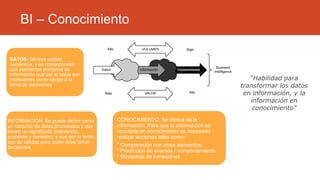
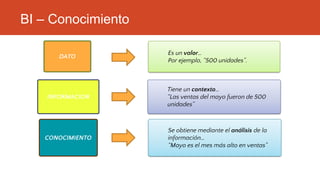
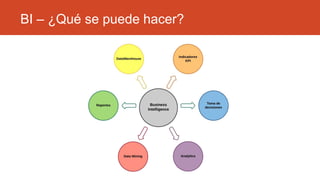
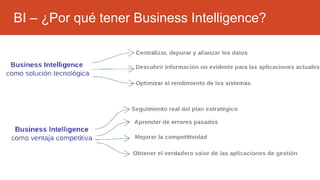
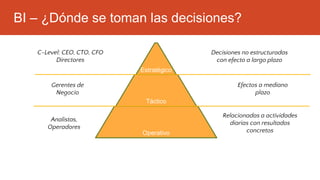
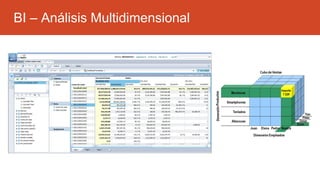
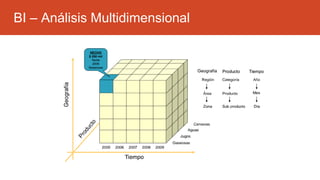
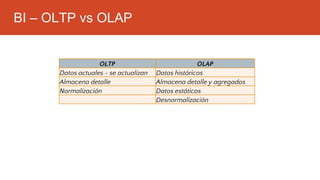
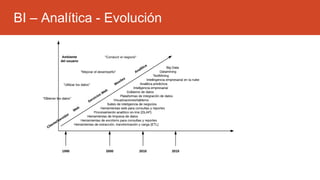
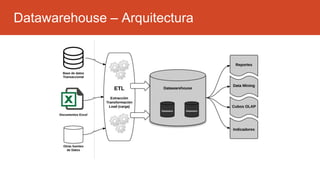
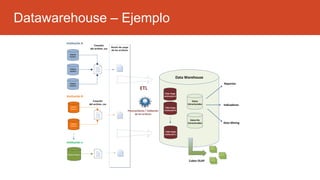
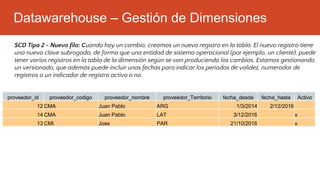
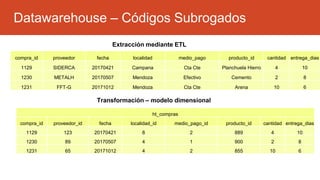
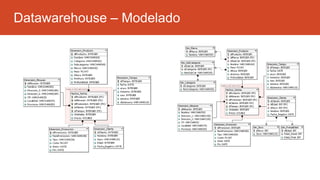
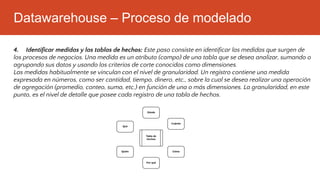
La inteligencia de negocios (BI) es el proceso de transformar datos en información y conocimiento para optimizar la toma de decisiones empresariales. A lo largo de su evolución desde la creación de bases de datos en 1969 hasta la consolidación de plataformas BI en los 2000s, se han desarrollado metodologías y herramientas que permiten el análisis de datos estructurados y no estructurados para identificar oportunidades de negocio. El data warehouse, como componente clave de BI, integra y organiza datos de diversas fuentes, facilitando el análisis multidimensional y la toma de decisiones informadas.