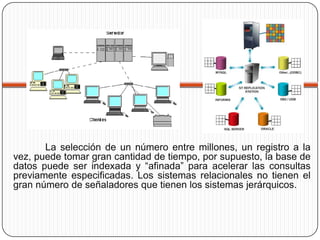
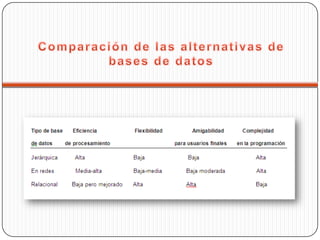
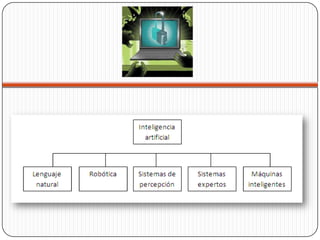
El documento describe los conceptos básicos de las bases de datos, incluyendo sus características, estructuras (jerárquica, red y relacional) y ventajas/desventajas. También cubre el diseño lógico y físico de bases de datos, así como una breve introducción a la inteligencia artificial.