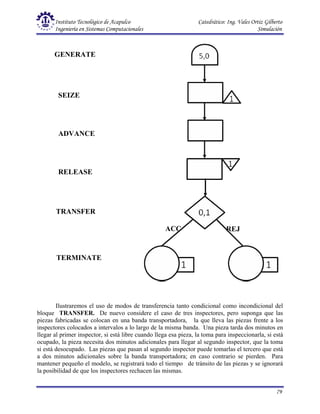
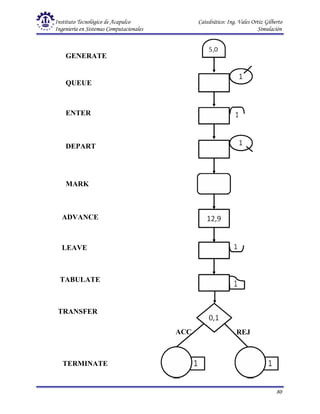
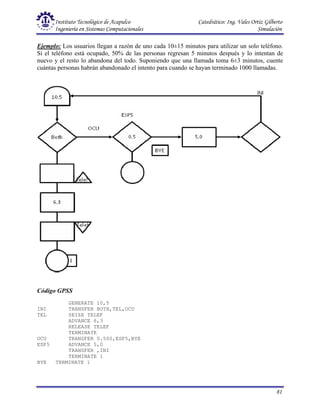
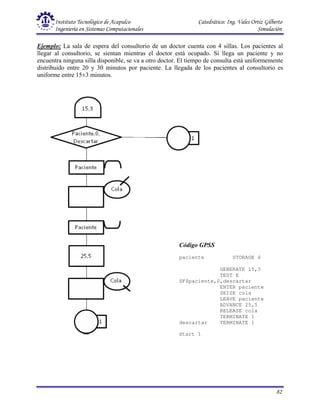
Este documento presenta una introducción a la simulación. Explica que la simulación consiste en construir modelos informáticos que describen el comportamiento de un sistema complejo para analizarlo y tomar decisiones. Describe el proceso de simulación, incluyendo las actividades de presimulación, desarrollo y operación. También define conceptos clave como variables exógenas, de estado y endógenas, y explica consideraciones relativas a la simulación como el control de tiempo y generación de números aleatorios.
















![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
18
discutiremos después de introducir algunas anotaciones adicionales. Sea I(t) el nivel del
inventario en el tiempo t[ note que I(t) podría ser positivo, negativo o cero]; sea I+
(t)= max
[I(t),0] el número de artículos físicamente disponibles en el inventario en el tiempo t[note que
I+
(t)≥0]; y I-
(t)= max [-I(t),0] los pendientes en el tiempo t[I-
(t)≥0 también]. Una posible
realización de I(t), I+
(t), I-
(t) se muestra en la figura 1.41. Los puntos en el tiempo que I(t)
decrece son los únicos en los cuales la demanda ocurre.
I(t): Nivel del inventario en el tiempo t, siendo el valor de t positivo, negativo o cero.
I^+(t)=max {I(t),0}: Es el número de artículos físicamente disponibles en el tiempo t del
inventario.
El tiempo de los puntos al cual I(t) decrece son los únicos puntos donde ocurre la demanda.
Para nuestro modelo, debemos asumir que la compañía incurre en un costo de
mantenimiento de h=1 por artículo por mes mantenido en el inventario. El costo de
mantenimiento incluye tales costos como la renta del almacén, seguros, impuestos, y
mantenimiento también como el costo de oportunidad de tener el capital en el inventario que
invertir en otra parte.
Hemos ignorado en nuestra formulación el hecho de que algunos costos de mantenimiento
ya incurrieron cuando I+
(t)=0. Sin embargo, dado que nuestro objetivo es comparar políticas de
ordenar, ignorando este factor, que después de todo es independiente de la política usada, no
afectará en nuestra evaluación de qué política es la mejor. Ahora dado que I+
(t) es el número de
Punto de Orden Orden de arribo Punto de Orden](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-18-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
19
artículos mantenidos en el inventario en el tiempo t, el tiempo promedio (por mes) número de
artículos mantenidos en el inventario por un periodo de n meses es
Que es semejante a la definición del número de tiempo promedio de clientes en la cola.
Así el tiempo promedio del costo de mantenimiento por mes es hI+
Similarmente, suponga que la compañía incurre un costo de déficit de ∏=$5 por artículo
por mes en déficit; esto cuenta para el registro de los costos extraguardado cuando existe un
déficit, también la perdida de buenos clientes. El número de promedio de veces de artículos en
déficit esta dado por es
Así que el costo promedio de atrasos por mes es ∏I-
.
Asuma que el nivel de inventario inicial es I(0)=60 y que no ordenar no es importante.
Simulemos el sistema de inventario para n = 120 meses y use el costo total promedio por mes
(que es la suma del costo de ordenar promedio por mes, el costo de mantenimiento promedio por
mes y el costo de déficit promedio por mes) para comparar las siguientes nueve políticas de
inventario.
s 20 20 20 20 40 40 40 60 60
S 40 60 80 100 60 80 100 80 100
No discutiremos aquí el resultado de cómo estas políticas particulares fueron elegidas para
su consideración, técnicas estadísticas para hacer tal consideración serán discutidas más adelante.
Note que las variables de estado para un modelo de simulación de este sistema de
inventario son el nivel de inventario I(t), la cantidad de una orden prominente de la compañía al
proveedor, y el tiempo del ultimo evento.[el cual es necesaria para calcular las áreas bajo las
funciones I+
(t) e I-
(t)]](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-19-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
20
ORGANIZACIÓN Y LÓGICA DEL PROGRAMA
El modelo de sistema de inventario usa los siguientes tipos de eventos.
Descripción del evento Tipo del evento
Llegada de una orden a la compañía del proveedor 1
Demanda para el producto de un cliente 2
Termino de la simulación después de n-meses 3
Evaluación del inventario (al inicio de mes) 4
Hemos tenido que hacer el fin de la simulación, como un evento de tipo 3 en lugar del
tipo 4, ambos eventos “fin-simulación” y “evaluación-inventario” desde el tiempo 120 que serán
eventualmente programar y querer ejecutar el primer evento anterior en este tiempo. (Puesto que
la simulación se hace después del tiempo 120, no hay sentido en la evaluación del inventario y un
posible ordenamiento, incurriendo en un costo de ordenar por una orden que nunca llegará). La
ejecución del evento tipo 3 antes del evento tipo 4 es garantizado por que la rutina del tiempo da
preferencia al mas bajo evento numerado, si dos o mas eventos son programados para ocurrir al
mismo tiempo. En general un modelo de simulación sería designado a procesar eventos en un
orden apropiado cuando un ciclo de tiempo ocurra.
La grafica de un evento aparece en la figura 1.42
Hay tres tipos de variables aleatorias que se necesitan para simular este sistema. Los
tiempos indeterminados son distribuidos exponencialmente, así que el mismo algoritmo (y
código) como se desarrollo en la sección 1.4 pueden ser usados aquí.
El tamaño de demanda de la variable aleatoria D deberá ser discreta, como se describió
anteriormente, y puede ser generada como sigue. Primero se divide el intervalo unitario en
subintervalos contiguos C1 [0, 1/6), C2=[1/6, 1/2), C3=[1/2, 5/6), y C4=[5/6,1], y se obtiene una
variable aleatoria uniformemente distribuida en el intervalo U(0,1), si U cae en C1, regresa D=1;
si U cae en C2, regresa D=2 ; y así sucesivamente.
Orden de
llegada
Demanda Evaluación
Termino de
la simulación](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-20-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
21
Evento de
orden de llegada
Incremento del nivel de
inventario por la cantidad
previamente ordenada
Eliminar evento de orden de
llegada de consideración
Regreso
Por tanto el ancho de C1 es 1/6–0=1/6 , y por tanto U (generador de Nº aleatorios) es
uniformemente distribuido sobre [0,1] , la probabilidad que U caiga en C1, (y así que regresamos
D=1) es 1/6; esto concuerda con la probabilidad deseada que D=1, similarmente regresamos a
D=2, si U cae en C2 teniendo una probabilidad igual al ancho de C2, ½ - 1/6= 1/3, como se
deseó y así para los siguientes intervalos.
Los subprogramas para generar los tamaños de demandas todos usan estos principios y
toman como entrada el interruptor de puntos definiendo los subintervalos de llegada anterior los
cuales son las probabilidades acumuladas de la distribución de D.
Los atrasos en las entregas son uniformemente distribuidos pero no sobre el intervalo
unitario [0,1]. En general podemos generar una variable aleatoria uniformemente distribuida
sobre cualquier intervalo [a,b] generando un numero aleatorio U(0,1) y después regresar a
a+U(b – a).
De los cuatro eventos solamente 3 involucran verdaderamente el cambio de estado (el
termino de eventos de simulación es la excepción) por lo tanto su lógica, es un lenguaje
independiente.
En el evento llegada – orden, se muestra en la figura 1.43 y debemos hacer los cambios
necesarios cuando una orden llegue del proveedor. El nivel del inventario es incrementado y
desde su consideración del evento llegada de una orden debe ser eliminada.
Evento de Orden de Llegada](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-21-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
22
Evento evaluación
del inventario
Si
I(t)<s?
Determine la cuenta de
orden [S – I(t)]
Costo de orden incurrido y
recoger estadísticas
Programar el evento orden
de llegada para esta orden
Programar el próximo
evento evaluación del
inventario
Return
El evento de la demanda está dado en la figura 1.44 y procesa los cambios necesarios para
representar un caso de demanda. Primero, el tamaño de la demanda es generada, y el inventario
es decrementado por esta cantidad. Finalmente el tiempo de la próxima demanda es programada
en la lista de eventos. Note que esto ocurre donde el nivel del inventario pueda ser negativo.
El evento evaluación del inventario tiene lugar en el comienzo de cada mes, su diagrama
de flujo es el siguiente. Fig. 1.45
Si el nivel del inventario I(t) en el tiempo de evaluación es al menos s, entonces ninguna
orden se coloca, y no se hace nada excepto la programación de la siguiente evaluación en la lista
de eventos. En cambio, si I(t)<s, colocamos una orden para S – I(t) artículos. Esto es hecho para
almacenar la cantidad de ordenar [S – I(t)]hasta la llegada de la orden, y programar su tiempo de
llegada. En este caso también, queremos programar el próximo evento evaluación del inventario.
Como en el modelo de colas de un solo servidor, es conveniente escribir una rutina para
actualizar los acumuladores de la estadística de tiempo continuo. Para este modelo, sin embargo,
haciendo esto ligeramente mas complicado, daremos al diagrama de flujo.](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-22-320.jpg)





![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
28
5.- an2 = (0101)(1111) = 01001011
n3 = 1011 r3 = 11/16 = 0.6875
6.- an3 = (0101)(1011) = 00110111
n4 = 0111 r4 = 7/16 = 0.4375
y así sucesivamente...
Computadoras Decimales
m = 10d
= 2d
5d
d = número de dígitos decimales de la palabra. d>3
a = debe ser número primo relativo de 10d
El orden h de a (mod 10d
) es: h = m.c.m. [2d-2
,4 * 5d-1
] = 5 * 10d-2
Los multiplicadores constantes con período 5 * 10d-2
se pueden ubicar en 32 clases
residuales distintas mod 200, dado por:
a = ± (3, 11, 13, 19, 21, 27, 29, 37, 53, 59, 61, 67,69, 77, 83, 91) (mod 200)
ó también se puede expresar como:
a = 200t ± p t = 0, 1, 2, 3, ...
p = uno de los 32 números dados anteriormente.
De igual modo n0 debe ser primo relativo de m = 10d
, lo cual implica que tiene que ser
impar, no divisible entre 5 para seleccionarse como valor inicial.
a ≈ 10d/2
El procedimiento es semejante al caso binario:
1. Selecciónese n0, un número impar no divisible entre 5.
2. Selecciónese a = 200t ± p
a ≈ 10d/2
3. Calcular an0 utilizando aritmética entera de punto fijo.
4. Calcular r1 = n1/10d
5. Cada número aleatorio subsecuente ni+1 se obtiene a partir de los dígitos de
menor orden del producto ani.](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-28-320.jpg)




![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
33
2
α
x
i
l
x
s
l
2
α
2
1
=
µ
n
Z
x
i
12
2
2
1
α
+
=
l
n
Z
x
s
12
2
2
1
α
+
=
l
2
1
1
2
1
0
≠
=
=
=
µ
µ
H
H
Ejemplo: Generar números aleatorios dados por la siguiente función
( )
100
mod
3
1 n
n X
X =
+
( ) ( ) ( ) ( )
[ ]
( ) ( ) ( )
[ ]
( ) ( )
( ) ( )
( ) [ ]
( )
43
20
100
20
20
,
2
.
.
100
20
5
4
5
1
5
25
2
2
1
2
1
2
4
5
,
2
.
100
,
,
,
.
.
2
5
2
5
5
2
2
25
2
2
50
2
100
0
1
2
1
2
2
2
2
1
2
2
2
1
=
=
=
=
=
=
⋅
=
−
=
=
⋅
=
−
=
=
=
=
=
⋅
⋅
⋅
=
⋅
⋅
=
⋅
=
−
−
X
h
m
c
m
cm
m
P
P
P
m
c
m
m
d
s
e
s
e
e
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ K
Pruebas de frecuencias
( ) ( ) ( ) ( ) ( )
49
.
9
4
4
4
4
4
4
4
4
4
4
0
4
5
4
,
05
.
0
2
2
2
2
2
2
2
1
2
1
5
20
2
1
2
1
=
−
+
−
+
−
+
−
+
−
=
=
=
=
=
−
= ∑
=
χ
λ
χ
χ
x
N
x
j
j
x
x
N
f
N
x
Pruebas de medias
n Xn rn
1 29 0.29
2 87 0.87
3 61 0.61
4 83 0.83
5 49 0.49
6 47 0.47
7 41 0.41
8 23 0.23
9 69 0.69
10 7 0.07
n Xn rn
11 21 0.21
12 63 0.63
13 89 0.89
14 67 0.67
15 1 0.01
16 3 0.03
17 9 0.09
18 27 0.27
19 81 0.81
20 43 0.43
21 29 0.29
Sub int Fj
0 - 0.2 4
0.2 - 0.4 4
0.4 - 0.6 4
0.6 - 0.8 4
0.8 - 1 4
α = nivel de confianza de la prueba
α = 1% o 5%
n
x
X
∑
=](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-33-320.jpg)




![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
38
( ) ( )
∑
∑ =
=
−
=
−
=
16
1
2
1
2
2
1
8125
.
1
8125
.
1
i
i
m
i i
i
i FO
FE
FO
FE
χ
( ) ( ) ( )
[ ] 75
.
5
3
8125
.
1
4
2
8125
.
1
5
1
8125
.
1
7
8125
.
1
1 2
2
2
2
1 =
−
+
−
+
−
=
χ
El valor de la tabla χ2
con un nivel de confianza del 95% y con 15 grados de libertad es
igual a 25. Si se compara χ1
2
=5.75 con este valor, se acepta la independencia de la secuencia de
números.
15
,
05
.
0
2
2
1 χ
χ ≤
Por consiguiente Ho se acepta.
Ejemplo:
Realice la prueba de Poker y la prueba de series a los siguientes 30 números con un nivel
de confianza de 95%
Prueba de poker
( ) ( ) ( ) ( ) 003
.
0
135
.
0
27
.
0
24
.
3
24
.
3
3
16
.
2
16
.
2
5
12
.
15
12
.
15
15
072
.
9
072
.
9
7
2
2
2
2
2
1 +
+
+
−
+
−
+
−
+
−
=
χ
11
.
2
2
1 =
χ
6
.
12
2
6
,
05
.
0 =
χ
2
6
,
05
.
0
2
1 χ
χ <
0.03991 0.24122 0.10461 0.66591 0.93716 0.27699
0.38555 0.61196 0.95554 0.30231 0.32886 0.92962
0.17546 0.30532 0.73704 0.21704 0.92052 0.10274
0.32643 0.03788 0.52861 0.97599 0.95189 0.75867
0.69572 0.48228 0.68777 0.63379 0.39510 0.85783
Evento PE FO FE
Pachuca 0.3024 7 9.072
Par 0.5040 15 15.12
Tercia 0.0720 5 2.16
2 Pares 0.1080 3 3.24
Full 0.0090 0 0.27
Poker 0.0045 0 0.135
Quintilla 0.0001 0 0.003](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-38-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
39
3
1
3
2 1
3
1
3
2
1
Prueba de series
IIIIII
6
II
2
III
3
III
3 0
IIII
4
III
3
IIIII
5
III
3
22
.
3
9
29
=
=
FE
( ) ( ) ( ) ( ) ( ) ( )
[ ]
2
2
2
2
2
2
2
1 22
.
3
6
22
.
3
5
22
.
3
4
22
.
3
3
4
22
.
3
2
22
.
3
0
22
.
3
1
−
+
−
+
−
+
−
+
−
+
−
=
χ
31
.
7
2
1 =
χ
51
.
15
2
8
,
05
.
0 =
χ
2
8
,
05
.
0
2
1 χ
χ <](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-39-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
40
Apéndice A
Elementos de la teoría de números
A fin de comprender totalmente y apreciar los métodos para generar números
pseudoaleatorios que se consideran, es requisito previo tener un conocimiento básico de los
elementos de la teoría de los números. El apéndice A contiene un conjunto básico de definiciones,
ejemplos y teoremas de la teoría de números que resultan pertinentes para la comprensión de los
fundamentos racionales sobre los que se basan los métodos.
Definiciones
Definición 1. Para dos enteros a y b, con b ≠ 0, existe un único par de enteros t y n, tal que a = bt
+ n 0 ≤ n < b, en donde t es el cociente n es el residuo.
Definición 2. Un entero a es divisible entre un entero b si existe un entero t tal que bt
a =
Definición 3. Un entero p es un número primo si no es 0 ni ± 1 y si sus únicos divisores son ±1 y
± p. Por ejemplo, los primeros primos positivos son 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37.
Definición 4. Un entero g es el máximo común divisor (m.c.d.) de dos enteros a, b, si g es un
divisor común de a y b, además es un múltiplo de cualquier otro divisor común de a y b.
Notación: m.c.d. (a,b) = g, o similar a (a b) = g.
Definición 5. Un entero d es el mínimo común múltiplo (m.c.m.) de dos enteros a y b si d es un
divisor de cada múltiplo común de a y de b, y es a su vez un múltiplo común. Notación: m.c.m.
[a, b] = d o [a, b] = d.
Definición 6. Se dice que los enteros a y b son primos relativos si (a, b) = 1.
Definición 7. Dos enteros a y b son congruentes módulo m si su diferencia es un múltiplo entero
de m. La relación de congruencia se expresa por la notación a ≡ b (mod m), que se lee “a es
congruente con b módulo m”, esto también significa que:
1) (a-b) es divisible entre m, y
2) a y b dan el mismo residuo al ser divididos entre m.
Ejemplo: 5590 ≡
≡
≡
≡ 6 (mod 8) y 2327 ≡
≡
≡
≡ 27 (mod 102
).
Definición 8. Para una a dada, el menor entero positivo n tal que a ≡ n (mod m) recibe el nombre
de residuo módulo m. Existe m residuos distintos (mod m); 0, 1, 2, . . .,m – 1.
Definición 9. Una clase de enteros mutuamente congruentes para un módulo dado, forman una
clase residual. Existen m distintas clases residuales (mod m). Ejemplo: si m=2, las dos clases](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-40-320.jpg)

![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
42
(2) a = 3, m = 31, ϕ (m) = 30
i ai
ni i ni i ni
1 3 3 11 13 21 15
2 9 9 12 8 22 14
3 27 27 13 24 23 11
4 81 19 14 10 24 2
5 243 26 15 30 25 6
6 729 16 16 28 26 18
7 2187 17 17 22 27 23
8 6561 20 18 4 28 7
9 19683 29 19 12 29 21
10 59049 25 20 5 30 1*
• La sucesión de los residuos potenciales se repite para potencias de orden superior.
Teoremas
Teorema 1. Si a ≡ b(mod m) y x ≡ y(mod m), entonces a ± x ≡ b ± y(mod m), y ax ≡ by(mod m).
Teorema 2. Si (d, m) ≡ g, entonces dx ≡ dy (mod m) implica que x ≡ y (mod m/g).
Teorema 3. Si a ≡ b (mod m) y d es un divisor de m, entonces a ≡ b (mod d). Las
demostraciones de los teoremas 1, 2 y 3, resultan de la definición [2 p.24].
Teorema 4. Cualquier entero m (distinto de 0 ó ± 1) se puede factorizar de forma única en
números primos, esto es, m = π piei
, (i = 1, 2, 3, . . .), donde ei es una constante y π denota al
producto p1ei
x p2
e2
x p3
e3
. . . La prueba de esto se debe a Euclides [2, p.21].
Teorema 5. Si (a, m) = 1, entonces aϕ(m)
≡ 1 (mod m), de lo cual se sigue que:
1. El mayor orden posible de a es h = ϕ(m) cuando a es una raíz primitiva de m.
2. Para n < m tales que (m, n) = 1, nah
≡ n (mod m), donde h = ϕ(m). La prueba de
esto se atribuye a Euler y se obtiene de los teoremas 2 y 3.
Teorema 6. Para todas las potencias de un número primo p > 2 existen las raíces primitivas, i.e.
existe un número tal que (a, pe
) = 1 y aϕ(pe)
≡ 1 (mod pe
) donde h ≡ ϕ (pe
).
Teorema 7. Si m = πpi
ei
, entonces ϕ (m) = π(pi - 1)pi
ei-1
. La demostración se debe a Euler.
Teorema 8. Si m = πpe
y p es un primo impar entonces h = λ(m) = (p-1) pe-1
= ϕ (m) para valores
de a que son raíces primitivas de m.
Corolario: Si p = 2, i.e., h = λ(m) = 2e-2
para e > 2, entonces λ(m) ≠ ϕ (m). La prueba se
debe a Euler.](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-42-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
43
Teorema 9. Si m = πpi
ei
para i = 1, 2, 3, . . ., s, entonces:
1. λ(m) = m.c.m.[ λ(p1
e1
), λ(p2e2
), . . ., λ(pses
)].
2. Existe valores de a cuyo orden es igual a (esto es, pertenece conjuntamente a) cada
λ(pi
ei
). La demostración está en [21, p.293] y se sigue del teorema chino del
residuo debido a Sun-Tse [21, p.246].
Corolario: Si p1 = 2, entonces λ(m) = m.c.m. [λ(2e1
), ϕ(p2
e2
), ϕ(p3
e3
), . . .].
Teorema 10. El menor entero positivo a tal que (ah
- 1)/ (a - 1) ≡ 0 (mod m) es h = m, si (1) a ≡ 1
(mod p) si p es un factor primo de m y (2) a ≡ 1 (mod 4) si 4 es un factor de m. La prueba se
debe a Hull y Dobell.](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-43-320.jpg)

![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
45
( )
( )
2
1
4
3
2
1
4
3
4
3
4
3
4
1
4
3
4
1
1
−
=
−
=
−
+
=
+
= ∫
x
r
x
x
x
F
dt
x
F
x
Al considerarla función inversa de F ó F-1
(x) en caso de ser conocida, podemos hacer:
x0 = F-1
(r0).
Podemos de manera general establecer que: ( ) ( )
∫∞
−
=
=
x
dt
t
f
x
F
r
Entonces ( ) ( ) ( )
[ ] ( )
[ ]
x
x
F
p
x
F
r
p
x
F
x
x
p ≤
=
≤
=
=
≤ −1
Ejemplo:
Genérese los valores x de variables aleatorias con una función de densidad f(x) = 2x
0 ≤ x ≤ 1
( ) ∫
=
x
tdt
x
F
0
2
( ) 2
x
x
F
r =
= ó r
x = 1
0 ≤
≤ r
Ejemplo:
Genérese los valores x de variables aleatorias con función de densidad
4
1
1
0 ≤
≤ x
( )=
x
f
4
3
2
1 ≤
≤ x
1° parte 2° parte
( )
( )
4
4
4
1
0
x
r
x
x
F
dt
x
F
x
=
=
= ∫
F(x)
1
F(xi) = ri
0 xi X](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-45-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
46
Al tomar la transformación inversa y resolviendo:
r
x 4
= si 4
1
0 ≤
≤ r
3
2
3
4
+
= r
x si 1
4
1
≤
≤ r
Para generar un valor de x se debe en primer lugar generar un valor de r; cuando r < ¼
el valor de x estará determinado por x = 4r.
Si r > ¼ entonces x = 4
/3 r + 2
/3
Ejemplo:
Se desea simular una variable aleatoria con dn
exponencial ( ) x
e
x
f λ
λ −
= 0
≥
x
( ) ( )
( ) [ ] [ ] [ ]
( )
( ) ( ) r
x
r
x
x
r
e
r
r
e
x
F
e
e
e
e
x
F
dt
e
dt
e
x
F
t
t
t
t
x
t
t
x x
t
ln
1
ln
1
ln
1
1
1
1
1
0
0
0 0
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
λ
−
=
∴
−
−
=
∴
−
=
−
=
−
∴
=
−
=
−
−
=
−
−
=
−
=
−
=
=
−
−
−
−
−
−
−
−
∫ ∫
Ejemplo:
Se desea simular n números aleatorios con dn
uniforme entre (a,b):
( ) b
x
a
a
b
x
f ≤
≤
−
=
1
( )
( ) [ ] ( )
( )
( )
a
b
r
a
x
a
b
a
x
r
a
b
a
x
x
F
a
b
a
x
t
a
b
x
F
dt
a
b
dt
a
b
x
F
x
a
x
a
x
a
−
+
=
−
−
=
−
−
=
−
−
=
−
=
−
=
−
= ∫
∫
1
1
1
1
( )
a
b
r
a
x
b
x
a
−
=
−
∴
≤
≤](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-46-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
47
Método De Rechazo
Este método requiere que f(x) sea una distribución de probabilidad acotada y con rango
finito ó a a ≤ x ≤ b.
Los pasos requeridos son:
1. Generar 2 números aleatorios r1 y r2
2. Determinar el valor de la variable aleatoria X de acuerdo a la relación lineal de r1:
X = a + (b-a)r1
3. Evaluar la función de probabilidad en x = a + (b-a)r1: ƒ[x = a+(b-a)r1]
4. Determinar si se cumple:
r2 ≤ ƒ[a+(b-a)r1]/M
M = es cota superior.
f(x)
M
a b X
Si r2 > f(x)/M entonces r1 y r2 se descartan y se seleccionan otros valores de r1 y r2
Ejemplo: Se desea generar números aleatorios con la distribución.
2x 0 ≤ x ≤ 1
f(x)
0 en otra parte
En este caso:
a = 0 b = 1 M = 2
1. Generar R1 y R2
2. Calcular x = r1
3. f(x) = 2r1
4. r2 ≤ 2r1 = 2r1 r2 ≤ r1 → x = r1
M 2](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-47-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
48
f(x) =
Ejemplo: Se desea generar variables aleatorias X para la siguiente densidad de probabilidad.
( )( )
( )
a
x
a
b
a
c
−
−
−
2
si a ≤ x ≤ b
( )( )
( )
c
x
b
c
a
c
−
−
−
− 2
si b ≤ x ≤ c
M=
)
(
2
a
c −
Como la función se compone de 2 partes:
f(x)
M
a b c X
Los pasos para simular esta distribución son:
1. Generar r1 y r2
2. Calcular x = a + (c – a)r1
3. Es x < b si la respuesta es afirmativa
( )
( )( )
( )
[ ]
( )
( )
a
b
r
a
r
a
c
a
a
b
a
c
x
f
−
=
−
−
+
−
−
= 1
1
2
2
si la respuesta es negativa, entonces f(x) es :
( )
( )( )
( )
( ) ( ) ( )
b
c
r
b
c
r
c
r
a
c
a
b
c
a
c
x
f
−
−
=
−
−
=
−
−
+
−
−
−
= 1
1
1
1
2
1
2
2
4. Es
( )( )
2
2
α
−
≤
c
x
f
r
Si la respuesta es afirmativa, entonces se considera como valor x = a + (c – a)r1 Simulada, en
caso contrario regresemos al paso 1.](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-48-320.jpg)
![Instituto Tecnológico de Acapulco Catedrático: Ing. Vales Ortiz Gilberto
Ingeniería en Sistemas Computacionales Simulación
49
( )
( ) [ ]
( )
4
3
3
4
4
3
4
3
0
4
3
0
4
3
0 ≤
≤
=
=
=
=
= ∫
r
r
x
r
x
F
t
x
F
dt
x
F
x
x
x
x
( )
( )
( )
8
15
8
9
4
3
8
9
8
9
8
9
8
9
4
3
3
2
4
3
4
3
3
5
4
3
4
3
1
2
1
2
1
1
1
1
1
0
+
−
=
+
+
−
=
+
−
=
−
−
−
=
−
−
−
−
=
−
−
−
−
=
−
+
=
x
y
x
y
x
y
x
y
x
y
x
x
x
x
y
y
y
y
b
mx
y
( ) ( )( )
( )
1
9
1
12
15
1
2
4
2
4
4
3
8
9
2
3
8
15
8
9
4
9
4
9
8
15
8
9
16
36
256
324
64
255
8
15
8
9
16
36
256
324
64
255
8
15
16
9
16
9
16
9
2
8
15
8
15
2
≤
≤
−
±
=
−
±
=
−
±
=
−
−
±
=
−
−
±
=
+
−
−
±
=
−
±
−
=
r
r
x
r
x
r
x
r
x
r
x
r
x
a
ac
b
b
x
( )=
x
f
8
15
8
9
+
− x
1
0 ≤
≤ x
3
5
1 ≤
≤ x
Ejemplo.
Calculando la segunda parte de la función 1° parte
2° parte
( ) ( )
( ) [ ]
( ) ( )
[ ]
( )
( )
0
16
9
8
15
2
16
9
16
9
8
15
2
16
9
16
9
8
15
2
16
9
8
15
16
9
8
15
2
16
9
4
3
8
15
16
9
8
15
2
16
9
4
3
1
8
15
16
9
4
3
1
8
15
8
9
4
3
2
=
+
+
−
−
+
−
=
−
+
−
=
−
+
+
−
=
+
−
−
+
−
+
=
+
−
+
=
+
−
+
= ∫
r
x
x
x
x
r
x
x
x
F
x
x
x
F
x
x
x
F
t
x
F
dt
t
x
F
x
t
x
Resolviendo la ecuación de segundo grado
mediante la fórmula general
4
3
4
3
3
5
( )
2
2 , y
x
( )
1
1, y
x
1
x
( )
x
f
0](https://image.slidesharecdn.com/institutotecnologicodeacapulco-apuntesdesimulacion-220323233311/85/Instituto_Tecnologico_de_Acapulco-APUNTES-DE-SIMULACION-pdf-49-320.jpg)