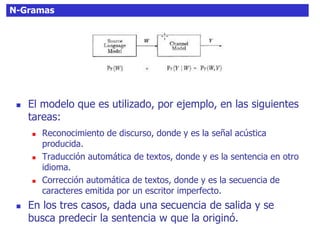
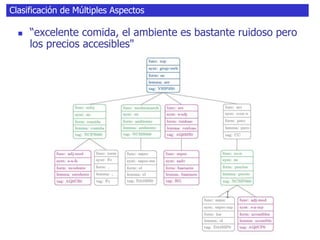
El documento habla sobre el análisis de sentimientos (sentiment analysis), explicando que consiste en identificar y extraer información subjetiva de textos no estructurados para determinar la actitud de un escritor. Explica que existen diferentes enfoques como clasificar la polaridad de un texto o identificar los aspectos mencionados y sus sentimientos asociados. También discute técnicas como n-gramas, detección de características, y modelos generativos vs discriminativos para realizar clasificación de sentimientos.