o no muy relacionadas. El error aquí viene a ser igual a inco-
herencia en las respuestas, cualquiera que sea su origen (incoheren-
cia sería aquí responder no cuando se ha respondido sí a un ítem de
formulación supuestamente equivalente).
Suponemos que los errores de medición no están relacionados con las
puntuaciones verdaderas; no hay más error en las puntuaciones más altas o
menos en las más bajas y los errores de medición se reparten aleatoriamente;
con este supuesto la fórmula [2] es correcta.
La fiabilidad no es otra cosa que la proporción de varianza verdadera, y
la fórmula básica de la fiabilidad [3] se desprende de la fórmula anterior [2]
(r11 es el símbolo general de los coeficientes de fiabilidad):
s2
v
r11 = ––––– [3]
s2
t
Por varianza verdadera entendemos lo que acabamos de explicar; la va-
rianza total no ofrece mayor problema, es la que calculamos en los totales de
todos los sujetos; cómo hacemos operativa la varianza verdadera lo vere-
mos al explicar las fórmulas (de Cronbach y Kuder-Richardson). Expresando
la fórmula [3] en términos verbales tenemos que
LA FIABILIDAD DE LOS TETS Y ESCALAS
195](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-195-320.jpg)
![todo lo que discriminan los ítems por lo que tienen de relacionados
fiabilidad = ———————————————————————————
todo lo que discriminan de hecho al sumarlos en una puntuación total
o expresado de otra manera
varianza debida a lo que hay de coherente en las respuestas
fiabilidad = ———————————————————————————
varianza debida tanto a lo que hay de coherente como
de no coherente en las respuestas
Por respuestas coherentes hay que entender que no se responde de mane-
ra distinta a ítems que supuestamente y según la intención del autor del instru-
mento, expresan el mismo rasgo. En una escala de actitud hacia la música se-
ría coherente estar de acuerdo con estos dos ítems: me sirve de descanso
escuchar música clásica y la educación musical es muy importante en la
formación de los niños; lo coherente es estar de acuerdo con las dos afirma-
ciones o no estar tan de acuerdo también con las dos. Un sujeto que esté de
acuerdo con una y no con la otra es de hecho incoherente según lo que pre-
tende el autor del instrumento (medir la misma actitud a través de los dos
ítems). Esta incoherencia de hecho no quiere decir que el sujeto no sea cohe-
rente con lo que piensa; lo que puede y suele suceder es que los ítems pueden
estar mal redactados, pueden ser ambiguos, medir cosas distintas, etc.; por es-
tas razones la fiabilidad hay que verificarla experimentalmente.
En la varianza total (todo lo que hay de diferencias individuales en las
puntuaciones totales) influye tanto lo que se responde de manera coheren-
te o relacionada, como lo que hay de incoherente o inconsistente (por la
causa que sea); la fiabilidad expresa la proporción de consistencia o cohe-
rencia empírica.
En el denominador tenemos la varianza de los totales, por lo tanto la fia-
bilidad indica la proporción de varianza debida a lo que los ítems tienen en
común. Una fiabilidad de .80, por ejemplo, significa que el 80% de la varian-
za se debe a lo que los ítems tienen en común (o de relacionado de hecho).
4. REQUISITOS PARA UNA FIABILIDAD ALTA
Si nos fijamos en la fórmula anterior [3] (y quizás con más claridad si nos
fijamos en la misma fórmula expresada con palabras), vemos que aumentará
la fiabilidad si aumenta el numerador; ahora bien, es importante entender
que aumentará el numerador si por parte de los sujetos hay respuestas distin-
tas (no todos los sujetos responden de la misma manera) y a la vez relacio-
nadas, de manera que tendremos una fiabilidad alta:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
196](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-196-320.jpg)
![1º Cuando haya diferencias en las respuestas a los ítems, es decir,
cuando los ítems discriminan; si las respuestas son muy parecidas (to-
dos de acuerdo, o en desacuerdo, etc.) la varianza de los ítems baja y
también la fiabilidad;
2º Y además los ítems (las respuestas) estén relacionadas entre
sí, hay coherencia, consistencia interna; cuando si se responde muy
de acuerdo a un ítem, también se responde de manera parecida a
ítems distintos pero que expresan, suponemos, el mismo rasgo; hay
una tendencia generalizada responder o en la zona del acuerdo o en la
zona del desacuerdo.
Entender cómo estos dos requisitos (respuestas distintas en los sujetos y
relacionadas) influyen en la fiabilidad es también entender en qué consiste la
fiabilidad en cuanto consistencia interna. Esto lo podemos ver con facilidad
en un ejemplo ficticio y muy simple en el que dos muestras de cuatro sujetos
responden a un test de dos ítems con respuestas sí o no (1 ó 0) (tabla 1).
Tabla1
Podemos pensar que se trata de una escala de integración familiar com-
puesta por dos ítems y respondida por dos grupos de cuatro sujetos cada
uno. Los ítems en este ejemplo podrían ser:
1. En casa me lo paso muy bien con mis padres [sí=1 y no =0]
2. A veces me gustaría marcharme de casa [sí = 0 y no = 1]
En estos ejemplos podemos observar:
1º Las desviaciones típicas (lo mismo que las varianzas, s2
) de los ítems
son idénticas en los dos casos, además son las máximas posibles (por-
que el 50% está de acuerdo y el otro 50% está en desacuerdo, máxima
dispersión). Desviaciones típicas grandes en los ítems (lo que supone
LA FIABILIDAD DE LOS TETS Y ESCALAS
197](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-197-320.jpg)



![5. LAS FÓRMULAS DE KUDER RICHARDSON 20 Y a DE CRONBACH
Las dos fórmulas posiblemente más utilizadas son las de Kuder-Richardson
20 y el coeficiente a de Cronbach. En realidad se trata de la misma fórmula,
una (Kuder-Richardson) expresada para ítems dicotómicos (con respuestas
de unos y ceros) y otra (Cronbach) para ítems continuos (con varias respues-
tas graduadas de menos a más, como en las escalas de actitudes). Los nom-
bres distintos se deben a que los autores difieren en sus modelos teóricos,
aunque estén relacionados, y los desarrollaron en tiempos distintos (Kuder y
Richardson en 1937, Cronbach en 1951).
Para hacer operativa la fórmula [3]
s2
v
r11 = ––––– [3]
s2
t
El denominador no ofrece mayor problema, se trata de la varianza de las
puntuaciones totales del test o instrumento utilizado.
El numerador, o varianza verdadera, lo expresamos a través de la suma
de las covarianzas de los ítems. Es útil recordar aquí qué es la co-varianza.
Conceptualmente la co-varianza es lo mismo que la co-relación; en el coe-
ficiente de correlación utilizamos puntuaciones típicas y en la covarianza uti-
lizamos puntuaciones directas, pero en ambos casos se expresa lo mismo y si
entendemos qué es la correlación, entendemos también qué es la covarianza
o variación conjunta. La varianza verdadera la definimos operativamente
como la suma de las covarianzas de los ítems.
La covarianza entre dos ítems expresa lo que dos ítems discriminan por
estar relacionados, esto es lo que denominamos en estas fórmulas varianza
verdadera, por lo tanto la fórmula [3] podemos expresarla poniendo en el
numerador la suma de las covarianzas entre los ítems:
o lo que es lo mismo ya que
La covarianza entre dos ítems (sxy) es igual al producto de su correlación
(rxy) por sus desviaciones típicas (sx y sy): ahí tenemos la varianza verdade-
ra: diferencias en las respuestas a los ítems (expresadas por las desviaciones
típicas) y relacionadas (relación expresada por los coeficientes de correla-
ción entre los ítems). Se trata por lo tanto de relaciones empíricas, verifica-
das, no meramente lógicas o conceptuales.
LA FIABILIDAD DE LOS TETS Y ESCALAS
201](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-201-320.jpg)
![Esta fórmula [5] de la fiabilidad no es, por supuesto cómoda para calcular-
la (tenemos otras alternativas) pero pone de manifiesto qué es lo que influye
en la fiabilidad, por eso es importante.
Aumentará la fiabilidad si aumenta el numerador. Y lo que tenemos en el
numerador (fórmula [5]) es la suma de las covarianzas de los ítems (Ssxy =
Srxysxsy) que expresa a) todo lo que discriminan los ítems (y ahí están sus
desviaciones típicas) y b) por estar relacionados (y tenemos también las co-
rrelaciones inter-ítem).
Si nos fijamos en la fórmula [5] vemos que si los ítems no discriminan (no
establecen diferencias) sus desviaciones típicas serán pequeñas, bajará el nu-
merador y bajará la fiabilidad.
Pero no basta con que haya diferencias en los ítems, además tienen que es-
tar relacionados; la correlación entre los ítems también está en el numerador
de la fórmula [5]: si las desviaciones son grandes (como en el grupo B de la
tabla 1) pero los ítems no están relacionados (= respuestas no coherentes),
bajará la fiabilidad, porque esa no relación entre los ítems hace que las pun-
tuaciones totales estén menos diferenciadas, como sucede en el grupo B. En
este caso vemos que cuando las desviaciones de los ítems son muy grandes,
pero la correlación inter-ítem es igual a 0, la fiabilidad es también igual a 0.
La fiabilidad expresa por lo tanto cuánto hay de diferencias en los totales
debidas a respuestas coherentes (o proporción de varianza verdadera o de-
bida a que los ítems están relacionados). Por eso se denomina a estos coefi-
cientes coeficientes de consistencia interna: son mayores cuando las relacio-
nes entre los ítems son mayores. La expresión varianza verdadera puede
ser equívoca; en este contexto varianza verdadera es la debida a que los ítems
están relacionados, son respondidos de manera básicamente coherente, pe-
ro no prueba o implica que de verdad todos los ítems midan lo mismo.
Esta relación empírica, verificable, entre los ítems nos sirve para apoyar
o confirmar (pero no probar) la relación conceptual que debe haber entre
los ítems (ya que pretendidamente miden lo mismo), aunque esta prueba no
es absoluta y definitiva y requerirá matizaciones adicionales (dos ítems pue-
den estar muy relacionados entre sí sin que se pueda decir que miden lo mis-
mo, como podrían ser edad y altura).
La fórmula [4] puede transformarse en otra de cálculo más sencillo. Se
puede demostrar fácilmente que la varianza de un compuesto (como la va-
rianza de los totales de un test, que está compuesto de una serie de ítems que
se suman en una puntuación final) es igual a la suma de las covarianzas en-
tre los ítems (entre las partes del compuesto) más la suma de las varianzas
de los ítems:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
202
de donde](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-202-320.jpg)
![La expresión [k/(k-1)] (k= número de ítems) la añadimos para que el va-
lor máximo de este coeficiente pueda llegar a la unidad. El segundo miembro
de esta fórmula [8], que es el que realmente cuantifica la proporción de va-
rianza debida a lo que los ítems tienen en común o de relacionado, puede al-
canzar un valor máximo de [(k-1)/k] y esto solamente en el caso improbable
de que todas las varianzas y covarianzas sean iguales. Como [(k-1)/k] x [k/(k-
1)]= 1, al añadir a la fórmula el factor [k/(k-1)] hacemos que el valor máximo
posible sea 1.
La fórmula [8], tal como está expresada, corresponde al a de Cronbach
(para ítems continuos); en la fórmula Kuder-Richardson 20 (para ítems dico-
tómicos, respuesta 1 ó 0) sustituimos Ss2
i por Spq pues pq es la varianza de
los ítems dicotómicos (p = proporción de unos y q = proporción de ceros).
La parte de la fórmula [8] que realmente clarifica el sentido de la fiabilidad
está en el segundo miembro que, como hemos visto, equivale a Srxysxsy/s2
t
(suma de las covarianzas de todos los ítems dividida por la varianza de los to-
tales, fórmulas [4] y [5]).
6. FACTORES QUE INCIDEN EN LA MAGNITUD DEL COEFICIENTE DE FIABILIDAD
Es útil tener a la vista los factores o variables que inciden en coeficientes
de fiabilidad altos. Cuando construimos y probamos un instrumento de me-
dición psicológica o educacional nos interesa que su fiabilidad no sea baja y
conviene tener a la vista qué podemos hacer para obtener coeficientes altos.
Además el tener en cuenta estos factores que inciden en la magnitud del co-
eficiente de fiabilidad nos ayuda a interpretar casos concretos.
En general los coeficientes de fiabilidad tienden a aumentar:
y sustituyendo en [4] tenemos que
de donde
número de ítems
suma de las varianzas de los ítems
varianza de los totales
La fórmula que sin embargo utilizamos es esta otra y que corresponde al
coeficiente s de Cronbach [8]:
LA FIABILIDAD DE LOS TETS Y ESCALAS
203](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-203-320.jpg)


![tendemos medir. Es más, sin diferencias entre los sujetos no puede haber un
coeficiente de fiabilidad alto. La fiabilidad es una característica positiva siem-
pre que interese detectar diferencias que suponemos que existen. Esto suce-
de cuando medimos rasgos de personalidad, actitudes, etc., medir es, de al-
guna manera, establecer diferencias.
5. Una observación importante: la interpretación de estos coeficientes,
como característica positiva o deseable, puede ser distinta cuando se trata de
comprobar resultados escolares en los que no hay diferencias o no se preten-
de que existan, por ejemplo en un examen de objetivos mínimos, o si se tra-
ta de verificar si todos los alumnos han conseguido determinados objetivos. A
la valoración de la fiabilidad en exámenes y pruebas escolares le dedicamos
más adelante un comentario específico (apartado 11).
La valoración de una fiabilidad alta como característica positiva o de cali-
dad de un test es más clara en los tests de personalidad, inteligencia, etc., o
en las escalas de actitudes: en estos casos pretendemos diferenciar a los su-
jetos, captar las diferencias que de hecho se dan en cualquier rasgo; digamos
que en estos casos las diferencias son esperadas y legítimas. Además en este
tipo de tests también pretendemos medir (en un sentido analógico) un úni-
co rasgo expresado por todos los ítems, mientras que en el caso de un exa-
men de conocimientos puede haber habilidades muy distintas, con poca rela-
ción entre sí, en el mismo examen (aunque tampoco esto es lo más habitual).
Aun con estas observaciones, en un examen largo, tipo test, con muchos o
bastantes alumnos, entre los que esperamos legítimamente que haya diferen-
cias, una fiabilidad baja sí puede ser un indicador de baja calidad del instru-
mento, que no recoge diferencias que probablemente sí existen.
6. Índice de precisión. Hemos visto que el coeficiente de fiabilidad ex-
presa una proporción, la proporción de varianza verdadera o varianza debi-
da a lo que los ítems tienen en común. También sabemos que un coeficiente
de correlación elevado al cuadrado (r2
, índice de determinación) expresa
una proporción (la proporción de varianza compartida por dos variables). Es-
to quiere decir que la raíz cuadrada de una proporción equivale a un coefi-
ciente de correlación (si r2
= proporción, tenemos que = r).
En este caso la raíz cuadrada de un coeficiente de fiabilidad equivale al co-
eficiente de correlación entre las puntuaciones obtenidas (con nuestro ins-
trumento) y las puntuaciones verdaderas (obtenidas con un test ideal que
midiera lo mismo). Este coeficiente se denomina índice de precisión (tam-
bién índice, no coeficiente, de fiabilidad).
índice de precisión ó robservadas.verdaderas
= [9]
Una fiabilidad de .75 indicaría una correlación de .86 con las
puntuaciones verdaderas. Este índice expresa el valor máximo que puede al-
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
206](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-206-320.jpg)





![el análisis factorial) nos pueden llevar a la conclusión de que los subconjun-
tos de ítems miden rasgos suficientemente distintos como para que sea cues-
tionable sumarlos en un total único. Consistencia interna (tal como la cuan-
tifican estos coeficientes) y unidimensionalidad son conceptos distintos,
por eso decimos que un coeficiente alto de fiabilidad es un apoyo pero no
una prueba de que el conjunto de ítems que componen el instrumento mi-
de un único rasgo bien conceptualizado.
9.1.2. Fiabilidad y número de ítems
El coeficiente de fiabilidad aumenta al aumentar el número de ítems;
¿quiere esto decir que los tests más largos son más homogéneos, que sus
ítems miden con más claridad el mismo rasgo? Obviamente no; los ítems no
están más relacionados entre sí por el mero hecho de ser más en número; el
mismo Cronbach (1951) lo expresaba así: un galón de leche no es más homo-
géneo que un vaso de leche; un test no es más homogéneo por el mero he-
cho de ser más largo.
El que al aumentar el número de ítems aumente la fiabilidad se debe, al
menos en parte, a un mero mecanismo estadístico: cuando aumenta el núme-
ro de ítems (con tal de que estén mínimamente relacionados entre sí) la su-
ma de las covarianzas entre los ítems (numerador de la fórmula [4]) aumen-
ta proporcionalmente más que la varianza de los totales (denominador de la
fórmula [4]). Una fiabilidad alta se puede obtener con muchos ítems con re-
laciones bajas entre sí, e incluso con algunas negativas; y puede suceder tam-
bién que (como ya hemos indicado) dos (o más) bloques de ítems con claras
correlaciones entre los ítems dentro de cada bloque, pero con poca o nula re-
lación con los ítems del otro bloque den para todo el test un coeficiente alto
de fiabilidad. En este caso la homogeneidad del conjunto, y la interpretación
de las puntuaciones como si expresaran un único rasgo bien definido puede
ser cuestionable.
Por lo tanto:
a) No se debe buscar una fiabilidad alta aumentando sin más el número de
ítems, sin pensar bien si son realmente válidos para expresar sin confu-
sión el rasgo que deseamos medir. Una fiabilidad alta no es un indicador
cuasi automático de la calidad de un test, sobre todo si es muy largo;
hace falta siempre una evaluación conceptual de los ítems (además de
verificar empíricamente su correlación con el total del instrumento).
b) Con frecuencia con un conjunto menor de ítems se puede conseguir
una fiabilidad semejante o no mucho más baja que si utilizamos todos
los ítems seleccionados en primer lugar, y varios subconjuntos de ítems
pueden tener coeficientes de fiabilidad muy parecidos.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
212](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-212-320.jpg)


![Esta distribución hubiera tenido su media y su desviación típica o error tí-
pico de la medición. Podemos suponer que la puntuación de hecho obteni-
da es la media de la distribución (aunque esto no es así exactamente, como
veremos después al tratar de las puntuaciones verdaderas).
El error típico de la medición se calcula a partir del coeficiente de fiabili-
dad, y en muchos casos el mejor uso del coeficiente de fiabilidad es utilizarlo
para calcular el error típico, (por ejemplo en exámenes o en cualquier test)
cuando interese situar a cada uno en su banda de posibles probables resulta-
dos. Esta banda de posibles resultados será más estrecha (con un error típico
menor) cuando la fiabilidad sea alta, y será más amplia cuando baje la fiabili-
dad. Una baja fiabilidad de un instrumento puede quedar neutralizada si utili-
zamos el error típico en la interpretación de las puntuaciones individuales.
La fórmula del error típico podemos derivarla con facilidad de las fórmulas
[2] y [3].
De la fórmula [2] podemos despejar la varianza verdadera: s2
v = s2
t - s2
e
s2
t – s2
e s2
e
y substituyendo esta expresión de s2
v en [3]: r11 = ———— = 1- ——
s2
t s2
t
s2
e
de donde —— = 1- r11 y despejando se tenemos que
s2
t
error típico [10]
Esta es la fórmula de la desviación típica de los errores de medición, deno-
minada error típico de la medida o de las puntuaciones individuales. Se cal-
cula a partir de la desviación típica (de los totales del test) y del coeficiente de
fiabilidad calculados en la muestra. Si un sujeto hubiera respondido a una se-
rie de tests paralelos semejantes, el error típico sería la desviación típica obte-
nida en esa serie de tests. Se interpreta como cualquier desviación típica e in-
dica la variabilidad probable de las puntuaciones obtenidas, observadas.
El error típico es directamente proporcional al número de ítems y en el ca-
so de los tests con respuestas 1 ó 0 (como en las pruebas objetivas) un cálcu-
lo rápido (y aproximado) es el dado en la fórmula [11]8
:
error típico [11]
LA FIABILIDAD DE LOS TETS Y ESCALAS
215
8
Puede verse explicado en Gardner (1970) y en Burton (2004). Hay varias fórmulas
que permiten cálculos aproximados del error típico, del coeficiente de fiabilidad y de otros
estadísticos que pueden ser útiles en un momento dado (por ejemplo, y entre otros, Sau-
pe, 1961; McMorris, 1972).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-215-320.jpg)
![Aquí hay que hacer una observación importante. Este error típico se apli-
ca en principio a todos los sujetos por igual; hay un error típico que indica la
oscilación probable de cada puntuación. Esto no es así exactamente. Pense-
mos en un examen: el alumno que sabe todo, en exámenes semejantes segui-
ría sabiendo todo, y el alumno que no sabe nada, en exámenes semejantes
seguiría sin saber nada: la oscilación probable en los extremos es menor que
en el centro de la distribución. Ésta es una limitación de esta medida del
error probable individual. Aun así es la medida más utilizada aunque hay
otras9
. Si la distribución es normal (o aproximadamente normal) y las pun-
tuaciones máximas y mínimas obtenidas no son las máximas o mínimas posi-
bles (la amplitud real no es igual a la amplitud máxima posible), éste error tí-
pico de la medida es más o menos uniforme a lo largo de toda la escala de
puntuaciones.
Aquí nos limitamos a exponer el error típico habitual, el que se utiliza nor-
malmente y que tiene aplicaciones muy específicas, pero en situaciones apli-
cadas (como en exámenes) sí conviene caer en la cuenta de que la posible va-
riabilidad individual tiende a ser menor en los extremos de la distribución.
9.2.2. Las puntuaciones verdaderas
Un punto importante para el cálculo e interpretación del error típico es
que el centro de la distribución de los posibles resultados no es para cada su-
jeto la puntuación que ha obtenido. Si un sujeto obtiene una puntuación de
120 y el error típico es de se = 4.47, no podemos concluir que hay un 68% de
probabilidades (aproximadamente, es la proporción de casos que suelen dar-
se entre ± 1s) de que su verdadera puntuación está entre 120 ± 4.47. El cen-
tro de la distribución no es en este caso la puntuación obtenida, sino la deno-
minada puntuación verdadera (Xv) que se puede estimar mediante la
fórmula [12]:
Estimación de la puntuación verdadera: X̄v = [(X-X̄) (r11)] + X̄ [12]
En el caso anterior si X̄ = 100 y r11 = .80, la estimación de la puntuación
verdadera de un sujeto que tuviera una puntuación de X = 120, sería [(120 -
100)(.80)] + 100 = 116. Si la fiabilidad es igual a 1, la puntuación obtenida es
también la que aquí denominamos verdadera.
Siguiendo con el mismo ejemplo, de un sujeto con X =120 y una puntua-
ción verdadera de 116, podemos decir que sus posibles resultados en ese test
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
216
9
En Mehrens y Lehmann (1973, pág. 106) puede verse cómo calcular el error típico
de cada sujeto; es una fórmula poco utilizada porque resulta laborioso calcularla para ca-
da sujeto y a efectos prácticos son suficientes las expuestas en el texto.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-216-320.jpg)

![9.3. Coeficientes de correlación corregidos por atenuación
En buena medida la utilidad de los coeficientes de fiabilidad está en los
cálculos adicionales que podemos hacer. Posiblemente el más importante, y
de utilidad práctica, es el del error típico de la medida que ya hemos visto.
Otra utilidad de estos coeficientes es que nos permiten calcular el valor de
un coeficiente de correlación entre dos variables corregido por atenuación.
La correlación calculada entre dos variables queda siempre disminuida,
atenuada, por culpa de los errores de medición, es decir, por su no perfec-
ta fiabilidad. La verdadera relación es la que tendríamos si nuestros instru-
mentos midieran sin error. Esta correlación corregida por atenuación es la
que hubiéramos obtenido si hubiésemos podido suprimir los errores de me-
dición en las dos variables (o al menos en una de las dos; no siempre conoce-
mos la fiabilidad de las dos variables).
Conociendo la fiabilidad de las dos variables podemos estimar la verdade-
ra relación mediante la fórmula [13]:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
218
En esta fórmula rxy es el coeficiente de correlación obtenido entre dos va-
riables, X e Y, y rxx y ryy son los coeficientes de fiabilidad de cada variable; si co-
nocemos solamente la fiabilidad de una de las dos variables, en el denomina-
dor tendremos solamente la raíz cuadrada de la fiabilidad conocida.
Por ejemplo si entre dos tests o escalas tenemos una correlación de .30 y
los coeficientes de fiabilidad de los dos tests son .50 y .70, la correlación esti-
mada corregida por atenuación sería:
Vemos que la correlación sube apreciablemente; y expresa la relación en-
tre las dos variables independientemente de los errores de medición de los
instrumentos utilizados.
Sobre estas estimaciones de la correlación entre dos variables (entre las
verdaderas puntuaciones de X e Y, sin errores de medición) ya se han hecho
una serie de observaciones al tratar sobre los coeficientes de correlación (en
el apartado 4.1. del capítulo sobre correlación y covarianza; ése es el contex-](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-218-320.jpg)





![típico a los alumnos que están en el límite del apto puede ser una buena
práctica (como ya se ha indicado en el apartado 9.2.3)14
.
12. FÓRMULAS DE LOS COEFICIENTES DE CONSISTENCIA INTERNA
Las fórmulas del coeficiente de fiabilidad son muchas, aquí exponemos las
más utilizadas. Podemos dividirlas en dos grupos:
1) Fórmulas que se basan en la partición del test en dos mitades
2) Fórmulas en las que se utiliza información de todos los ítems, como las
de Kuder-Richardson y Cronbach.
En cada uno de los apartados se incluyen otras fórmulas relacionadas o de-
rivadas. También exponemos otras formulas de interés, como las fórmulas
que relacionan la fiabilidad con el número de ítems.
Aunque vamos a repasar una serie de fórmulas, conviene adelantar (y po-
dría ser suficiente) que las fórmulas preferibles, y que deben utilizarse habi-
tualmente, son las de Kuder-Richardson [18] (para ítems dicotómicos) y el a
de Cronbach [20] (para ítems continuos); realmente se trata de la misma for-
mula (varían los símbolos) y es la que suele venir programada en los progra-
mas informáticos. Como cálculo aproximado y rápido de la fiabilidad la fór-
mula más cómoda es la formula [19] que veremos después, pero sólo si los
ítems son dicotómicos (puntúan 1 ó 0).
12.1. Fórmulas basadas en la partición del test en dos mitades
12.1.1. Cómo dividir un test en dos mitades
1. Como cualquier test puede dividirse en muchas dos mitades, puede ha-
ber muchos coeficientes de distintos de fiabilidad. El resultado es sólo una es-
timación que puede infravalorar o supervalorar la fiabilidad. Es habitual la
práctica de dividir el test en ítems pares e impares, pero puede dividirse en
dos mitades cualesquiera. Cada mitad debe tener el mismo número de ítems
o muy parecido.
2. Si al dividir el test en dos mitades emparejemos los ítems según sus con-
tenidos (matching), de manera que cada mitad del test conste de ítems muy
parecidos, obtendremos una estimación más alta y preferible de la fiabilidad.
14
Si en un examen tipo test sumamos a los que están justo debajo del límite propues-
to para el aprobado dos erres típicos nos ponemos prácticamente en el límite máximo pro-
bable al que hubiera llegado ese alumno.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
224](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-224-320.jpg)
![3. Cuando la mitad (o casi la mitad) de los ítems son positivos y la otra mi-
tad son negativos (favorables o desfavorables al rasgo medido, con distinta
clave de corrección), es útil que las dos mitades estén compuestas una por
los ítems positivos y otra por los negativos. En este caso la correlación entre
los dos tipos de ítems es muy informativa en sí misma, aunque no se calcule
después la fiabilidad por este procedimiento. Una correlación entre los dos
subtests en torno a .50 o mayor indica suficiente coherencia entre los dos ti-
pos de ítems, y que no se manifiesta de modo apreciable la aquiescencia o
tendencia a mostrar acuerdo (o responder sí) a ítems que expresan ideas con-
tradictorias.
12.1.2. Fórmulas
De estas fórmulas la primera y más clásica es la de Spearman-Brown; am-
bos autores derivaron las mismas fórmulas de manera independiente en 1910
(la fórmula básica de estos autores es la [21], de la que se derivan la [14], la
[22] y la [23]). La fórmula que se conoce habitualmente como procedimien-
to de las dos mitades (vamos a ver que además hay otras fórmulas) y no sue-
le faltar en ningún texto cuando se trata de la fiabilidad, es la fórmula [14].
2r12
r11 = ——— [14]
1 + r12
Fórmula de Spearman-Brown
r12 = correlación entre las dos mitades
del test. El test se divide en dos
mitades y se calcula la correlación
entre ambas como si se tratara de
dos tests.
1. La correlación entre las dos mitades es la fiabilidad de una de las dos
(pruebas paralelas); con esta fórmula [14] se calcula la fiabilidad de todo el
test. Observando la fórmula [14] puede verse que si r12 = 1, también tendre-
mos que r11 = 1.
2. La fórmula [14] supone que las dos mitades tienen medias y varianzas
idénticas; estos presupuestos no suelen cumplirse nunca, y de hecho con es-
ta fórmula se sobrestima la fiabilidad; por lo que está desaconsejada (a pesar
de su uso habitual); la fórmula de las dos mitades preferible es la conocida co-
mo dos mitades alpha (r2a) [15]15
:
15
Esta fórmula la aconsejan buenos autores (incluido el mismo Cronbach). La impor-
tancia del cálculo de la fiabilidad por el procedimiento de las dos mitades es sobre todo
histórica; el método de las pruebas paralelas (dos pruebas en vez de dos mitades) y el
de consistencia interna (en el que cada ítem funciona como una prueba paralela) parten
de la intuición original de las dos mitades de Spearman y Brown. Una crítica y valoración
de estas fórmulas puede verse en Charter (2001).
LA FIABILIDAD DE LOS TETS Y ESCALAS
225](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-225-320.jpg)
![12.2. Fórmulas de Kuder-Richardson y s
s de Cronbach
Se trata de las fórmulas de consistencia interna que hemos justificado an-
teriormente con mayor amplitud; son las más utilizadas17
.
a) Son métodos en principio preferibles porque con los métodos de las
dos mitades cabe dividir un test en muchas dos mitades con que las
que podemos obtener distintos valores del coeficiente de fiabilidad. El
resultado que nos dan las fórmulas de Kuder-Richardson y Cronbach
16
Esta fórmula también se conoce como fórmula de Rulon que es el primero que la
expuso (en 1939) aunque Rulon se la atribuye a Flanagan (Traub, 1994).
17
Este coeficiente de fiabilidad (Kuder-Richardson o Cronbach) se calcula en el SPSS
en la opción analizar, en escalas.
En esta fórmula entran también, además de la correlación de las dos mita-
des, las desviaciones típicas de cada mitad.
3. Otras fórmulas basadas en la partición de un test en dos mitades, y que
suelen encontrarse en algunos textos, son la [16] y la [17], que no requieren
el cálculo de la correlación entre las dos mitades; de todas maneras en estos
casos (partición del test en dos mitades) es siempre preferible la fórmula
[15].
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
226
Fórmula de Flanagan16
s2
1 y s2
2 son las varianzas de las dos
mitades,
s2
t es la varianza de todo el test
s2
d = Es la varianza de la diferen-
cia entre las dos mitades.
Cada sujeto tiene dos pun-
tuaciones, una en cada mi-
tad: a cada sujeto se le res-
tan ambas puntuaciones y
se calcula la varianza de es-
tas diferencias.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-226-320.jpg)
![equivale a la fiabilidad media que obtendríamos dividiendo un test en
todas sus posibles dos mitades; obtenemos un único coeficiente que es
una estimación más segura.
b) En los modelos teóricos de donde parten estas fórmulas se supone que
tanto las varianzas como las intercorrelaciones de los ítems son iguales;
esto no suele suceder por lo que estas fórmulas tienden a dar una esti-
mación de la fiabilidad algo baja.
c) Las fórmulas de Kuder-Richardson son válidas para ítems dicotómicos
(0 ó 1), y el coeficiente s de Cronbach para ítems con repuestas conti-
nuas (más de dos repuestas).
fórmula Kuder-Richardson 20
(para ítems dicotómicos)
Como ya sabemos, p es la proporción de unos (aciertos, síes, la respuesta
que se codifique con un 1) y q es la proporción de ceros (número de unos o
de ceros dividido por el número de sujetos).
Con ítems dicotómicos ésta es la fórmula [18] que en principio debe utili-
zarse. Si se tienen calculadas las varianzas o desviaciones típicas de cada ítem,
no es muy laboriosa.
Si el cálculo resulta laborioso y no se tiene ya programada la fórmula com-
pleta de la fiabilidad, hay otras alternativas más sencillas; la más utilizada es la
fórmula Kuder-Richardson 21.
k = número de ítems
Spq = suma de las varianzas de
los ítems
s2
t = varianza de los totales
fórmula Kuder-Richardson 21
k es el número de ítems;
X
–
y s2
t son la media y varianza de
los totales
1. Esta fórmula [19] se deriva de la anterior [18] si suponemos que todos
los ítems tienen idéntica media. En este caso tendríamos que:
Haciendo las sustituciones oportunas en [18] llegamos a la fórmula [19].
LA FIABILIDAD DE LOS TETS Y ESCALAS
227](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-227-320.jpg)
![2. Esta fórmula [19] es sencilla y cómoda, porque solamente requiere el
cálculo de la media y varianza de los totales, además del número de ítems, y es-
tos son datos que suelen estar siempre disponibles. La suposición de que to-
dos los ítems tienen idéntica media no suele cumplirse, por lo que esta fórmu-
la sólo da una estimación de la fiabilidad. Se utiliza frecuentemente para
calcular la fiabilidad de las pruebas objetivas (exámenes, evaluaciones) hechas
por el profesor y por lo menos indica por dónde va la fiabilidad; puede ser su-
ficiente para calcular el error típico y relativizar los resultados individuales.
Existen otras aproximaciones de la fórmula Kuder-Richardson 20, pero es
ésta la más utilizada.
Con ítems continuos, con más de una respuesta como los de las escalas
de actitudes, la fórmula apropiada es la del coeficiente a de Cronbach que es
una generalización de la Kuder-Richardson 20; es la fórmula [8] que ya vimos
antes:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
228
a de Cronbach para ítems continuos
k = número de ítems
Ss2
i = es la suma de las varian-
zas de los ítems
s2
t = es la varianza de los tota-
les
rkk = fiabilidad de un test com-
puesto por k ítems
r
-
ij = correlación media entre
los ítems
12.3. Fórmulas que ponen en relación la fiabilidad y el número de
ítems
1. La fórmula [14] se deriva de esta otra, denominada fórmula profética
de Spearman-Brown y que es la fórmula original de estos autores:
En la fórmula [14] hemos supuesto que k =2 y r
-
ij = r12. De la fórmula an-
terior [21] se derivan otras dos especialmente útiles, y que se pueden utilizar
aunque la fiabilidad no se calcule por el método de Spearman-Brown.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-228-320.jpg)
![Si en la fórmula [22] hacemos n = 2, tendremos la fórmula [14]; r12 es la
fiabilidad de una de las dos mitades, lo que nos dice la fórmula [14] es la fia-
bilidad del test entero (formado por las dos mitades)18
.
12.3.2. En cuánto debemos aumentar el número de ítems para
alcanzar una determinada fiabilidad
Posiblemente es más útil la fórmula siguiente [23]. Si tenemos una fiabili-
dad conocida (r11) y queremos llegar a otra más alta (esperada, rnn), ¿En cuán-
tos ítems tendríamos que alargar el test? En este caso nos preguntamos por el
valor de n, el factor por el que tenemos que multiplicar el número de ítems
que ya tenemos.
12.3.1. Cuánto aumenta la fiabilidad al aumentar el número de
ítems
Disponemos de una fórmula que nos dice (siempre de manera aproxima-
da) en cuánto aumentará la fiabilidad si aumentamos el número de ítems
multiplicando el número de ítems inicial, que ya tenemos, por un factor n. Es
en realidad una aplicación de la misma fórmula.
rnn = nuevo coeficiente de fiabilidad esti-
mado si multiplicamos el número de
ítems que tenemos por el factor n
r11 = coeficiente de fiabilidad conocido
n = factor por el que multiplicamos el
número de ítems
multiplicando por 2 el número inicial de
ítems llegaríamos a una fiabilidad en torno a
.80
Por ejemplo: tenemos una escala de actitudes de 10 ítems y una fiabilidad
de .65. La fiabilidad nos parece baja y nos preguntamos cuál será el coeficien-
te de fiabilidad si multiplicamos el número de ítems (10) por 2 (n = 2) y lle-
gamos así a 20 ítems (del mismo estilo que ya los que ya tenemos). Aplicando
la fórmula anterior [22] tendríamos:
LA FIABILIDAD DE LOS TETS Y ESCALAS
229
18
A partir de una fiabilidad obtenida con un número determinado de ítems puede ver-
se en Morales, Urosa y Blanco (2003) una tabla con la fiabilidad que obtendríamos multi-
plicando el número inicial de ítems por un factor n.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-229-320.jpg)

![Por ejemplo, si en una escala de actitudes hemos obtenido en una mues-
tra una desviación típica de 6.86 y una fiabilidad de s = .78 ¿qué fiabilidad po-
demos esperar en otra muestra cuya desviación típica vemos que es 7.28?
6.682
(1 – .78)
Aplicando la fórmula [24]: fiabilidad esperada = 1 – —————— = .8147
7.282
De hecho la fiabilidad calculada en la nueva muestra (ejemplo real) es de
8.15, aunque no siempre obtenemos unas estimaciones tan ajustadas.
13. RESUMEN: CONCEPTO BÁSICO DE LA FIABILIDAD EN CUANTO CONSISTENCIA INTERNA
En el cuadro puesto a continuación tenemos un resumen significativo de
lo que significa la fiabilidad en cuanto consistencia interna, cómo se interpre-
ta y en qué condiciones tiende a ser mayor.
LA FIABILIDAD DE LOS TETS Y ESCALAS
231
rnn = fiabilidad estimada en la nue-
va muestra
so y roo = desviación típica y fiabilidad ya
calculadas (observadas) en una
muestra
sn = desviación típica en la nueva
muestra (en la que deseamos
estimar la fiabilidad)
1. Cuando ponemos un test o una escala aun grupo de sujetos nos encontramos
con diferencias inter-individuales. Estas diferencias o diversidad en sus puntua-
ciones totales las cuantificamos mediante la desviación típica (s) o la varianza
(s2
).
2. Esta varianza (diferencias) se debe a las respuestas de los sujetos que pueden
ser de dos tipos (fijándonos en los casos extremos; hay grados intermedios):
coherentes (relacionadas) o incoherentes, por ejemplo:
respuestas respuestas
coherentes incoherentes
En mi casa me siento mal de acuerdo en desacuerdo
A veces me gustaría marcharme de casa de acuerdo de acuerdo](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-231-320.jpg)








![mínimo probable y un tanto por ciento máximo probable de votantes a ese
candidato: entre esos dos tantos por ciento se va a encontrar el tanto por
ciento definitivo cuando todos hayan votado. De los datos de una muestra ex-
trapolamos a la población, por eso se trata de estadística inferencial.
De manera análoga podemos pensar en distribuciones muestrales de
otros estadísticos como proporciones, medianas, coeficientes de correlación,
etc., y también en distribuciones muestrales de las diferencias entre propor-
ciones, medianas, coeficientes de correlación, etc., con aplicaciones semejan-
tes a las que vamos a ver con respecto a la media que son las de utilidad más
inmediata y frecuente.
3. EL ERROR TÍPICO DE LA MEDIA
Según el teorema del límite central, si de cualquier población se extraen
muestras aleatorias del mismo tamaño N, al aumentar el número de mues-
tras sus medias se distribuyen normalmente, con media m y una desviación tí-
pica, o error típico
Esta distribución muestral de las medias es independiente de la distribu-
ción de la población: aunque la distribución en la población no sea normal,
las medias de las muestras aleatorias extraídas de esa población sí tienden a
tener una distribución normal.
El error típico de la media (desviación típica de la distribución muestral
de las medias) podemos expresarlo de dos maneras:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
240
En la fórmula [1] la desviación típica
del numerador se supone calculada
dividiendo por N-1 la suma de cua-
drados (o la suma de las puntuacio-
nes diferenciales, X-
–
X, elevadas pre-
viamente al cuadrado).
En la fórmula [2] la desviación típica
se ha calculado dividiendo por N, co-
mo es normal hacerlo cuando se cal-
cula la desviación típica como dato
descriptivo de la muestra. Ambas fór-
mulas son equivalentes y dan el mis-
mo resultado; la única diferencia está
en cuándo se ha restado 1 a N.
En principio suponemos que la desviación típica de la muestra la hemos cal-
culado dividiendo por N, como dato descriptivo de la dispersión en la muestra,
por eso al calcular el error típico de la media utilizaremos la fórmula [2].](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-240-320.jpg)

![a una población cuya media conocemos o establecemos como hipótesis. La
media también puede ser una proporción (una proporción es la media cuan-
do los datos son unos y ceros). Es conveniente exponerlo aquí brevemente,
pero lo volveremos a encontrar al tratar del contraste de medias, pues allí ve-
remos un procedimiento más sencillo. Son procedimientos equivalentes.
Podemos añadir un tercer uso del error típico de la media, que es determi-
nar el número de sujetos que necesitamos en la muestra para extrapolar los
resultados a la población. Cuando a partir de los datos de una muestra nos in-
teresa extrapolar los resultados a la población (por ejemplo cuántos van a vo-
tar a un partido político en unas elecciones), lo hacemos con un margen de
error (en cuyo cálculo tenemos en cuenta el error típico y nuestro nivel de
confianza): si queremos un margen de error pequeño, necesitaremos más
sujetos… por eso en las fórmulas para determinar el número de sujetos de la
muestra entrará el error típico. Este punto lo veremos de manera más sucin-
ta, porque suele verse con más detalle en otro contexto más práctico, al tratar
de las muestras, tipos de muestras, número de sujetos necesario según distin-
tas finalidades, etc.
4.1. Establecer entre qué limites (intervalos de confianza) se en-
cuentra la media (m) de la población (establecer parámetros
poblacionales)
La media de una muestra (X
–
) es una estimación de la media de la pobla-
ción (m); pero decir que es una estimación quiere decir que está sujeta a
error. La media exacta de la población no la conocemos; pero sí podemos es-
timar entre qué límites extremos se encuentra, y esto a partir de la media de
una muestra y del error típico de la media.
El error típico de la media no es otra cosa que una estimación de la des-
viación típica de las medias (de muestras de la misma población), y se inter-
preta de la misma manera; así por ejemplo según la distribución normal, el
95% de las medias se encontrará entre -1.96s y + 1.96s; aquí s es propiamen-
te sx
-, el error típico de la media.
Si tenemos estos datos de una muestra: N = 30, X
–
= 62.8 y s = 7.9, ten-
dremos que (fórmula [2]):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
242
El error típico de la media (o desviación típica de las medias posibles) es
en este caso igual a 1.47, y según las probabilidades de la distribución normal
podremos afirmar que:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-242-320.jpg)
![Hay un 68% de probabilidades de que la media de la población se encuen-
tre entre la media de la muestra más menos un error típico:
entre (62.8 - 1.47) y (62.8 + 1.47) = entre 61.33 y 64.27.
Hay un 95% de probabilidades de que la media de la población se encuen-
tre entre la media de la muestra más menos 1.96 errores típicos:
entre [62.8 - (1.96 x 1.47)] y [62.8 + (1.96 x 1.47)] = entre 59.92 y 65.68.
Si deseamos mayor seguridad al establecer los límites probables entre los
que se encuentra la media de la población, podemos tomar como límite 2.57
errores típicos, porque sabemos que entre la media más menos 2.57 desvia-
ciones típicas se encuentra el 99% de los casos. En este caso:
El límite inferior de la media de la población sería [62.8 - (2.57 x 1.47)] = 59.02
El límite superior de la media de la población sería [62.8 + (2.57 x 1.47)] = 66.58
A estos límites, o valores extremos, superior e inferior, de la media en la
población se les denomina intervalos de confianza, porque eso es precisa-
mente lo que expresan: entre qué límites podemos situar la media de la po-
blación con un determinado grado de confianza o de seguridad (o de pro-
babilidades de no equivocarnos). Los intervalos de confianza suelen
denominarse en las encuestas de opinión márgenes de error.
Estos intervalos de confianza podemos establecerlos con diversos nive-
les de seguridad, que vendrán dados por el valor de z que escojamos, por lo
que podemos expresarlos así:
intervalos de confianza de la media =
La cantidad que sumamos y restamos a la media de la muestra podríamos
denominarla margen de error al estimar los límites probables de la media en
la población y que podemos expresar de esta manera:
Como ya hemos indicado estos límites o márgenes de error serán más ajus-
tados cuando el número de sujetos sea mayor. Es útil visualizar el efecto del ta-
maño de la muestra en los intervalos de confianza (tabla 1). Queremos saber,
por ejemplo, entre qué límites se encuentra la media de la población, estimada
ESTADÍSTICA INFERENCIAL: EL ERRORTÍPICO DE LA MEDIA
243](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-243-320.jpg)
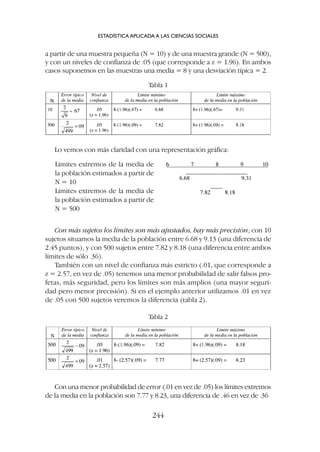
![Tanto X
–
como s son los valores calculados en una muestra. Naturalmente
el valor exacto de la media de la población (m) no lo conocemos: puede estar
en cualquier punto entre los valores extremos indicados. También puede es-
tar fuera de los límites indicados, pero esto va siendo más improbable cuan-
do establecemos unos intervalos de confianza más estrictos.
Es normal operar con un nivel de confianza del 95% (o, lo que es lo mis-
mo, con una probabilidad de error, al situar los límites extremos de la media,
de un 5%); en este caso z en la fórmula [3] será igual a 1.96; como se despren-
de de esta fórmula, a mayor valor de z (mayor seguridad) los límites serán
más extremos.
Cuando calculamos la media de una muestra en una variable de interés ¿Es
útil calcular además entre qué límites se encuentra la media de la población?
Con frecuencia nos bastará conocer la media de una muestra concreta co-
mo dato informativo, pero con frecuencia extrapolamos informalmente de
la muestra a la población. Siempre es útil relativizar este tipo de informa-
ción, y con mayor razón si de hecho (como es frecuente) estamos utilizando
la media de una muestra como estimación de la media de la población2
.
4.2. Establecer los intervalos de confianza de una proporción
El error típico de una proporción es un caso particular del error típico de
la media pero dado el uso frecuente de proporciones y porcentajes es útil ver-
lo por separado y con ejemplos ilustrativos.
Cuando los datos son dicotómicos (1 ó 0) la media p es la proporción de
sujetos que responden sí o que escogen la respuesta codificada con un 1. Si
de 200 sujetos 120 responden sí (ó 1) a una pregunta y 80 responden no (0),
la media p es igual a 120/200 = .60: el 60% de los sujetos (o una media del
60%) han respondido sí.
El error típico de una proporción es el mismo que el error típico de cual-
quier media, solo que en este caso la media es p, la varianza es pq [propor-
ción de unos por proporción de ceros] y la desviación típica es .
La fórmula del error típico de una proporción (sp) será por lo tanto:
2
Una de las recomendaciones de la American Psychological Association es calcular
siempre los intervalos de confianza (Wilkinson, Leland and Task Force on Statistical Infe-
rence APA Board of Scientific Affairs 1999; American Psychological Association, 2001).
ESTADÍSTICA INFERENCIAL: EL ERRORTÍPICO DE LA MEDIA
245](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-245-320.jpg)
![Ahora podemos hacernos esta pregunta: en esa muestra de 200 sujetos
han respondido sí 120 sujetos (una media de .60 o el 60%), pero ¿cuántos
responderán sí en la población representada por esa muestra? Ya podemos in-
tuir la importancia de esta pregunta si pensamos en los sondeos pre-electora-
les; lo que interesa realmente no es conocer cuántos sujetos de esa muestra
van a votar a un candidato, sino cuántos le votarán el día de las elecciones.
La proporción de votantes que dirán sí a ese candidato (o la media de vo-
tantes) en la población no la sabemos (habría que preguntar a todos y eso se
hará el día de las elecciones), pero sí podemos estimar entre qué límites má-
ximo y mínimo se encuentra esa proporción con un determinado nivel de
confianza (o seguridad de acertar en la predicción); es decir, podemos esta-
blecer los márgenes de error.
Para responder a esta pregunta calculamos los intervalos de confianza de
la media (p = .60) con un nivel de confianza de .05 (un 5% de probabilidades
de equivocarnos) que equivale a z = 1.96.
La proporción de los que dirán sí a juzgar por los datos de esa muestra es-
tará entre .60 menos 1.96 errores típicos y .60 más 1.96 errores típicos:
Límite mínimo: .60 – (1.96)(.0346) = .60 – .0678 = .5322 (el 53%)
Límite máximo: .60 + (1.96)(.0346) = .60 + .0678 = .6678 (el 67%)
El margen de error en nuestra predicción es .0678 (casi un 7% redonde-
ando). En la muestra encuestada ha respondido sí el 60%, pero en la pobla-
ción representada por esa muestra esperamos que responda sí entre un 53%
y un 67%.
El ejemplo de los sondeos pre-electorales pone de relieve la importancia
de calcular los intervalos de confianza de una proporción (y es lo que se ha-
ce y comunica cuando se publican estas encuestas), pero estos intervalos de
confianza son informativos casi en cualquier situación. Cuando se hacen son-
deos de opinión en grupos diversos (alumnos, padres de alumnos, grupos
En el ejemplo anterior tenemos que N = 200, p =120/200 = .60 y q =.40
(ó 1 - .60) por lo tanto el error típico de la proporción será:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
246
Intervalos de confianza de una proporción =
De manera análoga a lo que hemos visto en los intervalos de confianza de
la media en variables continuas (fórmulas [3] y [4]), los intervalos de confian-
za de una proporción p serán:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-246-320.jpg)


![Salta a la vista que la media de la población de referencia (= 15) es mayor
que el límite superior de la media de la población representada por esa mues-
tra (=14.35).
2º De hecho el procedimiento utilizado habitualmente para comprobar si
la media de una muestra difiere significativamente de la media de una pobla-
ción suele ser otro que nos permite llegar a las mismas conclusiones. Nos bas-
ta calcular una puntuación típica (z), que nos dirá en cuántos errores típicos
se aparta nuestra media de la media de la población. El procedimiento y la
fórmula apropiada están puestos y explicados como un caso más del contras-
te de medias.
4.4. Calcular el tamaño N de la muestra para extrapolar los resultados
a la población
No es éste el lugar apropiado para tratar con cierta extensión sobre el ta-
maño necesario de la muestra, pero sí es útil, tratando del error típico de la
media o de una proporción, ver y entender en este contexto la relación entre
la magnitud de los intervalos de confianza de la media y el número necesario
de sujetos en la muestra para extrapolar los resultados a la población con un
determinado margen de error.
De manera análoga a lo que hemos visto en [4] y en [6] el margen de error
cuando la proporción encontrada en una muestra la extrapolamos a la pobla-
ción es:
3. Nuestra conclusión es clara: nuestra muestra con media de 12.6 no per-
tenece a una población hipotética cuya media fuera 15 porque el límite
máximo de la población de nuestra media es 14.35 y no llega a 15, lue-
go nuestra muestra pertenece a otra población con otra media, cuyo
límite inferior no es 15.
Podemos visualizar el resultado con un sencillo gráfico:
Si en [7] despejamos N (el tamaño de la muestra) tendremos:
ESTADÍSTICA INFERENCIAL: EL ERRORTÍPICO DE LA MEDIA
249](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-249-320.jpg)
![En [8] conocemos todos los valores que nos interesan para calcular N
z Este valor corresponde al nivel de confianza y lo establecemos nos-
otros; habitualmente utilizaremos un nivel de confianza del .05 y z =
1.96 (ó z = 2.57 si nuestro nivel de confianza es de .01)
pq Es la varianza de la población, no la varianza de la muestra. Esta va-
rianza no la conocemos, pero como a mayor varianza en la población
hará falta una muestra mayor, nos situamos en la situación en que la
varianza es la máxima posible; en este caso p = q = .50, y pq = .25,
que es un valor constante.
e Es el margen de error que estamos dispuestos a aceptar y también lo
establece el investigador. Si por ejemplo estamos dispuestos a aceptar
un margen de error del 5%, esto quiere decir que si en la muestra en-
cuestada en esta caso responde sí el 35%, en la población esperamos
que responda sí entre el 30% y el 40%. Éste 5% lo expresaremos en
forma de proporción (o tanto por uno): .05
Vemos de nuevo que si queremos un margen de error pequeño (e, el de-
nominador en 8) necesitaremos una muestra mayor.
Podemos ver la aplicación de esta fórmula [8] con un ejemplo. Vamos a
hacer una encuesta para extrapolar los resultados a una población mayor
(muy grande, de tamaño indefinido).
El margen de error que estamos dispuestos a aceptar es del 5% (e = .05),
de manera que si nos responden sí el 50% de la muestra ya sabemos que en la
población el sí estará entre el 45% y el 55%
El nivel de confianza es del .05, que corresponde a z = 1.96
(1.96)(.25)
Necesitaremos una muestra de este tamaño: N = ––––––––– = 384 sujetos
.052
Si el margen de error máximo que nos interesa es del 3% (e = .03), la
muestra necesaria sería de 1067 sujetos.
Hacemos algunas observaciones ya que el exponer y justificar brevemente
estas fórmulas tiene un valor complementario para entender mejor el con-
cepto y utilidad del error típico, pero no tratamos aquí de manera expresa so-
bre el tamaño de la muestra, tipos de muestreos y cómo hacerlos, etc.3
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
250
3
Puede verse más información en la bibliografía mencionada y en otras muchas publi-
caciones; sobre el tamaño de la muestra necesario también con otras finalidades (cons-
truir una escala de actitudes, hacer un análisis factorial, etc.) puede verse Morales (2007b).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-250-320.jpg)








![4. CÓMO COMPROBAMOS SI NUESTRA DIFERENCIA PERTENECE A LA POBLACIÓN DE DIFERENCIAS
CUYA DIFERENCIA MEDIA ES CERO
4.1. Modelo y fórmula básica
Hacemos esta comprobación verificando en cuántos errores típicos (des-
viaciones típicas) se aparta nuestra diferencia de la diferencia media de cero.
Si nuestra diferencia se aparta mucho (1.96 errores típicos si seguimos el
criterio habitual) de la diferencia media de cero:
1. Podremos deducir que esa diferencia es improbable si las dos medias
proceden de la misma población.
2. Y afirmaremos por lo tanto que las muestras proceden de poblaciones
distintas con distinta media. Difieren más de lo que consideramos nor-
mal cuando no hay más diferencias que las puramente aleatorias.
¿Cómo sabemos que la diferencia está dentro de lo probable? (probable
en la hipótesis de que ambas muestras procedan de la misma población):
Verificando en cuántos errores típicos se aparta nuestra diferencia de la di-
ferencia media de cero.
Para esto nos basta calcular la puntuación típica de esa diferencia (z, t de
Student) que nos indicará si la diferencia es probable (p .05) o improbable
(p.05) (en este caso el nivel de confianza, o probabilidad de error al afir-
mar la diferencia, es de a =.05).
Esta puntuación típica, expresada en términos no convencionales, será:
La fórmula, expresada en símbolos convencionales es:
En esta fórmula [1]:
El numerador equivale de hecho a la diferencia entre dos medias
(entre las medias de dos diferencias); restamos una diferencia en-
tre dos medias de una diferencia media de cero.
EL CONTRASTE DE MEDIAS
259](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-259-320.jpg)



![Si la probabilidad de que ocurra la diferencia es grande, afirmamos que
ambas muestras proceden de la misma población, y que la diferencia está
dentro de lo aleatorio (se explica por el error muestral, por la variabilidad
normal que hay en cualquier conjunto de datos) y lo solemos expresar di-
ciendo que aceptamos la Hipótesis Nula, aunque con más propiedad habría
que decir que no rechazamos la Hipótesis Nula (propiamente nunca demos-
tramos que la Hipótesis Nula es verdadera; simplemente no demostramos
que es falsa).
Si esta probabilidad es pequeña (menos del 5% o p .05 si señalamos ese ni-
vel de confianza o a = .05) rechazamos que las muestras procedan de la misma
población con idéntica media (no aceptamos la Hipótesis Nula) y podremos
afirmar que las dos muestras proceden de poblaciones distintas con distinta me-
dia (y decimos entonces que la diferencia es estadísticamente significativa).
Una cuestión distinta es identificar automáticamente diferencia estadísti-
camente significativa con hipótesis de investigación demostrada (si la dife-
rencia es mayor de lo normal, es que este método es mejor que el otro, etc.);
del hecho de la diferencia no se deduce sin más que la causa o explicación
de la diferencia sea la propuesta como hipótesis por el investigador; simple-
mente afirmamos la diferencia.
Así, si hacemos un contraste de medias con un nivel de confianza de
a = .05:
Si la diferencia es probable (p .05)
[probable en el caso de que las
muestras procedan de la misma
población]
Si la diferencia es improbable
(p .05) [improbable en el caso de que
las muestras procedan de la misma
población]
Aceptamos (no rechazamos) la
Hipótesis Nula; o lo que es lo mismo:
Rechazamos (no aceptamos) la
Hipótesis Nula y aceptamos la Hipótesis
Alterna, o lo que es lo mismo:
Afirmamos que las muestras pertenecen
a la misma población (m1 = m2)
Afirmamos que las muestras proceden
de poblaciones distintas (m1 m2)
Afirmamos que la diferencia no es
estadísticamente significativa.
Afirmamos que la diferencia sí es
estadísticamente significativa (es muy
improbable que las muestras
pertenezcan a la misma población).
EL CONTRASTE DE MEDIAS
263](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-263-320.jpg)

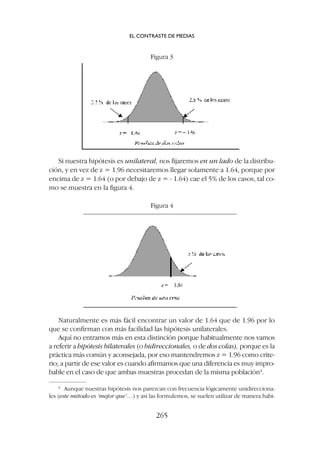







![Estamos suponiendo que habitualmente calculamos la s de la muestra di-
vidiendo por N-1; si la hubiéramos calculado dividiendo por N, en los deno-
minadores tendríamos N y no N-1
10
.
4.7. Fórmulas del contraste de medias9
La fórmula básica es la fórmula [1] ya vista antes: una diferencia entre dos
medias dividida por el error típico de las diferencias:
ejemplo y entre otros, Hancock y Klockars, 1996). Una crítica bien razonada a los ajustes de
Bonferroni puede verse en Perneger (1998): this paper advances the view, widely held by
epidemiologists, that Bonferroni adjustments are, at best, unnecessary and, at worst, de-
leterious to sound statistical inference… The main weakness is that the interpretation of
a finding depends on the number of other tests performed …The likelihood of type II
errors is also increased, so that truly important differences are deemed non-significant…
Bonferroni adjustments imply that a given comparison will be interpreted differently ac-
cording to how many other tests were performed. También se proponen estos niveles de
confianza más estrictos cuando tenemos muchos coeficientes de correlación, pero la críti-
ca que puede hacerse es la misma
9
Podemos llevar a cabo un contraste de medias, sin necesidad de conocer las fórmu-
las, con programas como EXCEL o SPSS, y también con los programas que podemos en-
contrar en Internet (anexo 4); sin embargo debemos entender qué estamos haciendo.
10
En los programas estadísticos (como el SPSS) lo normal es utilizar la desviación típi-
ca de la población (dividiendo por N-1; con muestras relativamente grandes la diferencia
entre dividir por N o N-1 puede ser irrelevante).
Nos falta conocer el valor del denominador ( es solamente un sím-
bolo).
La fórmula general del denominador de la fórmula [1] (error típico de la
diferencia entre medias) es:
Como el error típico de la media es siempre la fórmula [2]
se puede expresar así:
EL CONTRASTE DE MEDIAS
273](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-273-320.jpg)
![Es útil conocer de dónde viene esta fórmula [2] (o [3]; es la misma). La va-
rianza de un compuesto, por ejemplo la varianza de la suma de los tests 1 y 2,
no es igual a la varianza del test 1 más la varianza del test 2, sino ésta otra:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
274
Podemos ver el parecido de esta expresión con el cuadrado de un bino-
mio (de eso se trata):
Si no se trata de un compuesto (o suma), sino de una diferencia, sabemos
que (a-b)2
=a2
+b2
-2ab. Éste es nuestro caso: no se trata del cuadrado de una
suma (a+b), sino del cuadrado de una diferencia (a-b), de ahí el signo menos
en el denominador de las fórmulas [2] y [3].
Lo que tenemos en esta fórmula (del error típico o desviación típica de las
diferencias entre medias de muestras de la misma población) es la suma de
los dos errores típicos de las medias menos dos veces su covarianza (recorde-
mos que r12s1s2 es la fórmula de la covarianza).
Este denominador [2] no lo utilizaremos habitualmente. Si se trata de
muestras independientes (sujetos distintos) el valor de la correlación que
aparece en la fórmula es cero, con lo que el denominador queda muy simpli-
ficado. El denominador [2] es válido cuando de trata de comparar medias de
muestras relacionadas (los mismos sujetos medidos antes y después en el
caso más frecuente), pero aun en este caso tenemos un procedimiento alter-
nativo más sencillo en el que no tenemos que calcular la correlación, como
veremos más adelante.
En el apartado siguiente están todas las fórmulas necesarias para el con-
traste de medias. Aunque habitualmente utilicemos programas informáticos
no siempre es así y en cualquier caso las fórmulas nos ayudan a entender lo
que estamos haciendo.
4.7.1. Diferencia entre la media de una muestra y la media de una
población
En este caso conocemos todos los datos de la muestra (número de suje-
tos, media y desviación); de la población conocemos solamente la media (que
puede ser una media hipotética, o deducida de otros estudios, etc.).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-274-320.jpg)

![De esta manera la primera parte del denominador se convierte en una
constante que basta calcular una sola vez.
3º Diferencia entre dos medias de muestras independientes (grandes o
pequeñas) y de idéntico tamaño
Cuando las muestras son de idéntico tamaño (N = N) las fórmulas anterio-
res quedan muy simplificadas (se trata de la fórmula [5] simplificada porque
los denominadores son idénticos):
La interpretación, cuando se trata de muestras grandes, se hace consultan-
do las tablas de la distribución normal (o en programas de Internet, anexo 4),
con grados de libertad igual a N1+N2-2. Como por lo general los niveles de
confianza que utilizamos son .05, .01 y .001, no necesitamos acudir a las ta-
blas, pues ya conocemos los valores de referencia para muestras grandes:
Los valores de z utilizados habitualmente con muestras grandes son:
Si z es mayor que 1.96 2.57 3.30
La probabilidad de que la diferencia sea
aleatoria es inferior a .05 .01 .001
2º Muestras pequeñas y de distinto tamaño
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
276
Esta fórmula puede utili-
zarse con muestras de
cualquier tamaño;
La interpretación se hace
consultando las tablas de la
t de Student, con grados
de libertad igual a N1+N2- 2
Cuando se van a hacer muchos contrastes de medias con el mismo par de
muestras, y por lo tanto los valores de N van a ser constantes, es más cómo-
do y rápido transformar la fórmula [6] en ésta otra [7]:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-276-320.jpg)
![También se puede utilizar el denominador puesto en la fórmula [2] o [3],
y así aparece en muchos textos, pero el utilizar la fórmula [9] es un método
más claro y sencillo.
Esta fórmula es válida tanto para muestras grandes como pequeñas; con
muestras pequeñas se consultan las tablas de la t de Student.
4.7.3. Diferencia entre medias de muestras relacionadas (compro-
bación de un cambio)
Tenemos muestras relacionadas cuando los sujetos son los mismos, y de
cada sujeto tenemos dos datos en la misma variable; son dos muestras de da-
tos procedentes de los mismos sujetos. En la situación más frecuentemente
estos datos los obtenemos en la misma variable antes y después de alguna ex-
periencia o proceso y se desea comprobar si ha habido un cambio11
.
Cuando se dispone de una calculadora estadística (con la media y la des-
viación típica programadas), lo más sencillo es calcular para cada sujeto su
puntuación diferencial (diferencia entre las dos puntuaciones, entre antes y
después) y aplicar esta fórmula:
El término muestras relacionadas (y las fórmulas correspondientes) tam-
bién se aplica cuando tenemos sujetos distintos pero igualados en variables
importantes, tal como se estudia en el contexto de los diseños experimenta-
les; en estos caso tenemos una muestra de parejas de sujetos.
En este caso N1 = N2 = N, que es el número de
sujetos en cada grupo; los grados de libertad
son como en los casos anteriores: N1+ N2 -2
(número total de sujetos, restando un sujeto a
cada grupo).
X
–
D = Media de las diferencias,
s2
D = Varianza de las diferencias,
N = número de sujetos o de pares de pun-
tuaciones; los grados de libertad son N-1.
EL CONTRASTE DE MEDIAS
277
11
Aunque si no hay un grupo de control o de contraste (término de comparación) es-
ta comprobación de un cambio puede ser cuestionable; conviene estudiar cuál debe ser el
diseño apropiado en estos casos. Otros métodos para verificar un cambio los tenemos en
el capítulo siguiente, la prueba de los signos (nº 8.2.3) y la prueba de McNemar (nº 10.2);
también tenemos la prueba no paramétrica de la T de Wilcoxon que no tratamos aquí.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-277-320.jpg)
![Podemos observar la semejanza de esta fórmula [9] con la fórmula [4]. En
realidad se trata del mismo planteamiento: comparar la media en cambio de
una muestra, con la media m = 0 de una población que no hubiera cambiado
nada.
Los grados de libertad son N-1 o número de pares de observaciones me-
nos uno (es decir, N = número de sujetos, pues cada uno tiene dos puntua-
ciones). Con muestras grandes se consultan las tablas de la distribución nor-
mal, y con muestras pequeñas las de la t de Student.
Podemos ver la aplicación de esta fórmula [9] con un ejemplo ficticio.
Cuatro sujetos han respondido a una pregunta (respuestas de 1 a 6) antes y
después de una experiencia.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
278
Antes Después Diferencia
2 4 4-2 = 2
3 3 3-3 = 0
4 5 5-4 = 1
5 6 6-5 = 1
Media 3.5 4.5 1.0
s 1.118 1.118 .707
Utilizando la media y desvia-
ción en cambio (después me-
nos antes) y aplicando la fór-
mula 12, tendremos:
La correlación entre antes y después es r = .80; si utilizamos el denomina-
dor de la fórmula [3] tendríamos:
El resultado es el mismo, pero es claro que en este caso (muestras rela-
cionadas) es preferible utilizar la fórmula [9].
4.8. Variables que influyen en el valor de t (o z)
Los valores máximos y mínimos que solemos encontrar en las puntuacio-
nes típicas (y en la t de Student que es una puntuación típica, la puntuación
típica de una diferencia) suelen oscilar (pueden ser mucho mayores) entre –3
y +3; lo que queda fuera de ±1.96 lo consideramos ya atípico, poco proba-
ble (sólo en el 5% de los casos se supera por azar un valor de ±1.96).
Sin embargo al calcular la t de Student nos encontramos con frecuencia con
valores muy altos, sobre todo cuando el número de sujetos es muy grande.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-278-320.jpg)
![El cociente aumentará si aumenta el numerador (si la diferencia es gran-
de), pero también aumentará, aunque el numerador sea pequeño (diferencia
cuantitativamente pequeña) si disminuye el denominador…
¿Qué factores influyen en que disminuya el denominador y que por lo tan-
to el cociente sea mayor?
En el denominador tenemos otro quebrado:
a) El cociente disminuirá si disminuye el numerador (la varianza de los
grupos).
A mayor homogeneidad en los grupos (menor varianza), la diferencia se-
rá significativa con más probabilidad. Esto es además conceptualmente razo-
nable: no es lo mismo una diferencia determinada entre dos grupos muy he-
terogéneos (mucha diversidad dentro de cada grupo) que entre dos grupos
muy uniformes… Una diferencia entre las medias de dos grupos muy hetero-
géneos puede variar si tomamos otras dos muestras igualmente muy hetero-
géneas, pero si la diferencia procede de dos muestras con sujetos muy pare-
cidos, con pequeñas diferencias entre sí, hay más seguridad en que se
mantenga la diferencia entre otros pares semejantes de grupos.
b) El cociente disminuirá si aumenta el denominador del denominador,
que es el número de sujetos. Con muestras grandes es más fácil encontrar di-
ferencias significativas.
¿Qué podemos decir sobre el hecho de que aumentando el número de suje-
tos encontramos fácilmente diferencias estadísticamente significativas? ¿Que
con un número grande de sujetos podemos demostrar casi lo que queramos…?
1º En parte sí; con números grandes encontramos con facilidad diferen-
cias significativas. Pero esto no tiene que sorprendernos porque de he-
cho hay muchas diferencias entre grupos que se detectan con más faci-
lidad cuando los grupos son muy numerosos. En la vida real la
Hipótesis Nula (m1 = m2) suele ser falsa y cuando no la rechazamos sue-
le ser por falta de sujetos.
¿Qué factores influyen en que encontremos una t de Student grande o
simplemente estadísticamente significativa?
Este punto es sencillo e importante porque nos facilita la interpretación
de nuestros resultados e incluso proponer nuevas hipótesis…
Observamos la fórmula general [5] (para
muestras grandes e independientes y de
tamaño distinto):
EL CONTRASTE DE MEDIAS
279](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-279-320.jpg)


![La probabilidad de que la diferencia sea aleatoria es casi del 1 por mil.
6. ANÁLISIS COMPLEMENTARIOS AL CONTRASTE DE MEDIAS: CÓMO CUANTIFICAR LA MAGNITUD
DE LA DIFERENCIA
6.1. Finalidad del tamaño del efecto
Para obviar las limitaciones del mero contraste de medias, se ha ido impo-
niendo el cálculo del denominado tamaño del efecto (effect size en inglés).
Aunque los resultados los expresemos frecuentemente en porcentajes
(%), los cálculos se hacen con proporciones. El procedimiento es análogo al
del contraste de medias: dividimos una diferencia entre proporciones por el
error típico de la diferencia entre dos proporciones, que está en el denomi-
nador de la fórmula [10]. En rigor lo que tenemos en el numerador no es la
diferencia entre dos proporciones, sino la diferencia entre una diferencia (la
nuestra) y una diferencia de cero.
En la fórmula [10] tenemos en el denominador el error típico de la dife-
rencia entre dos proporciones13
.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
282
13
En muchos textos la fórmula aducida para el contraste de proporciones indepen-
dientes es la misma fórmula vista para el contraste de medias (fórmula [5]), con la salve-
dad de que se utiliza pq para expresar las varianzas de los dos grupos (p1q1 y p2q2 en vez de
esta fórmula es correcta cuando p y q tienen valores parecidos; cuando los va-
lores de p o q son muy extremos, y siempre en general, la fórmula preferible es la puesta
aquí (en Downie y Heath, 1971, puede verse una explicación más amplia); además es uti-
lizando esta fórmula cuando la equivalencia con el ji cuadrado (tablas 2x2) es exacta (z2
=
c2
). Este contraste de proporciones y procedimientos alternativos (ji cuadrado) puede
verse también en el capítulo IX.
Y aplicando la fórmula [10] a nuestros datos:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-282-320.jpg)


![A este coeficiente de correlación también se le denomina genéricamente
tamaño del efecto, aunque la expresión tamaño del efecto se suele reservar
para la diferencia tipificada que veremos después. Algunos autores, para dis-
tinguir ambos cálculos, denominan a esta correlación magnitud del efecto.
La finalidad y utilidad de este coeficiente de correlación es clara:
1º Es un dato sobre la magnitud y no sobre si una diferencia es simple-
mente estadísticamente significativa o no (si es o no es extrapolable a
la población el hecho de una diferencia distinta de cero).
2º Dos valores de t obtenidos en pares de muestras de tamaño distinto, o
en variables distintas, no son fácilmente comparables entre sí; en cam-
bio esta conversión nos traduce el resultado (una diferencia) a térmi-
nos comparables y más fácilmente interpretables. Los juicios sobre si
una diferencia es o no es relevante, de importancia práctica, etc., no
dependen solamente de que sea estadísticamente significativa (a veces
nos puede bastar con eso), sino también de que sea grande o peque-
Si calculamos la correlación (que denominamos biserial-puntual porque
una de las dos variables es dicotómica) tenemos que r = .585
Ahora calculamos el mismo coeficiente a partir del valor de t, fórmula [11]:
; hemos llegado al mismo resultado
Un mismo valor de t va a equivaler a coeficientes de correlación más bajos
según aumente el número de sujetos (aumentará el denominador y disminui-
rá el cociente). Podemos verlo en este ejemplo (tabla 1) en que se mantiene
constante el valor de t (en todos los casos p .01) y se van variando los gra-
dos de libertad (número de sujetos).
N1 N2 gl t rbp r
20 20 38 3.60 .50 .25
50 50 98 3.60 .34 .12
100 100 198 3.60 .25 .06
500 500 998 3.60 .11 .01
Tabla 1
EL CONTRASTE DE MEDIAS
285](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-285-320.jpg)
![Los símbolos para expresar el tamaño del efecto varían según las fórmulas
utilizadas para calcular la desviación típica del denominador; en la fórmula [12]
utilizamos el símbolo d porque corresponde a una de las fórmulas más utiliza-
das (de Cohen). Con frecuencia se utiliza d como símbolo genérico del tamaño
del efecto, pero hay otros símbolos que iremos viendo (como g y D) y que co-
rresponden a otras fórmulas; a veces se utiliza ES (del inglés Effect Size).
Aunque la desviación típica del denominador se puede calcular de diver-
sas maneras (a partir de las desviaciones típicas que ya conocemos en las
muestras) es en todo caso una estimación de la desviación típica de la pobla-
ción común a ambos grupos. Lo que es importante ahora es captar que el ta-
maño del efecto es una diferencia tipificada: una diferencia entre dos me-
dias dividida por una desviación típica. Viene a ser lo mismo que una
puntuación típica (z) (como podemos ver por la fórmula [12]), por lo que su
interpretación es sencilla y muy útil.
Antes de ver las fórmulas específicas de la desviación típica del denomina-
dor, es de especial interés entender las interpretaciones y usos del tamaño
del efecto, que se derivan del hecho de que se puede interpretar como una
ña…; incluso una diferencia no estadísticamente significativa puede ser
importante en una situación dada si es grande.
Cuando nos planteamos un contraste de medias podemos plantearnos co-
mo análisis alternativo el simple cálculo de la correlación entre la pertenencia
a un grupo u otro (1 ó 0) y la variable dependiente; por lo que respecta a re-
chazar o no la Hipótesis Nula, las conclusiones van a ser las mismas.
6.2.2. Tamaño del efecto (diferencia tipificada)
6.2.2.1. Concepto y fórmula general
El cálculo más frecuente para cuantificar la diferencia entre dos medias y
apreciar mejor su magnitud lo tenemos expresado por la fórmula general (ad-
mite variantes que veremos después)15
:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
286
15
Una presentación completa del tamaño del efecto en Coe (2000) (en Internet); tam-
bién se encuentra ampliado en Morales (2007c, El tamaño del efecto (effect size): análi-
sis complementarios al contraste de medias).
Tamaño del efecto (muestras independientes): [12]](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-286-320.jpg)


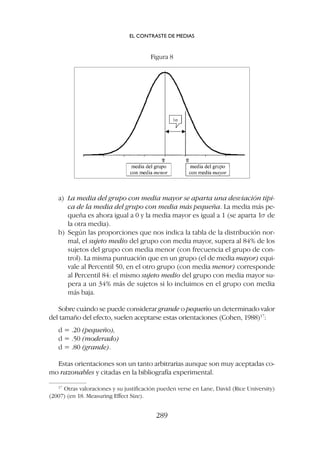




![Si por ejemplo estamos interesados en detectar diferencias grandes (d =
.80) con un nivel de confianza de a = .05 (5% de probabilidades de no encon-
trarlas si las hay), nos bastan grupos de 25 sujetos; si nos interesa encontrar
diferencias aunque sean pequeñas (como d = .30) nos harán falta muestras
mucho mayores (de unos 174 sujetos). Naturalmente de hecho podemos de-
tectar diferencias de estas magnitudes con muestras más pequeñas, pero tam-
bién nos exponemos a no verlas por falta de sujetos.
6.2.2.3. Fórmulas del tamaño del efecto: desviación típica del denominador
Vamos a distinguir cuatro posibilidades
1º Diferencia entre las medias de dos muestras independientes, cuando
no se trata de un diseño experimental (no hay un grupo de control
propiamente dicho).
2º Diferencia entre las medias de dos muestras relacionadas (diferencia
entre el pre-test y el post-test de la misma muestra).
3º Diferencia entre las medias de un grupo experimental y otro de control
(diseño experimental).
4º Diferencia entre las medias de un grupo experimental y otro de control
cuando los dos han tenido pre y post-test.
1º Dos muestras independientes
Éste es el caso posiblemente más frecuente. Tenemos dos maneras muy
parecidas de calcular la desviación típica combinada, la de Cohen (1977,
1988) y la de Hedges y Olkin (1985).
En la fórmula del tamaño del efecto de Cohen (símbolo d) se utilizan las
desviaciones típicas de las muestras, dividiendo por N (aquí las simbolizamos
como sn).
En la fórmula del tamaño del efecto de Hedges (símbolo g) se utilizan las
desviaciones típicas de la población, dividiendo por N-1 (aquí las simboliza-
mos como sn-1)
23
.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
294
23
El símbolo g lo pone Hedges en homenaje a Gene Glass, autor importante en el
campo del meta-análisis.
Cohen: d = donde [13]
Las desviaciones típicas de la fórmula [13] (Cohen) se calculan divi-
diendo por N (desviación típica de las muestras)](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-294-320.jpg)
![Las desviaciones típicas de la fórmula [14] (Hedges) se calculan divi-
diendo por N-1 (estimación de la desviación típica de las poblaciones)
Estas desviaciones típicas del denominador del tamaño del efecto no son
otra cosa que una combinación de las desviaciones típicas de las dos mues-
tras; por eso suelen denominarse desviación típica combinada (en inglés
pooled standard deviation). Podemos verlo fácilmente (en la fórmula de Co-
hen se ve con más facilidad): utilizamos ahora la varianza en vez de la desvia-
ción típica para eliminar la raíz cuadrada:
EL CONTRASTE DE MEDIAS
295
Hedges: g= donde [14]
Sabemos que s2
= de donde
scombinada [15]
Para combinar dos desviaciones típicas sumamos los dos numeradores y
los dos denominadores, que es lo que tenemos en las fórmulas anteriores (en
el caso de la g de Hedges se utiliza N-1 en vez de N, como es usual cuando se
trata de la estimación de la desviación típica de la población).
Cuando N = N (muestras de idéntico tamaño) en ambos casos (fórmulas
[13] y [14]) la desviación típica combinada es igual a la raíz cuadrada de la me-
dia de las varianzas:
Podemos ver la diferencia entre las dos fórmulas en un ejemplo concreto
(ficticio, tabla 3). Tenemos dos grupos (muestra A y muestra B) de cuatro su-
jetos cada una. Calculamos en cada muestra la media y las dos desviaciones tí-
picas; para diferenciarlas utilizamos los subíndices n (dividimos por N) y n-1
(dividimos por N-1).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-295-320.jpg)
![En este caso la diferencia no es estadísticamente significativa (t =1.987,
p = .094) pero el tamaño del efecto, calculado con cualquiera de las dos
fórmulas, puede considerarse como grande; esto no es inusual en muestras
pequeñas.
No podemos afirmar que ambas muestras procedan de poblaciones distin-
tas (no afirmamos una diferencia distinta de cero en la poblaciones) , pero
tampoco debemos ignorar la diferencia entre estos dos grupos de sujetos
concretos.
Vamos a calcular los dos tamaños del efecto (Cohen y Hedges):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
296
Muestra A Muestra B
16 18
12 14
14 16
14 18
Media 14 16.5
sn 1.414 1.658
sn-1 1.633 1.915
Tabla 3
Desviación típica combinada tamaño del efecto
Cohen: s = d =
Hedges: s = g =
Es natural que el tamaño del efecto sea mayor con la fórmula de Cohen
porque el denominador es menor (las desviaciones típicas de las muestras
son menores que las desviaciones típicas estimadas en la población).
Como en este ejemplo se trata de muestras de idéntico tamaño, podemos
utilizar la fórmula [15] para calcular la desviación típica combinada:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-296-320.jpg)
![Lo habitual es combinar la desviación típica de dos grupos, pero también
pueden ser más de dos grupos24
.
Podemos utilizar cualquiera de las dos fórmulas (Cohen y Hedges); posi-
blemente la de uso más frecuente es la de Cohen [13], que se puede utilizar
rutinariamente.
Ya hemos visto (fórmulas [16] y [17]) que de una desviación típica pode-
mos pasar a la otra (de la desviación típica de la muestra sn a la de la pobla-
ción sn-1 y viceversa); de manera análoga podemos pasar de un tamaño del
efecto al otro (de d a g y de g a d). Ambas fórmulas del tamaño del efecto se
relacionan de esta manera (Rosenthal, 1994):
Cohen: s =
Hedges: s =
De cualquiera de estas dos fórmulas de la desviación típica combinada
([13] y [14]) podemos pasar a la otra:
sCohen = sHedges [16] sHedges =
[17]
sCohen = sHedges=
Con los datos del ejemplo anterior:
EL CONTRASTE DE MEDIAS
297
24
Si en el mismo planteamiento tenemos más de dos grupos, como sucede en el aná-
lisis de varianza, podemos calcular la magnitud del efecto (o diferencia tipificada) entre
cualesquiera dos grupos utilizando en el denominador la desviación típica combinada de
todos ellos. En el análisis de varianza para muestras independientes los cuadrados me-
dios dentro de los grupos (el denominador de la razón F) es precisamente la combinación
de las varianzas de los diversos grupos; esto se ve, naturalmente, al tratar del análisis de va-
rianza, pero no sobra indicarlo aquí](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-297-320.jpg)
![También es frecuente utilizar en el denominador la desviación típica com-
binada de antes y después; en cualquier caso conviene indicar qué desviación
típica se ha utilizado.
3º Diferencia entre las medias de un grupo experimental y otro de control
(diseño experimental) sin pre-test
La fórmula habitual (y con D, delta mayúscula, como símbolo) es la pro-
puesta por Glass, McGaw y Smith (1981), en la que se utiliza la desviación tí-
pica del grupo de control (dividiendo por N -1):
Las fórmulas [18] y [19] son semejantes a las fórmulas [16] y [17], substi-
tuyendo el valor de la desviación típica combinada por el tamaño del efecto.
2º Dos muestras relacionadas (diferencia entre el pre-test y el post-test de la
misma muestra)
Cuando se trata de muestras relacionadas, se utiliza en el denominador
la desviación típica del post-test; en estos casos se verifica la magnitud del
cambio:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
298
[18]
[20]
[21]
[19]
a) La alternativa a utilizar en el denominador la desviación típica del gru-
po de control, es la desviación típica combinada de los dos o más
grupos (fórmulas [12] o [13]); ésta es también una práctica muy co-
mún y autorizada.
b) El utilizar la desviación típica del grupo de control es más recomenda-
ble cuando hay varios grupos experimentales con desviaciones típicas
muy distintas, o cuando el grupo de control es muy grande.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-298-320.jpg)
![4º Grupos experimental y de control cuando los dos han tenido pre y
post-test
Cuando tenemos dos grupos, experimental y de control, y los dos con pre
y post-test, hay varios procedimientos25
pero es aceptable utilizar la fórmula
[13] o [14] con los datos del post-test, sobre todo si no hay diferencias impor-
tantes en el pre-test.
6.3. Transformaciones de unos valores en otros
Los valores de la t de Student, coeficiente de correlación (r) y diferencia ti-
pificada (d o g) están relacionados entre sí, de manera que a partir de cual-
quiera de ellos podemos pasar a los otros. Estas transformaciones pueden ser
muy útiles.
Ya hemos visto antes cómo calcular el coeficiente de correlación a partir
de la t de Student (fórmula [11]), y cómo calcular el tamaño del efecto de Co-
hen (d) a partir del tamaño del efecto de Hedges (g) (y viceversa, fórmulas
[16] y [17]).
Cuando se ha calculado previamente la t de Student se puede calcular di-
rectamente el tamaño del efecto (d ó g), de la misma manera que del tama-
ño del efecto podemos pasar a la t de Student:
[22] [23]
[24] [25]
Si se trata del tamaño del efecto g de Hedges (14], para calcularlo a partir
de la t de Student podemos distinguir cuando se trata de muestras de tamaño
idéntico o desigual26
:
con muestras de idéntico tamaño con muestras de tamaño desigual
También podemos pasar de la magnitud del efecto a un coeficiente de
correlación.
EL CONTRASTE DE MEDIAS
299
25
Expuestos y discutidos en Glass, McGaw y Smith (1981).
26
Fórmulas tomadas de Mahadevan (2000), pero es fácil encontrarlas en otros autores.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-299-320.jpg)
![Sobre estas conversiones de unos valores en otros:
a) Los resultados son los mismos solamente cuando el número de sujetos
en los dos grupos es idéntico; en este caso da lo mismo calcular el ta-
maño del efecto con las fórmula directas que calcularlos a partir de la t
de Student.
b) Cuando el número de sujetos es desigual, la fórmulas del tamaño del
efecto calculadas a partir de t dan sólo una aproximación, pero muy
cercana al valor exacto del tamaño del efecto cuando los grupos no son
muy distintos en tamaño, del orden del 40% en uno y el 60% en el otro
(Rosenthal, 1987).
Todas estas conversiones27
pueden ser útiles por estas razones:
a) A veces facilitan las operaciones; lo más cómodo puede ser calcular el
valor del tamaño del efecto a partir del valor de t (fórmula [21]), sobre
todo cuando los tamaños de las muestras son iguales o muy parecidos.
En la fórmula [27] p es igual a la proporción de sujetos que corresponde a
uno de los dos grupos (n1/(n1+n2)) y q es igual a 1-p o la proporción de suje-
tos en el otro grupo. Si los grupos son de idéntico tamaño tenemos que p =
q = .5 y 1/pq = 4, tal como aparece en la fórmula [26].
Si se trata de convertir el valor de g (tamaño del efecto de Hedges) en un
coeficiente de correlación, la fórmula propuesta es la [28] (Mahadevan, 2000):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
300
27
Estas y otras conversiones pueden encontrarse en diversos autores, por ejemplo en
Rosenthal, 1987, 1991, 1994; Wolf, 1986; Hunter y Schmidt, 1990, Kirk, 1996, y otros.
[28]
[29]
[26] [27]
También podemos calcular el valor de d (tamaño del efecto de Cohen) a
partir del coeficiente de correlación.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-300-320.jpg)





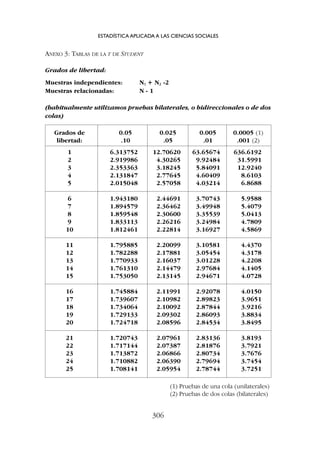












![Este análisis es muy útil pues es muy normal presentar a un grupo una se-
rie de preguntas con respuestas sí o no mutuamente excluyentes ¿Cuándo
predomina una de las dos respuestas más allá de lo probable por azar?
La pregunta que nos hacemos en nuestro ejemplo es si existe una diferen-
cia estadísticamente significativa (por encima de lo puramente aleatorio) en-
tre 40 y 20 (o entre dos proporciones o porcentajes obtenidos en la misma
muestra).
Tenemos dos maneras de llegar a una respuesta; una a través del ji cua-
drado, y otra utilizando la distribución binomial; con ambas llegamos al
mismo resultado. Aunque aparentemente haya muchas fórmulas, en reali-
dad todas son equivalentes y muy sencillas; posiblemente con la [2] o con la
[5] podemos resolver todas las situaciones en las que queramos hacer este
análisis.
El valor resultante de esta suma se consulta en las tablas de c2
según los
grados de libertad que correspondan.
Aunque esta fórmula es válida para todos los casos, hay planteamientos,
que son también los más frecuentes (como las tablas 2x2), que admiten
fórmulas más sencillas. Vamos a ver ahora los casos más frecuentes con sus
fórmulas específicas.
8. MÉTODOS APLICABLES CUANDO TENEMOS UN SOLO CRITERIO DE CLASIFICACIÓN DIVIDIDO
EN DOS NIVELES
Por ejemplo, preguntamos a un grupo de N = 60 si está a favor o en con-
tra de una determinada proposición y obtenemos estos resultados (tabla 4):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
320
fo son las frecuencias observadas,
ft son las frecuencias teóricas.
La fracción
se calcula en cada casilla y se suman todos
estos valores.
A favor En contra total
40 20 60
Tabla 4](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-320-320.jpg)
![Esta fórmula [2] podemos aplicarla siempre que N sea 25; con números
más bajos (N 25) también suele recomendarse aplicar la corrección de Ya-
tes, que consiste en restar una unidad al numerador antes de elevarlo al cua-
drado (fórmula [3]). De todas maneras ya veremos que la eficacia de esta co-
rrección es muy discutida (porque corrige en exceso).
8.1. Ji cuadrado
Tenemos dos sencillas fórmulas que dan idéntico resultado.
1. Podemos aplicar en primer lugar la fórmula [1], que es la fórmula gene-
ral del ji cuadrado. Lo primero que tenemos que hacer es calcular las fre-
cuencias teóricas, que en este caso son 60/2 = 30: si no hubiera más diferen-
cia entre las dos respuestas que la puramente casual, la frecuencia teórica más
probable sería la que resulta de repartir por igual el número de sujetos entre
las dos categorías.
En las tablas vemos que con un grado de libertad (= k -1) los valores crí-
ticos de c2
son estos:
si c2
3.841 tenemos que p .05
6.635 p .01
10.827 p .001
En nuestro ejemplo p .01: no aceptamos la Hipótesis Nula y aceptamos
que la diferencia entre 40 (a favor) y 20 (en contra) es superior a lo que se
puede encontrar por azar en el caso de que no hubiera una diferencia mayor
de lo casual entre las dos posturas representadas por estas respuestas (a favor
o en contra o cualesquiera otras dos alternativas mutuamente excluyentes).
2. Sin entrar ahora en más explicaciones podemos ver que en estos casos
(un grado de libertad) c2
= z2
; el valor correspondiente de z para a = .05 re-
cordamos que es 1.96 y 1.962
= 3.841, que es el valor correspondiente de c2
.
En estos casos, un mismo grupo dividido en dos niveles de clasificación,
tenemos sin embargo una fórmula más sencilla [2], en la que f1 y f2 son las dos
frecuencias, 40 y 20:
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
321](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-321-320.jpg)
![8.2. Aplicación de la distribución binomial
Cuando tenemos un grupo dividido en dos categorías podemos aplicar di-
rectamente la distribución binomial. Cuando un grupo (sujetos, respuestas,
objetos) de tamaño N se divide en dos categorías que se excluyen mutuamen-
te (como antes, a favor o en contra) podemos ver si la proporción de sujetos
en cada categoría (p y q) se aparta significativamente de p = q = .50 (que se-
ría la Hipótesis Nula: idéntico número de sujetos encada categoría). Vamos a
verlo con muestras pequeñas (N 25) y muestras que ya van siendo mayores
(N 25).
8.2.1. Cuando N 25
En estos casos no necesitamos hacer ningún cálculo (ni aplicar la fórmula
[3]); nos basta consultar las tablas de la distribución binomial que nos dan
la probabilidad exacta que tenemos de encontrar por azar cualquier división
de N sujetos (N 25) en dos categorías. Estas tablas podemos encontralas en
numerosos textos de estadística y también disponemos de cómodos progra-
mas en Internet (Anexo II)5
.
En estas tablas tenemos los valores de N y de X (número de sujetos en
cualquiera de las dos categorías) y la probabilidad de encontrar X en N suje-
tos o casos. Suponemos que en principio p = q, es decir que hay dos catego-
rías con idéntica probabilidad (p = q = .50).
8.2.2. Cuando N 25
Cuando aumenta el número de casos o sujetos, la distribución binomial se
va pareciendo a la distribución normal. En estos casos podemos hacer algo
análogo al contraste de medias.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
322
5
Un programa muy cómodo es GRAPHPAD; basta introducir el número total de sujetos
(objetos, etc.) y el número de los clasificados en una de las dos categorías.
Con números pequeños es sin embargo preferible prescindir de esta co-
rrección y acudir directamente a las tablas de la distribución binomial, que
nos dan directamente la probabilidad un obtener una determinada diferencia
entre dos frecuencias cuando N es muy bajo.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-322-320.jpg)

![En estos casos (un grupo dividido en dos categorías) c2
= z2
y z = ;
Podemos verificarlo: z2
= 2.5822
= 6.67, que es el valor de c2
encontrado
antes (y las probabilidades son las mismas, p.01)
La fórmula [4] es la más clara porque expresa lo que estamos haciendo
(una diferencia entre medias dividida por una desviación típica), pero pue-
de simplificarse notablemente si utilizamos la fórmula [5] (f1 y f2 son las dos
frecuencias):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
324
De todas estas fórmulas ¿Cuál es la preferible? La que resulte más cómoda;
la única salvedad es que todas estas fórmulas son adecuadas cuando N no es
muy bajo (preferiblemente no menos de N = 50).
Ya hemos indicado que:
a) Cuando N es igual o inferior a 20, podemos acudir directamente a las
tablas de la distribución binomial (que nos da la probabilidad de obte-
ner cualquier valor de X para cualquier valor de N hasta 20 o incluso
más, según las tablas de que dispongamos).
b) Cuando N está entre 20 y 50 podemos aplicar la fórmula [3], o la [5]
(más cómoda que la [4]), pero restando una unidad al numerador (en
valores absolutos), o podemos aplicar la fórmula [4] con la llamada co-
rrección por continuidad, tal como aparece en la fórmula [6]
Sumamos o restamos .5 de manera que el nu-
merador sea menor en términos absolutos.
8.2.3. La prueba de los signos: aplicación de la distribución binomial
para comprobar cambios
Una aplicación popular y sencilla para verificar cambios es la conocida co-
mo prueba de los signos que es útil introducir aquí.
Lo veremos con un ejemplo. De un grupo de sujetos tenemos sus res-
puestas a una simple pregunta, por ejemplo sobre la utilidad de la asignatu-](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-324-320.jpg)

![9. MÉTODOS APLICABLES CUANDO TENEMOS UN SOLO CRITERIO DE CLASIFICACIÓN DIVIDIDO
EN MÁS DE DOS NIVELES (PRUEBAS DE BONDAD DE AJUSTE)
A esta aplicación del ji cuadrado se le denomina también prueba de bon-
dad de ajuste porque comprobamos si una distribución de frecuencias obser-
vadas se ajusta a una distribución teórica.
9.1. Cuando las frecuencias esperadas son las mismas
El planteamiento más frecuente lo veremos con un ejemplo: 600 perso-
nas eligen entre tres marcas, A, B y C de un mismo producto, su marca pre-
ferida (tabla 8): ¿Hay diferencias entre las marcas por encima de lo puramen-
te aleatorio?
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
326
Tabla 8
A A C total
170 200 230 600
200 200 200 600
frecuencias observadas:
frecuencias teóricas:
Las frecuencias teóricas son las que habría si no hubiera diferencias entre
las marcas; es la distribución teórica más probable en caso de no diferencia:
número total de casos dividido por el número de categorías de clasificación,
600/3 = 200 (las tres marcas son igualmente preferidas).
En este caso se aplica la fórmula general del ji cuadrado (fórmula [1])
que además se puede utilizar en todos los casos:
Grados de libertad: número de categorías de clasificación menos una:
3-1 = 2 grados de libertad.
En las tablas tenemos que con dos grados de libertad y c2
= 9; p .05 (su-
peramos el valor de 5.99 que tenemos en las tablas). La probabilidad de que
la distribución de las frecuencias observadas (170/200/230) sea casual, en el
que caso de que las marcas fueran igualmente preferidas, es inferior al 5% (de
hecho es inferior al 2%), por lo que concluimos que sí hay diferencias signifi-
cativas entre las marcas. Cabría ahora parcializar los datos y comparar las mar-
cas de dos en dos; (al menos podemos afirmar que la marca A es significati-
vamente menos preferida que la marca C).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-326-320.jpg)
![Podríamos haber hecho otra agrupación distinta, de manera que en cada
intervalo tuviéramos el 20% de los casos, o podríamos tener intervalos con
frecuencias esperadas distintas, como sucede cuando utilizamos los estani-
nos o los pentas.
Si en cada intervalo vamos a tener el 10% de las frecuencias teóricas y te-
nemos N = 200, en cada intervalo tendríamos 20 sujetos en las frecuencias
teóricas; a cada sujeto le calculamos su puntuación típica, y lo situamos en el
intervalo que le corresponda: estas son nuestras frecuencias observadas, y
aplicamos por último la fórmula [1].
Grados de libertad:
En este caso debemos tener en cuenta para consultar las tablas que los
grados de libertad son igual al número de intervalos menos tres (k-3), por-
que partimos de tres restricciones iniciales: los valores de N, de la media y de
la desviación típica.
En esta comprobación lo que nos interesa comprobar es que el valor de c2
es inferior al de las tablas: en este caso no habría diferencia entre las frecuen-
cias observadas y las del modelo teórico, y podemos concluir que nuestra dis-
tribución se aproxima a la distribución normal. Un resultado estadísticamen-
te significativo nos diría que la distribución no puede considerarse normal.
9.2. Cuando las frecuencias esperadas son las de la distribución
normal
Esta prueba de bondad de ajuste se utiliza también para comprobar si una
distribución se ajusta a la distribución normal.
En este caso las categorías de clasificación son intervalos y las frecuencias
teóricas son las que corresponderían en la distribución normal.
Aunque una distribución puede dividirse en intervalos de muchas mane-
ras, lo más cómodo es dividir la distribución en intervalos que tengan un
idéntico número de sujetos, para facilitar las operaciones. Si se divide en 10
intervalos, puede quedar como aparece en la tabla 9.
Tabla 9
frecuencias teóricas:
z: -1.28 -0.84 -0.52 -.025 0.00 +0.25 +0.52 +0.84 +1.28
10% 10% 10% 10% 10% 10% 10% 10% 10% 10%
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
327](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-327-320.jpg)





![La fórmula [7] es la habitual, y la que se utiliza siempre, al menos cuando
N no es muy inferior a 40.
b) Observación sobre la corrección de Yates y el número de sujetos
La fórmula [8] incluye la llamada corrección de Yates (restar N/2 a la dife-
rencia entre ad y bc en valores absolutos antes de elevarla al cuadrado)7
, y
1º Ji cuadrado
a) Planteamiento y fórmulas
Disponemos los datos como es usual (e incluyendo los porcentajes si es
conveniente con fines informativos).
Una observación importante: Convencionalmente las frecuencias de las
cuatro casillas las simbolizamos con las cuatro letras a, b, c y d. Conviene po-
nerlas siempre de la misma manera porque en las fórmulas asociadas a este
planteamiento se supone que se han puesto en ese orden; en alguna fórmu-
la que veremos esto es especialmente importante.
Cuando los datos se codifican como 1 ó 0 (sí o no, bien o mal, etc.), y el
cero significa mal, en desacuerdo, no, etc., es importante que el no, mal,
etc. (lo que codificamos con un 0) estén puestos en la fila c y d (para una va-
riable), y en la columna a y c (para la otra variable), tal como lo ponemos
aquí. Los dos ceros confluyen en c; en ese ángulo se sitúan los valores meno-
res cuando se trata de coordenadas. Naturalmente el 0 y el 1 no tienen senti-
do como juicio de valor cuando sólo significan pertenecer a un grupo u otro
(varón o mujer, un curso u otro, etc.).
Aunque podemos aplicar la fórmula [1], disponemos de fórmulas más sen-
cillas, como son las fórmulas [7] y [8].
tintos y posiblemente es lo más apropiado desde una perspectiva más teórica. Como alter-
nativa y complemento, y con un enfoque quizás más pragmático, preferimos poner aquí
juntos los distintos procedimientos cuando son válidos para analizar los mismos datos.
7
Frank Yates, británico, propuso esta corrección en 1934 (Yates, F (1934). “Contin-
gency table involving small numbers and the ¯2
test”. Journal of the Royal Statistical So-
ciety (Supplement) 1: 217-235).
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
333](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-333-320.jpg)
![suele recomendarse cuando los sujetos son pocos (N 40) o cuando alguna
frecuencia teórica no llega a 5.
Aunque esta corrección de Yates (y el requisito de que las frecuencias
teóricas no sean inferiores a 5) viene rutinariamente en muchos textos (y
en programas de ordenador), hace tiempo que se cuestiona su necesidad
o conveniencia porque una serie de estudios muestran que con esta co-
rrección la prueba del ji cuadrado se convierte en una prueba demasiado
conservadora (no se rechaza la Hipótesis Nula cuando se podría rechazar
legítimamente)8
.
La recomendación tradicional es a) aplicar la corrección de Yates en ta-
blas 2x2 cuando una frecuencia teórica es inferior a 5 y b) no utilizar el ji cua-
drado en tablas mayores si el más del 20% de las frecuencias teóricas es infe-
rior a 5.
c) Orientaciones prácticas para tablas 2x2
Posiblemente la práctica más aconsejable en tablas 2x2 es:
1) Prescindir de esta corrección (fórmula [8]) y utilizar habitualmente la
[7]. Cuando no aplicamos esta corrección en las situaciones en las que
suele o solía ser recomendada, tenemos una prueba más liberal9
.
2) No utilizar el ji cuadrado con pocos sujetos (no muy inferior a N = 40
es una recomendación segura).10
3) Con muestras muy pequeñas (en torno a N = 20) utilizar la prueba
exacta de Fisher (en el apartado siguiente)
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
334
8
A pesar de que esta fórmula [8] se sigue recomendando, ya se va viendo cuestiona-
da en bastantes textos (como el de Daniel, 1981), suprimida y no recomendada en otros
como innecesaria (como en el de Runyon y Haber, 1984; Rosenthal y Rosnow, 1991; Spatz,
1993; Hinkle, Wiersma y Jurs, 1998), y esta no recomendación es elogiada en recensiones
publicadas en revistas de prestigio en este campo (Morse, 1995). Estos autores mencionan
las investigaciones en las que se apoyan, y aquí los citamos a título de ejemplo (se pueden
buscar más citas autorizadas) porque la supresión de esta corrección de Yates (que data de
1934) todavía supone ir en contra de una práctica muy generalizada. El consensus parece
ser que esta corrección hace del ji cuadrado una prueba excesiva e innecesariamente con-
servadora (Black, 1999:580). Otros autores (Heiman, 1996) siguen recomendando el que
las frecuencias teóricas sean superiores a 5 (en tablas 2x2) pero omiten la corrección de Ya-
tes. Un comentario más amplio y matizado sobre la corrección de Yates y otras alternativas
puede verse en Ato García y López García (1996).
9
El programa de VassarStats (Internet, Anexo II) calcula el ji cuadrado con y sin la co-
rrección de Yates.
10
No hay un acuerdo claro sobre el número mínimo de sujetos en el ji cuadrado; Ro-
senthal y Rosnow (1991:514) mencionan N = 20 pero advierten que frecuencias teóricas
muy bajas pueden funcionar bien en muestras todavía más pequeñas.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-334-320.jpg)
![d) Ejemplo resuelto
Podríamos utilizar la fórmula [1], que se puede aplicar siempre, pero es
mucho más cómoda la fórmula [7] que es la que generalmente se utiliza en
estos casos.
Tenemos 161 sujetos clasificados según el grupo al que pertenecen (A o B)
y sus respuestas a una pregunta (sí o no). Disponemos los datos en un cua-
dro de doble entrada (tabla 14).
Tabla 14
La probabilidad de que estas frecuencias sean aleatorias son inferiores al
1/1000 (p .001), ya que nos pasamos del valor señalado en las tablas
(10.827).
Podemos concluir que las dos variables que han servido de criterio de cla-
sificación (responder sí o no a una pregunta y pertenecer a uno u otro grupo)
están relacionadas (o lo que es lo mismo, los grupos difieren significativamen-
te en sus respuestas).
e) Cálculo complementario: coeficiente de correlación
Un valor grande de c2
nos da mucha seguridad para afirmar que existe
asociación entre las dos variables, pero no nos dice si la relación es grande o
pequeña. Para cuantificar el grado de relación tenemos que acudir a alguno
de los coeficientes relacionados con el c2
puestos al final (apartado nº 12).
Los grados de libertad son: (columnas menos una) por (filas menos una)
= (2-1) (2-1) = 1 totales 90 (100%) 71 (100%).
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
335](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-335-320.jpg)
![La relación entre pertenencia a un grupo u otro y responder sí o no a esa
pregunta es moderada. Si hacemos que pertenecer al grupo A = 1, y pertene-
cer al grupo B = 0, y decir que sí = 1 y decir que no = 0 y calculamos el co-
eficiente r de Pearson, obtendremos el mismo resultado.
Disponemos también de otros coeficientes de relación para tablas mayo-
res (el coeficiente de contingencia C es el más popular aunque no el único);
los exponemos y valoramos brevemente en el apartado nº 12.
2º Prueba exacta de Fisher
En tablas 2x2 y con un N bajo (ciertamente 20) es preferible la prueba
exacta de Fisher: basta consultar las tablas apropiadas, en las que vienen to-
das las combinaciones posibles de a, b, c y d con N = 20 o menos (una tabla
para cada valor posible de N). Las tablas nos indican qué combinaciones tie-
nen una probabilidad de ocurrir por azar inferior al 5% o al 1%11
. Otra alterna-
tiva cómoda (además de los programas informáticos más comunes) es utilizar
alguno de los varios programas disponibles en Internet12
.
3º Contraste entre proporciones (muestras independientes)
Como alternativa que da idénticos resultados, podemos utilizar el contras-
te entre proporciones (o entre porcentajes si multiplicamos por 100) para
muestras independientes (fórmula [9]). Obtendremos un valor de z, pero ya
sabemos que en estos casos z2
= c2
El procedimiento ya está explicado en el contraste de medias pero es útil
repetirlo en este contexto para ver su equivalencia con el c2
: dividimos una di-
ferencia entre proporciones por el error típico de la diferencia entre dos
proporciones, que está en el denominador de la fórmula [9]. En rigor lo que
En el caso de tablas 2x2 y con variables dicotómicas (que se excluyen mu-
tuamente) el coeficiente apropiado es el coeficiente ? (fi, fórmula [15] que re-
petimos aquí), que es el mismo coeficiente r de Pearson cuando las dos varia-
bles son dicotómicas (1 y 0):
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
336
11
Estas tablas se encuentran en algunos textos (como el de Siegel, 1972; Siegel y Cas-
tellan, 1988 [tabla 35]; Langley, 1973; Leach, 1982) o en compendios de tablas estadísticas
(como en Meredith, 1971 y en Ardanuy y Tejedor, 2001, tabla I).
12
Anexo II; en estos programas (como GRAPHPAD)
) basta introducir en el cuadro de diá-
logo las cuatro frecuencias a, b, c y d.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-336-320.jpg)
![Ya sabemos que con un grado de libertad c2
= z2
: 5.2892
= 27.97; llegamos
a la misma conclusión que con la prueba del c2
. Los resultados son idénticos
si utilizamos todos los decimales.
10.2. Tablas 2x2 para muestras relacionadas
10.2.1. Procedimientos
a) Ji cuadrado (prueba de McNemar)
Las fórmulas vistas hasta ahora, y referidas al ji cuadrado, son todas equi-
valentes a la fórmula [1]. Las fórmulas para muestras relacionadas nos sir-
ven para comparar dos proporciones (o porcentajes) cuando los mismos su-
jetos pueden estar incluidos en los dos grupos (y en este sentido se trata de
muestras relacionadas, como se puede apreciar con claridad en los ejem-
plos específicos que ponemos después para ilustrar las aplicaciones de este
procedimiento).
tenemos en el numerador no es la diferencia entre dos proporciones, sino la
diferencia entre una diferencia (la nuestra) y una diferencia de cero.
En la fórmula [9] tenemos en el denominador el error típico de la diferen-
cia entre dos proporciones.
Utilizamos como ejemplo los mismos datos de la tabla anterior [14].
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
337
Y aplicando la fórmula [9] a nuestros datos:](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-337-320.jpg)
![Estas fórmulas corresponden a la denominada prueba de McNemar (y así
figura en muchos textos). En estos casos los grados de libertad son igual a 1.
Recordamos la observación importante que ya hemos hecho sobre los
símbolos utilizados: a y d son las celdillas donde se sitúan las frecuencias dis-
crepantes a y d (sí/no y no/sí; 0/1/ y 1/0), por lo que esas fórmulas, expresadas
con estos símbolos, sólo tienen sentido si los datos están bien dispuestos.
b) Contraste entre proporciones relacionadas
Podemos también hacer un contraste de proporciones para muestras re-
lacionadas; como en estos casos (tablas 2x2, un grado de libertad) c2
= z2
, la
fórmula queda simplificada así:
Veremos la utilidad de estas fórmulas con dos ejemplos referidos a dos
planteamientos útiles y frecuentes.
10.2.2. Aplicaciones específicas
a) Para comprobar cambios
Clasificamos a los sujetos según hayan respondido sí o no (o de acuerdo
o en desacuerdo, 1 ó 0, etc.) en dos ocasiones distintas.
Podemos suponer que hemos preguntado a nuestros alumnos si les inte-
resa la asignatura en dos ocasiones, primero al comenzar el curso y más
adelante al terminar el curso (tabla 15).
La fórmula [10] se utiliza cuando (a + d) es
igual o mayor de 10;
La fórmula [11] se utiliza cuando (a + d)
10; se resta una unidad al numerador po-
niendo el signo + a la diferencia; se trata de
disminuir esta diferencia antes de elevarla al
cuadrado.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
338
Tabla 15](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-338-320.jpg)
![Si queremos saber si una pregunta está relacionada con la otra (si el sa-
ber una supone saber también la otra) utilizaremos la fórmula convencional;
en este caso la [1] o la [7].
Pero si lo que queremos es comprobar si una pregunta es más difícil que
la otra (como en este ejemplo), estamos en el mismo caso anterior (muestras
relacionadas, lo mismo que para comprobar un cambio)
La pregunta 1ª la ha respondido correctamente el 65% (39 alumnos), y la
2ª el 17% (10 alumnos). Como algunos alumnos han respondido bien las dos,
tenemos muestras relacionadas.
En ambos casos aplicamos la fórmula [10] porque a + d = 41 (10), y te-
nemos que:
Al comenzar el curso la asignatura interesa a 10 alumnos (17% del total); al
terminar les interesa a 39 (65% del total).
Nos interesa comprobar si este 65% es significativamente superior al 17%
inicial.
Se trata de muestras relacionadas porque hay sujetos que están en los
dos grupos (como los 4 sujetos en (b), interesados tanto antes como después
y los 15 en (c) a quienes no interesa la asignatura ni al comienzo ni al final).
En todas estas tablas hay que prestar atención a la disposición de los datos
de manera que en la celda (c) coincidan los dos ceros y en la celda (b) los dos
unos.
b) Para comprobar una diferencia entre proporciones relacionadas
Se trata del mismo caso anterior pero nos formulamos la pregunta de otra
manera. Repetimos los mismos datos, pero ahora se trata de dos preguntas
de un examen, y respondidas por lo tanto en la misma ocasión (no antes y
después) y que pueden estar bien o mal respondidas; queremos comparar su
nivel de dificultad; ver si una es más difícil que la otra (tabla 16).
Tabla 16
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
339](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-339-320.jpg)
![Con un grado de libertad tenemos que p .001; nuestra conclusión es
que ha habido cambio en el primer ejemplo y que una pregunta es más difí-
cil que la otra en el segundo ejemplo. En ambos casos la diferencia entre
[a+b] y [b+d] es superior a lo que se puede esperar por azar.
Si preferimos un contraste de proporciones para muestras relacionadas,
podemos utilizar la fórmula [12] para obtener el valor de z:
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
340
10.2.3. Adaptación de la prueba de McNemar (muestras relacio-
nadas) para tablas mayores (nxn)
La fórmula de McNemar es apropiada para tablas 2x2, pero se puede adap-
tar para tablas mayores, como en este ejemplo para comprobar un supuesto
cambio. La pregunta que se ha hecho antes y después admite en este caso
tres respuestas: sí, no sé y no (podrían ser otras categorías de respuesta o de
observación, como bien, regular y mal si hay criterios claros para este tipo de
clasificación).
Como en tablas semejantes, los noes (el nivel más bajo) deben coincidir en
la celda inferior izquierda y los síes (el nivel más alto) en la celda superior de-
recha (tabla 17a). Lo que hemos hecho (tabla 17b) es agrupar los cambios ne-
gativos (de sí a no y a no sé, y de no sé a no) y los cambios positivos (de no a
no sé y sí y de no sé a sí), y ya tenemos los dos valores, a y d, de la fórmula [10].
(32 – 10)2
Ahora podemos aplicar la fórmula [10]: c2
= ––––––––– = 11.52, p .001;
32 + 10
Tabla 17a Tabla 17b
; el resultado es el mismo](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-340-320.jpg)
![Podemos concluir que sí ha habido un cambio positivo superior a lo que
cabría esperar por azar.13
11. DOS CRITERIOS DE CLASIFICACIÓN, CADA UNO DIVIDIDO EN DOS O MÁS NIVELES
(TABLAS NXN)
En este caso se aplica la fórmula general [1].
El procedimiento es el siguiente:
1º En cada casilla se calcula la frecuencia teórica (tal como se ve en el
apartado nº 4)
2º En cada casilla se calcula el valor correspondiente de ji cuadrado,
3º Por último se suman todos estos valores de ji cuadrado de cada casi-
lla en un valor único de ji cuadrado que es el que consultamos en las
tablas.
Lo veremos con un ejemplo14
. Se ha hecho una encuesta de opinión entre
los accionistas de una determinada empresa, para ver si su posición frente a
una posible fusión con otra empresa era independiente o no del número de
acciones que cada uno de ellos tiene. Tenemos las respuestas de 200 accionis-
tas clasificados según el número de acciones (tabla 18); debajo de cada fre-
cuencia observada se pone el tanto por ciento con respecto al total de la fila
(número de acciones), porque resulta más informativo (también cabría poner
los tantos por ciento con respecto al total de la columna).
Tabla 18
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
341
13
Otra alternativa para tablas 3x3 y muestras relacionadas podemos verla en Hinkle,
Wiersma y Jurs (1998).
14
Ejemplo tomado de W
. Mendenhall y James E. Reinmouth (1978), Estadística para
administración y economía, México, Grupo Editorial Iberoamericana.](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-341-320.jpg)

![La relación es más bien baja, aunque se puede afirmar con mucha seguri-
dad que sí hay relación.
Si queremos interpretar con más detalle la información disponible, pode-
mos fijarnos en qué casillas hay una mayor discrepancia entre las frecuencias
observadas y las teóricas; esto nos lo indican los mismos valores del ji cua-
drado, que son mayores en unas casillas que en otras. Lo que está más claro
es la discrepancia:
En la casilla h (entre los que tienen más de 500 acciones hay más en
contra de la fusión que los que podríamos esperar),
En la casilla a (entre los que tienen menos de 100 acciones hay más a fa-
vor de la fusión)
En la casilla b (entre los que tienen menos de 100 acciones hay menos
en contra de la fusión).
En los cuadros 2x2 la interpretación suele ser más fácil e intuitiva, en cua-
dros grandes no siempre es tan sencillo y hay que fijarse cómo se distribuyen
las frecuencias. Hay métodos específicos para parcializar estos cuadros y ha-
cer una interpretación más matizada15
.
Los grados de libertad son (3-1)(3-1) = 4. Con cuatro grados de libertad
rechazamos la Hipótesis Nula con una probabilidad de error inferior al 5%
(p.05; el valor de las tablas es 9.488 y nosotros lo superamos; en realidad la
probabilidad es p.02).
Podemos afirmar con mucha seguridad que el número de acciones que
uno tiene en la empresa está relacionado con la postura frente a la posible fu-
sión de la empresa con otra.
Coeficientes de asociación
Para comprobar si la relación es grande o pequeña acudimos a alguno
de los coeficientes de asociación relacionados con el ji cuadrado (en el
apartado siguiente Coeficientes de relación asociados al c2
se comentan
estos coeficientes).
En este caso (tablas mayores de 2x2) el coeficiente más utilizado es el co-
eficiente de contingencia (fórmula [13]):
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
343
15
Pueden verse en Linton, Gallo Jr. y Logan (1975).](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-343-320.jpg)




![ANEXO I. TABLAS DEL JI CUADRADO
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
348
Grados p = p = p = Grados p = p = p = Grados p = p = p =
de 0.05 0.01 0.001 de 0.05 0.01 0.001 de 0.05 0.01 0.001
libertad libertad libertad
1 3.84 6.64 10.83 13 22.36 27.69 34.53 24 36.42 42.98 51.18
3 7.82 11.35 16.27 14 23.69 29.14 36.12 25 37.65 44.31 52.62
4 9.49 13.28 18.47 15 25.00 30.58 37.70 26 38.89 45.64 54.05
5 11.07 15.09 20.52 16 26.30 32.00 39.25 27 40.11 46.96 55.48
6 12.59 16.81 22.46 17 27.59 33.41 40.79 28 41.34 48.28 56.89
7 14.07 18.48 24.32 18 28.87 34.81 42.31 29 42.56 49.59 58.30
8 15.51 20.09 26.13 19 30.14 36.19 43.82 30 43.77 50.89 59.70
9 16.92 21.67 27.88 20 31.41 37.57 45.32 40 55.76 63.69 73.41
10 18.31 23.21 29.59 21 32.67 38.93 46.80 50 67.51 76.15 86.66
11 19.68 24.73 31.26 22 33.92 40.29 48.27 60 79.08 88.38 99.62
12 21.03 26.22 32.91 23 35.17 41.64 49.73 70 90.53 100.42 112.31
Tablas adaptadas y abreviadas de Alexei Sharov, Virginia Tech, Blacksburg, VA, Quantitative Po-
pulation Ecology, On-Line Lectures [ http://www.ento.vt.edu/~sharov/PopEcol/] http://www.en-
to.vt.edu/~sharov/PopEcol/tables/chisq.html
Tablas más completas y las probabilidades exactas de cualquier valor de ji cua-
drado pueden verse en varias direcciones de Internet:
INSTITUTE OF PHONETIC SCIENCES (IFA) (Statistical tests h
ht
tt
tp
p:
:/
//
/f
fo
on
ns
sg
g3
3.
.l
le
et
t.
.u
uv
va
a.
.n
nl
l/
/S
Se
er
r-
-
v
vi
ic
ce
e/
/S
St
ta
at
ti
is
st
ti
ic
cs
s.
.h
ht
tm
ml
l), The Chi-square distribution h
ht
tt
tp
p:
:/
//
/f
fo
on
ns
sg
g3
3.
.l
le
et
t.
.
u
uv
va
a.
.n
nl
l/
/S
Se
er
rv
vi
ic
ce
e/
/S
St
ta
at
ti
is
st
ti
ic
cs
s/
/C
Ch
hi
iS
Sq
qu
ua
ar
re
e_
_d
di
is
st
tr
ri
ib
bu
ut
ti
io
on
n.
.h
ht
tm
ml
l (calcula la pro-
babilidad introduciendo los valores de ji cuadrado y los grados de libertad).
JONES, JAMES, Statistics: Lecture Notes http://www.richland.edu/james/lecture/m170/
http://www.richland.cc.il.us/james/lecture/m170/tbl-chi.html
LOWRY, RICHARD, Vassar Stats http://faculty.vassar.edu/lowry/VassarStats.html (buscar
en el menú: distributions)
SHAROV
, ALEXEI, On-line lectures Department of EntomologyVirginia Tech, Blacksburg,
VA [http://www.ento.vt.edu/~sharov/PopEcol/ Statistical Tables] http://www.en-
to.vt.edu/~sharov/PopEcol/tables/chisq.html (tablas de c2
hasta 100 grados de
libertad, p = .05, .01 y .001).
STOCKBURGER , DAVID W. Introduction to Statistics: Concepts, Models, and Aplications
CRITICAL VALUES FOR THE CHI-SQUARE DISTRIBUTION http://www.
psychstat.smsu.edu/introbook/chisq.htm
WALKER, JOHN, RetroPsychoKinesis Project Home http://www.fourmilab.ch/rpkp/expe-
riments/analysis/chiCalc.html [calcula la probabilidad (p) de c2
a partir de los
valores de c2
y de los grados de libertad, y el valor de c2
a partir de p (probabili-
dad) y grados de libertad].](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-348-320.jpg)
![ANEXO II. JI CUADRADO Y ANÁLISIS AFINES EN INTERNET
ARSHAM, HOSSEIN Europe Mirror Site Collection, [Tablas hasta 6x6] http://home.
ubalt.edu/ntsbarsh/Business-stat/otherapplets/Normality.htm#rmenu (menú Chi-
square Test for Relationship)
COLLEGE OF SAINT BENEDICT, SAINT JOHN’S UNIVERSITY, Contingency Tables http://www.
physics.csbsju.edu/stats/contingency.html
LOWRY, RICHARD, Vassar Stats [Tablas 2x2, con y sin corrección de Yates, coeficiente phi],
http://faculty.vassar.edu/lowry/VassarStats.html (menú: frequency data)
LOWRY, RICHARD, Vassar Stats [Tablas hasta 5x5] http://faculty.vassar.edu/lowry/VassarS-
tats.html (buscar en el menú: frequency data)
PREACHER, KRISTOPHER J. (May, 2001) The Ohio State University, Calculation for the Chi-
Square Test, An interactive calculation tool for chi-square tests of goodness of
fit and independence (Tablas hasta 10x10, válido para una sola fila o columna)
http://www.psych.ku.edu/preacher/chisq/chisq.htm (consultado 28, 03, 08)
Prueba exacta de Fisher
COLLEGE OF SAINT BENEDICT, SAINT JOHN’S UNIVERSITY, http://www.physics.csbsju.
edu/stats/fisher.form.html
LOWRY, RICHARD, Vassar Stats, Fisher’s Exact Probability Test http://faculty.vassar.edu/
lowry/fisher.html (Vassar Stats Web Site for Statistical Computation: http://fa-
culty.vassar.edu/lowry/VassarStats.html) [Vassar College, Poughkeepsie, New
York]
ØYVIND LANGSRUD, Fisher’s Exact Test http://www.langsrud.com/fisher.htm ,
PREACHER, KRISTOPHER J. and BRIGGS, NANCY E., Calculation for Fisher’s Exact Test,
http://www.psych.ku.edu/preacher/ (o directamente http://www.psych.ku.edu/
preacher/fisher/fisher.htm
SISA, Simple Interactive Statistical Analysis FisherExact http://home.clara.net/sisa/fis-
her.htm y Fisher 2 by 5 http://home.clara.net/sisa/fiveby2.htm
McNemar, Binomial, prueba de los signos
GRAPHPAD, Free Calculators for Scientists Sign and binomial test http://graphpad.
com/quickcalcs/binomial1.cfm (índice de todos los análisis: http://graphpad.
com/quickcalcs/index.cfm)
GRAPHPAD, Free Calculators for Scientists [http://www.graphpad.com/quickcalcs/
index.cfm] McNemar’s test to analyze a matched case-control study
http://www.graphpad.com/quickcalcs/McNemar1.cfm
SISA, Simple Interactive Statistical Analysis Pairwise T-test | Wilcoxon | Signs test |
Mc-Nemar http://home.clara.net/sisa/pairwhlp.htm
ANÁLISIS DEVARIABLES NOMINALES: LA PRUEBA DE JI CUADRADO (c2
)
349](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-349-320.jpg)


![COHEN J. (1988), Statistical Power Analysis for the Behavioral Sciences, second edi-
tion. Hillsdale, N.J.: Lawrence Erlbaum.
COHEN, J. (1960), A Coefficient of Agreement for Nominal Scales, Educational and
Psychological Measurement, 20, 1, 36-46.
COHEN, J. (1977), Statistical Power Analysis for the Behavioral Sciences. New York:
Academic Press, [2nd. edit., 1988, Hillsdale, N.J.: Erlbaum].
COHEN, P
. A. (1981), Student Ratings of Instruction and Student Achievement: A Meta-
analysis of Multisection Validity Studies. Review of Educational Research, 51,
281-309.
CRONBACH, L. J. (1951), Coefficient Alpha and the Internal Structure of Tests. Psycho-
metrika, 16, 297-334.
CRONBACH, L. J. and SHAVELSON, R. J. (2004), My Current Thoughts on Coefficient Alpha
and Succesor Procedures. Educational and Psychological Measurement, 64
(3), 391-418.
DALLAL, G. E. (last revision 2001), The Little Handbook of Statistical Practice (en Frank
Anscombe’s Regression Examples http://www.StatisticalPractice.com (consulta-
do 16, 04, 07).
DANIEL, W
. W. (1981), Estadística con aplicaciones a las ciencias sociales y a la edu-
cación. Bogotá: McGraw-Hill Latinoamericana.
DOWNIE, N. M. y HEATH, R. W
. (1971), Métodos estadísticos aplicados: México: Harper;
(Madrid: Editorial del Castillo).
DUHACHEK, A. and IACOBUCCI, D. (2004), Alpha’s Standard Error (ASE): An Accurate and
Precise Confidence Interval Estimate. Journal of Applied Psychology, Vol. 89 Is-
sue 5, p792-808.
ETXCHEBERRIA, J. (1999), Regresión múltiple. Madrid: La Muralla.
FAN, X. and THOMPSON, B. (2001), Confidence Intervals About Score Reliability Coeffi-
cients, please: An EPM Guidelines Editorial. Educational and Psychological Me-
asurement, 61 (4), 517-531.
FELDT, L. S. (1975), Estimation of the Reliability of a Test Divided into Two Parts of Une-
qual Length, Psychometrika, 40, 4, 557-561.
FELDT, L. S. and KIM, S. (2006), Testing the Difference Between Two Alpha Coefficients
With Small Samples of Subjects and Raters. Educational and Psychological Me-
asurement, 66 (4), 589-600.
FINK, A. (1998), Conducting Research Literature Reviews, From Paper to the Internet.
Thousand Oaks London: Sage Publications.
FOX, J. (1993), Regression diagnostics: An Introduction. En LEWIS-BECK, MICHAEL S.
(Ed.). Regression Analysis. International Handbooks of Quantitative Applica-
tions in the Social Sciences, Volume 2. London: SAGE Publications, 245-334.
GARDNER, P
. L. (1970), Test Length and the Standard Error of Measurement. Journal of
Educational Measurement 7 (4), 271–273.
GLASS, G. V
., MCGAW
, B. and SMITH, M. L. (1981), Meta-Analysis in Social Research. Be-
verly Hills, Cal.: Sage Publications.
GLINER, J. A.; LEECH, N. L. and MORGAN, G. A. (2002), Problems With Null Hypothesis
Significance Testing (NHST): What Do the Textbooks Say? The Journal of Expri-
mental Education. 71 (1), 83-92.
ESTADÍSTICA APLICADA A LAS CIENCIAS SOCIALES
352](https://image.slidesharecdn.com/downacademia-221205140751-07f89d63/85/estadistica-aplicada-a-las-ciencias-sociales-pdf-352-320.jpg)