
Recomendados
Más contenido relacionado
Similar a Hipótesis estadística, mapas conceptuales
Similar a Hipótesis estadística, mapas conceptuales (20)
Último
Último (20)
Hipótesis estadística, mapas conceptuales
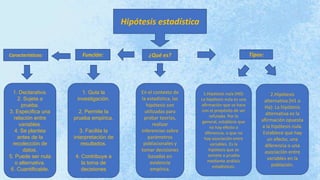
- 1. Hipótesis estadística ¿Qué es? Función: Tipos: En el contexto de la estadística, las hipótesis son utilizadas para probar teorías, realizar inferencias sobre parámetros poblacionales y tomar decisiones basadas en evidencia empírica. 1. Guía la investigación. 2. Permite la prueba empírica. 3. Facilita la interpretación de resultados. 4. Contribuye a la toma de decisiones Características: 1. Declarativa. 2. Sujeta a prueba. 3. Especifica una relación entre variables. 4. Se plantea antes de la recolección de datos. 5. Puede ser nula o alternativa. 6. Cuantificable. 1.Hipótesis nula (H0): La hipótesis nula es una afirmación que se hace con el propósito de ser refutada. Por lo general, establece que no hay efecto o diferencia, o que no hay asociación entre variables. Es la hipótesis que se somete a prueba mediante análisis estadísticos. 2.Hipótesis alternativa (H1 o Ha): La hipótesis alternativa es la afirmación opuesta a la hipótesis nula. Establece que hay un efecto, una diferencia o una asociación entre variables en la población.
- 2. Hipótesis estadística Interpretar la prueba de una hipótesis estadística: Aplicar el procedimiento general para la prueba de hipótesis: La interpretación de la prueba de una hipótesis estadística depende del resultado obtenido. La prueba de hipótesis generalmente se realiza para determinar si existe evidencia suficiente en los datos para rechazar una afirmación sobre una población, es decir, la hipótesis nula. Si el valor p (p-value) es menor que el nivel de significancia predefinido (usualmente 0.05), entonces se rechaza la hipótesis nula en favor de la hipótesis alternativa. Esto significa que hay evidencia suficiente para concluir que la afirmación original es falsa. Por otro lado, si el valor p es mayor que el nivel de significancia, entonces no se rechaza la hipótesis nula. Esto indica que no hay suficiente evidencia en los datos para rechazar la afirmación original. 1. Formulación de hipótesis: - Hipótesis nula (H0): Es la afirmación que se está probando. Por lo general, se establece que no hay efecto o diferencia. - Hipótesis alternativa (H1): Es la afirmación opuesta a la hipótesis nula. Se establece que hay un efecto o diferencia. 2. Selección del nivel de significancia (α): - El nivel de significancia es la probabilidad de cometer un error de tipo I al rechazar la hipótesis nula cuando es verdadera. Usualmente se fija en 0.05, pero puede variar según el contexto. 3. Recopilación de datos: - Se recolectan los datos relevantes para la prueba de hipótesis. 4. Elección de la prueba estadística apropiada: - Dependiendo de la naturaleza de los datos y del tipo de hipótesis a probar, se selecciona la prueba estadística adecuada (t de Student, chi-cuadrado, ANOVA, etc.). 5. Cálculo del valor p: - Se realiza el cálculo del valor p utilizando la prueba estadística seleccionada. 6. Toma de decisión: - Si el valor p es menor que el nivel de significancia (α), se rechaza la hipótesis nula en favor de la hipótesis alternativa. - Si el valor p es mayor que el nivel de significancia (α), no se rechaza la hipótesis nula. 7. Interpretación de los resultados: - Se interpreta el resultado en función del valor p y se concluye si hay evidencia suficiente para rechazar o no rechazar la hipótesis nula.
- 3. Ejemplos: Supongamos que un fabricante de baterías afirma que la vida útil promedio de sus baterías es de al menos 1000 horas. Para verificar esta afirmación, un grupo de investigadores selecciona una muestra aleatoria de 30 baterías y mide su vida útil en horas. Los datos recolectados muestran una vida útil promedio de 980 horas con una desviación estándar de 100 horas. Ahora, planteamos las hipótesis: - Hipótesis nula (H0): La vida útil promedio de las baterías es igual a 1000 horas (μ = 1000). - Hipótesis alternativa (H1): La vida útil promedio de las baterías es menor que 1000 horas (μ < 1000). Seleccionamos un nivel de significancia de α = 0.05. Dado que estamos comparando la media de una muestra con un valor específico y conocemos la desviación estándar poblacional, utilizaremos la prueba t de Student para una muestra. Calculamos el valor t utilizando la fórmula:
- 4. Donde: - X es la media muestral (980 horas), - μ es el valor propuesto por la hipótesis nula (1000 horas), - s es la desviación estándar muestral (100 horas), - n es el tamaño de la muestra (30). Sustituyendo los valores, obtenemos: T = 980 – 1000/100/√(30)≈ -2.12 Consultando la tabla de distribución t-Student con 29 grados de libertad y un nivel de significancia de 0.05, encontramos que el valor crítico es aproximadamente -1.699. El valor p asociado con un valor t de -2.12 es menor que 0.05. Por lo tanto, rechazamos la hipótesis nula. Concluimos que hay evidencia suficiente para afirmar que la vida útil promedio de las baterías es menor que 1000 horas, respaldando la hipótesis alternativa.
- 5. Supongamos que un equipo de investigadores está interesado en determinar si un nuevo tratamiento para la ansiedad es más efectivo que el tratamiento estándar. Para ello, llevan a cabo un estudio en el que comparan los niveles de ansiedad de dos grupos: uno tratado con el tratamiento estándar y otro tratado con el nuevo tratamiento. Planteamos las hipótesis: - Hipótesis nula (H0): No hay diferencia en los niveles de ansiedad entre los dos tratamientos. - Hipótesis alternativa (H1): El nuevo tratamiento es más efectivo en la reducción de los niveles de ansiedad que el tratamiento estándar. Luego, realizamos la prueba estadística y obtenemos un valor p de 0.03. Seleccionamos un nivel de significancia de α = 0.05. La interpretación de los resultados sería la siguiente: - Dado que el valor p (0.03) es menor que el nivel de significancia (0.05), rechazamos la hipótesis nula. - Esto significa que hay evidencia suficiente para afirmar que el nuevo tratamiento es más efectivo en la reducción de los niveles de ansiedad que el tratamiento estándar. - En otras palabras, los datos sugieren que existe una diferencia significativa en los efectos de los dos tratamientos sobre la ansiedad. Por lo tanto, en este ejemplo, la interpretación de la prueba de hipótesis estadística nos lleva a concluir que el nuevo tratamiento es más efectivo que el tratamiento estándar en la reducción de los niveles de ansiedad.
- 6. Supongamos que un fabricante de baterías afirma que sus baterías duran en promedio más de 5 horas. Un grupo de consumidores escépticos decide poner a prueba esta afirmación y realiza un estudio para determinar si la duración promedio de las baterías realmente supera las 5 horas. El procedimiento general para la prueba de hipótesis consiste en los siguientes pasos: 1. Planteamiento de las hipótesis: - Hipótesis nula (H0): La duración promedio de las baterías es igual a 5 horas. - Hipótesis alternativa (H1): La duración promedio de las baterías es mayor a 5 horas. 2. Recolección de datos: El grupo de consumidores adquiere una muestra aleatoria de 30 baterías del fabricante y registra la duración de cada una en horas. 3. Elección del nivel de significancia: Los consumidores deciden utilizar un nivel de significancia α = 0.05. 4. Cálculo de la estadística de prueba: Utilizando la muestra recopilada, calculan la media muestral y la desviación estándar muestral para la duración de las baterías. Luego, utilizan esta información para calcular la estadística de prueba (t) utilizando la fórmula
- 7. 4. Cálculo de la estadística de prueba: Utilizando la muestra recopilada, calculan la media muestral y la desviación estándar muestral para la duración de las baterías. Luego, utilizan esta información para calcular la estadística de prueba (t) utilizando la fórmula correspondiente para la prueba t de una muestra. 5. Determinación del valor crítico y el p-valor: Con el valor de la estadística de prueba (t) calculado, consultan una tabla de distribución t-student para determinar el valor crítico correspondiente al nivel de significancia y los grados de libertad. También calculan el p-valor asociado a la estadística de prueba. 6. Toma de decisión: Comparan el valor crítico con la estadística de prueba y el p-valor. Si la estadística de prueba cae en la región de rechazo (mayor que el valor crítico) o el p-valor es menor que el nivel de significancia, rechazan la hipótesis nula. De lo contrario, no hay suficiente evidencia para rechazarla. En este ejemplo, supongamos que después de realizar todos los cálculos, obtienen una estadística de prueba (t) de 2.14 y un p-valor de 0.021. La decisión sería: - Dado que el p-valor (0.021) es menor que el nivel de significancia (0.05), rechazan la hipótesis nula. - Concluyen que hay evidencia suficiente para afirmar que la duración promedio de las baterías supera las 5 horas, respaldando la afirmación del fabricante.
- 8. Muestreo aleatorio: El muestreo aleatorio es un método de selección de una muestra de una población en el que cada miembro de la población tiene una probabilidad conocida y no nula de ser seleccionado en la muestra. En otras palabras, cada elemento de la población tiene la misma oportunidad de ser incluido en la muestra. Este método es fundamental para garantizar que la muestra sea representativa de la población y que los resultados obtenidos puedan generalizarse. Población: En estadística, la población se refiere al conjunto completo de todos los elementos o individuos que comparten una característica común y sobre los cuales se desea hacer inferencias o generalizaciones. Por ejemplo, si estamos interesados en estudiar la estatura de todos los estudiantes de una universidad en particular, la población estaría formada por todos los estudiantes matriculados en esa universidad. Estadístico: Un estadístico es cualquier cantidad calculada a partir de los datos de una muestra. Los estadísticos se utilizan para hacer inferencias sobre las características de la población a partir de la muestra. Algunos ejemplos comunes de estadísticos son la media, la desviación estándar, la proporción, el coeficiente de correlación, entre otros. Por ejemplo, si tomamos una muestra de estudiantes y calculamos la media de sus estaturas, esa media sería un estadístico que nos proporciona información sobre la estatura promedio en esa muestra específica.
- 9. Distribución de muestreo: La distribución de muestreo es un concepto fundamental en estadística que se refiere a la distribución de los posibles valores de un estadístico calculado a partir de diferentes muestras de la misma población. En otras palabras, es la distribución teórica de los valores que puede tomar un estadístico si se calcula repetidamente a partir de muestras aleatorias de una población. Por ejemplo, si estamos interesados en la media de estaturas de todos los estudiantes de una universidad, podríamos tomar múltiples muestras aleatorias de estudiantes y calcular la media de estaturas en cada una de esas muestras. La distribución de muestreo nos proporciona información sobre la variabilidad y el comportamiento esperado de esas medias muestrales. La distribución de muestreo es fundamental para la inferencia estadística, ya que nos permite entender la probabilidad de que un estadístico tome ciertos valores y nos proporciona herramientas para realizar pruebas de hipótesis, intervalos de confianza y otras inferencias sobre los parámetros poblacionales. Una de las distribuciones de muestreo más conocidas es la distribución normal, que describe la distribución teórica de la media muestral cuando el tamaño de la muestra es lo suficientemente grande. Sin embargo, existen muchas otras distribuciones de muestreo que se utilizan en diferentes contextos y para distintos estadísticos.
- 10. Teorema central del límite: El teorema central del límite (TCL) es uno de los conceptos más importantes en estadística y probabilidad. Este teorema establece que, bajo ciertas condiciones, la distribución de la suma o promedio de un gran número de variables aleatorias independientes y con una media finita tiende a aproximarse a una distribución normal, sin importar la forma de la distribución original de las variables. El teorema central del límite es fundamental porque permite que muchas pruebas estadísticas y métodos de inferencia funcionen, incluso si la población subyacente no sigue una distribución normal. Esto es importante en la práctica, ya que muchas veces no conocemos la distribución verdadera de la población. Estimación puntual por intervalos: La estimación puntual por intervalos es un concepto importante en estadística que nos permite obtener un rango de valores dentro del cual es probable que se encuentre un parámetro poblacional desconocido. En lugar de proporcionar un único valor como estimación puntual, la estimación por intervalos nos da un intervalo de confianza en el cual es probable que se encuentre el verdadero valor del parámetro. El intervalo de confianza se construye a partir de la estimación puntual y del error estándar de esa estimación. El error estándar refleja la variabilidad esperada en la estimación puntual debido al muestreo aleatorio. Al construir un intervalo de confianza, se utiliza la distribución de probabilidad de la estimación puntual para determinar los límites del intervalo.
- 11. Intervalos de confianza para la media poblacional: Un intervalo de confianza para la media poblacional es una estimación estadística que nos proporciona un rango dentro del cual es probable que se encuentre la verdadera media de la población, con cierto nivel de confianza. La fórmula general para un intervalo de confianza para la media poblacional (μ) es: Intervalo de confianza = Estimación puntual ± Margen de error Donde la estimación puntual es típicamente la media muestral (x) y el margen de error depende del nivel de confianza y del error estándar de la estimación. El margen de error se calcula utilizando la distribución t de Student o la distribución normal, dependiendo del tamaño muestral y si se conoce o no la desviación estándar poblacional. La fórmula general para el margen de error utilizando la distribución t de Student es: Margen de error = t * (error estándar) Donde “t” es el valor crítico de la distribución t de Student para el nivel de confianza deseado y los grados de libertad correspondientes. El error estándar se calcula como la desviación estándar muestral dividida por la raíz cuadrada del tamaño muestral. Si la desviación estándar poblacional es conocida, el margen de error se calcula utilizando la distribución normal estándar:
- 12. Margen de error = Z * (error estándar) Donde “Z” es el valor crítico de la distribución normal estándar para el nivel de confianza deseado. Hipótesis: estadística, nula, altema: Una hipótesis estadística es una afirmación o suposición sobre los parámetros de una población. Estas hipótesis se formulan para ser probadas mediante el análisis de datos muestrales. Las hipótesis estadísticas suelen estar relacionadas con la media, la varianza u otros parámetros de una distribución. Las hipótesis estadísticas se dividen en dos categorías principales: la hipótesis nula (H0) y la hipótesis alternativa (H1). La hipótesis nula es una afirmación que se asume como verdadera a menos que haya evidencia suficiente en contra de ella. La hipótesis alternativa es la afirmación contraria a la hipótesis nula y es lo que se intenta demostrar si hay suficiente evidencia. Las pruebas de hipótesis estadísticas se utilizan para evaluar la validez de las afirmaciones sobre los parámetros de una población, y son fundamentales en la toma de decisiones basadas en datos. Reglas de decisión, error tipo I y II: Las reglas de decisión en el contexto de las pruebas de hipótesis estadísticas están relacionadas con la aceptación o rechazo de la hipótesis nula (H0) en función de la evidencia muestral. Cuando se realizan pruebas de hipótesis, se toman decisiones basadas en el análisis de los datos, y estas decisiones están sujetas a dos tipos de errores: el error tipo I y el error tipo II.
- 13. El error tipo I ocurre cuando se rechaza incorrectamente la hipótesis nula (H0) cuando en realidad es verdadera. En otras palabras, se llega a la conclusión de que hay evidencia suficiente para rechazar la hipótesis nula, pero en realidad no existe tal evidencia. El error tipo I también se conoce como “falso positivo”. Por otro lado, el error tipo II ocurre cuando se falla en rechazar la hipótesis nula (H0) cuando en realidad es falsa. En este caso, no se encuentra suficiente evidencia para rechazar la hipótesis nula, pero debería haberse rechazado. El error tipo II también se conoce como “falso negativo”. Las reglas de decisión se establecen para controlar el riesgo de cometer estos dos tipos de errores. Por lo general, se utiliza un nivel de significancia (α) para controlar el riesgo de cometer un error tipo I. El nivel de significancia representa la probabilidad máxima que un investigador está dispuesto a aceptar para cometer un error tipo I. Asimismo, la potencia de una prueba estadística está relacionada con la probabilidad de evitar un error tipo II, es decir, la probabilidad de rechazar la hipótesis nula cuando es falsa. Potencial de un test: El potencial de un test estadístico, también conocido como la “potencia de la prueba”, se refiere a la probabilidad de que el test detecte un efecto cuando realmente existe. En otras palabras, la potencia de un test estadístico es su capacidad para rechazar la hipótesis nula (H0) cuando esta es falsa. La potencia de una prueba estadística está relacionada con la probabilidad de evitar un error tipo II, es decir, la probabilidad de detectar un efecto significativo cuando este efecto realmente existe en la población. Por lo tanto, una prueba con alta potencia tiene una mayor capacidad para detectar diferencias o efectos reales en la
- 14. La potencia de una prueba estadística depende de varios factores, incluyendo el tamaño del efecto en la población, el tamaño de la muestra, el nivel de significancia (α) y la varianza de la población. Cuanto mayor sea el tamaño del efecto, mayor será la potencia de la prueba. Del mismo modo, una muestra más grande tiende a aumentar la potencia del test. Es importante considerar el potencial de un test al diseñar un estudio o al realizar pruebas de hipótesis, ya que una baja potencia puede conducir a la no detección de efectos importantes, lo que resulta en conclusiones erróneas. Nivel de significación: El nivel de significación, denotado por la letra griega α (alfa), es un parámetro crucial en las pruebas de hipótesis estadísticas. Representa la probabilidad máxima que un investigador está dispuesto a aceptar para cometer un error tipo I al rechazar incorrectamente la hipótesis nula (H0) cuando en realidad es verdadera. En otras palabras, el nivel de significación (α) establece el umbral de evidencia requerido para rechazar la hipótesis nula. Si el valor p (resultado de la prueba) es menor que α, se rechaza la hipótesis nula en favor de la hipótesis alternativa. Comúnmente, los niveles de significación más utilizados son 0.05 (o 5%) y 0.01 (o 1%). La elección del nivel de significación depende del contexto del estudio, la importancia práctica de cometer un error tipo I y la necesidad de controlar este tipo de error. Un nivel de significación más bajo (por ejemplo, 0.01) conlleva un mayor grado de exigencia para rechazar la hipótesis nula, lo que reduce la probabilidad de cometer un error tipo I, pero puede aumentar la probabilidad de cometer un error tipo II.
- 15. Es importante comprender que el nivel de significación no proporciona información sobre la magnitud o relevancia práctica del efecto observado. Simplemente establece un estándar para evaluar si hay evidencia suficiente en contra de la hipótesis nula. Contraste de hipótesis: El contraste de hipótesis, también conocido como prueba de hipótesis, es un procedimiento estadístico que se utiliza para tomar decisiones sobre las características de una población basándose en la información proporcionada por una muestra. En esencia, implica comparar la evidencia muestral con una afirmación acerca de una característica específica de la población, conocida como hipótesis nula (H0). El pr”ceso de contraste de hipótesis generalmente implica los siguientes pasos: Formulación de hipótesis: Se plantean dos hipótesis mutuamente excluyentes: la hipótesis nula (H0) y la hipótesis alternativa (H1). La hipótesis nula representa la situación existente o el estado actual, mientras que la hipótesis alternativa sugiere un cambio o efecto en la población. Elección del nivel de significación: Se selecciona un nivel de significación (α) que representa la probabilidad máxima que el investigador está dispuesto a aceptar para cometer un error tipo I al rechazar incorrectamente la hipótesis nula. Realización de la prueba estadística: Se calcula una estadística de prueba a partir de los datos muestrales y se compara con un valor crítico o se calcula el valor p (probabilidad asociada a los resultados observados).
- 16. Toma de decisión: Se compara el valor p con el nivel de significación (α) y se decide si se rechaza o no se rechaza la hipótesis nula. Si el valor p es menor que α, se rechaza la hipótesis nula en favor de la hipótesis alternativa. El contraste de hipótesis es una herramienta fundamental en la inferencia estadística y se utiliza en una amplia gama de disciplinas para evaluar afirmaciones sobre parámetros poblacionales, efectos de tratamientos, diferencias entre grupos, entre otros.