Descargado 28 veces








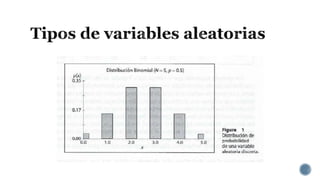















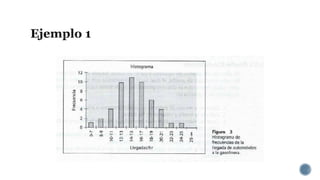



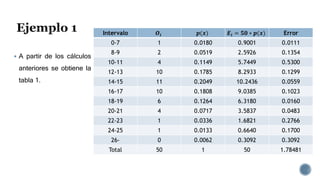

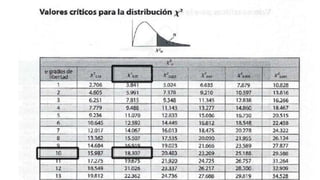


Este documento describe las variables aleatorias y sus distribuciones de probabilidad para la creación de modelos de simulación. Explica que las variables aleatorias pueden ser discretas o continuas y deben cumplir con reglas de distribución. También describe distribuciones comunes como la binomial, Poisson, normal y cómo determinar la distribución de datos históricos usando pruebas estadísticas.







































































































