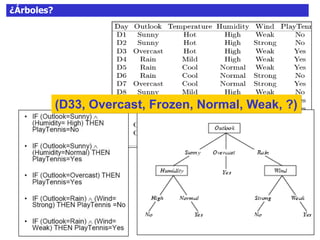
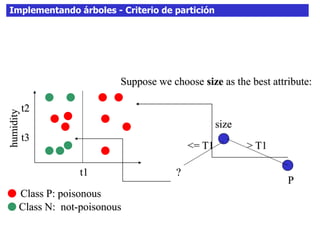
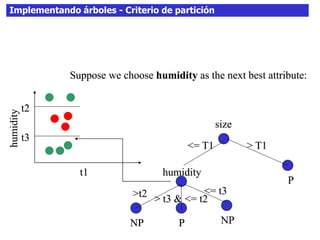
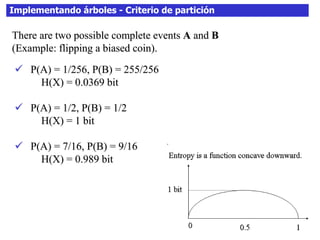
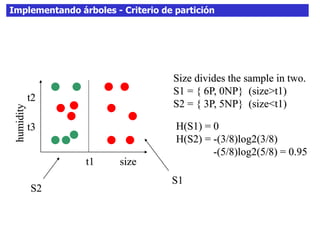
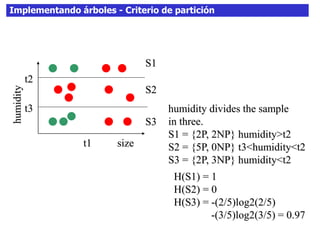
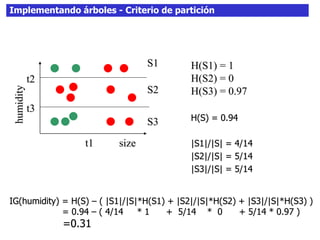
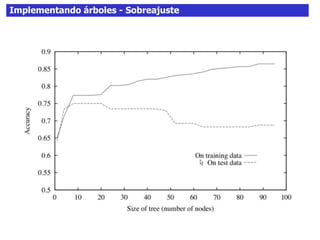
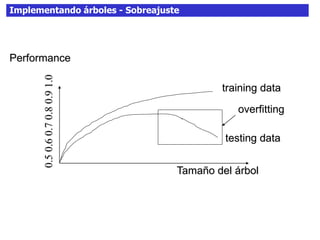
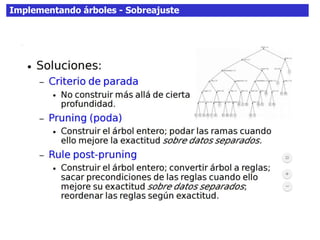
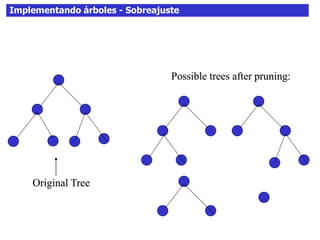
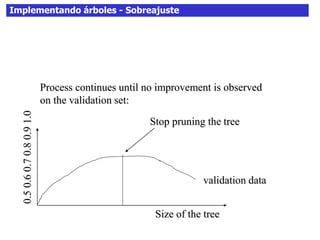
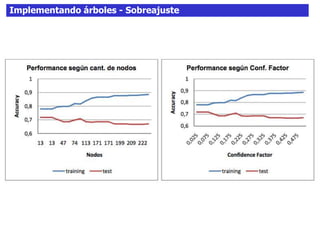
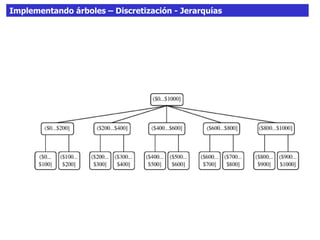
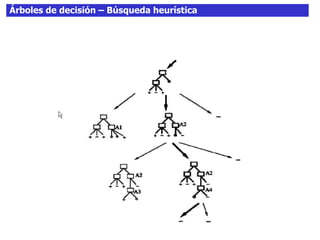
Este documento discute los árboles de decisión, incluyendo cómo inducir árboles a partir de conjuntos de datos clasificados, implementar árboles mediante criterios de partición y parada, y abordar problemas como el sobreajuste. Explica conceptos como la ganancia de información para seleccionar atributos y dividir los datos, así como diferentes enfoques para determinar la profundidad óptima de un árbol.