


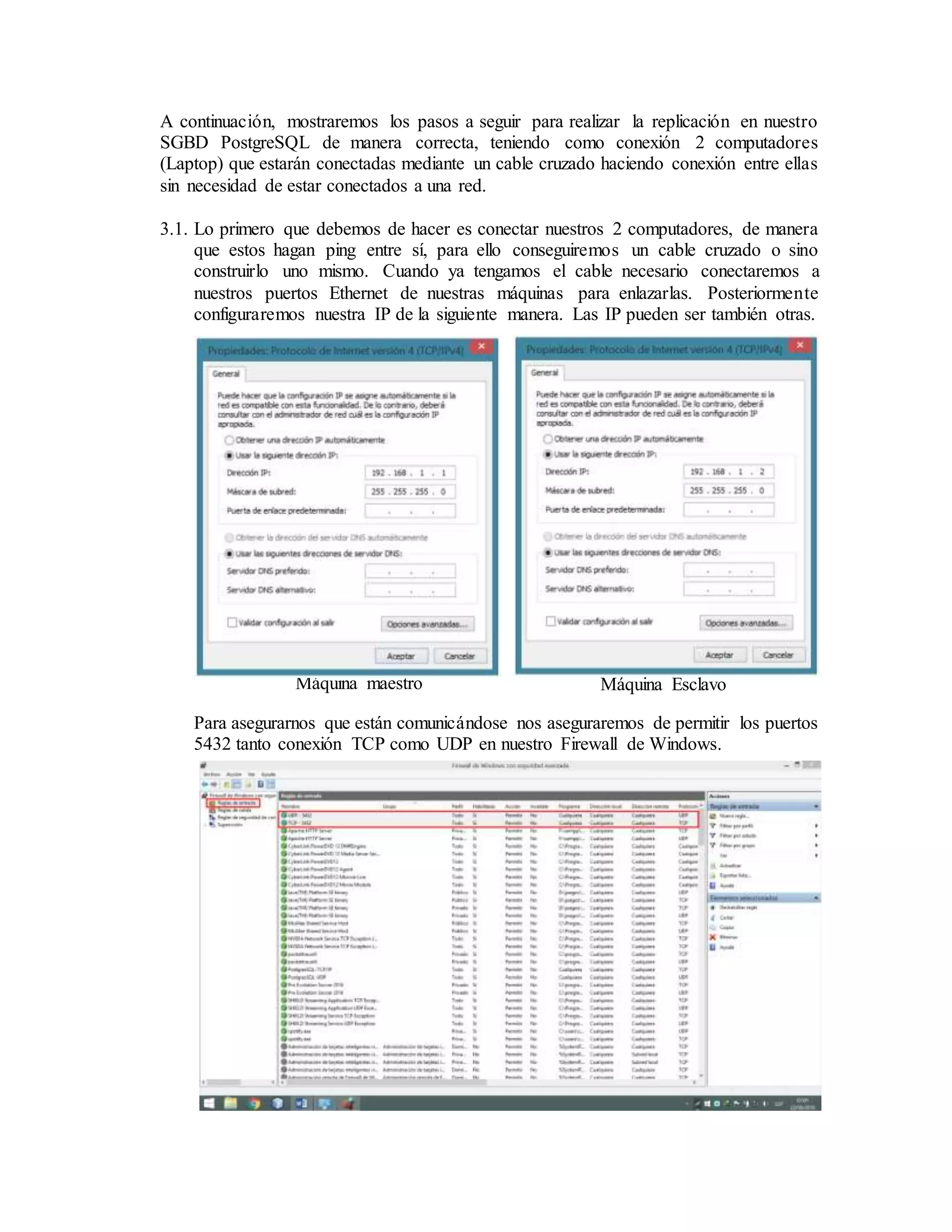
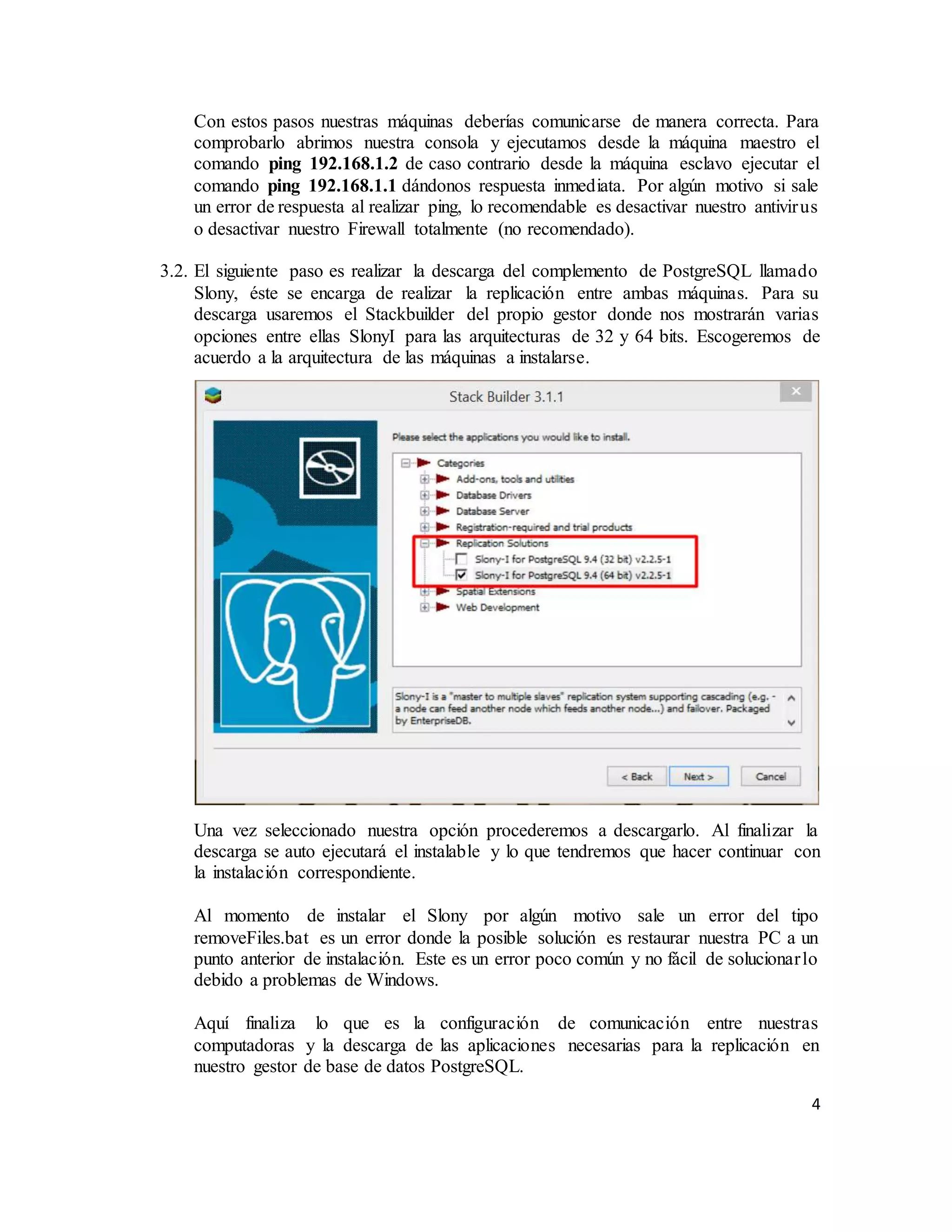
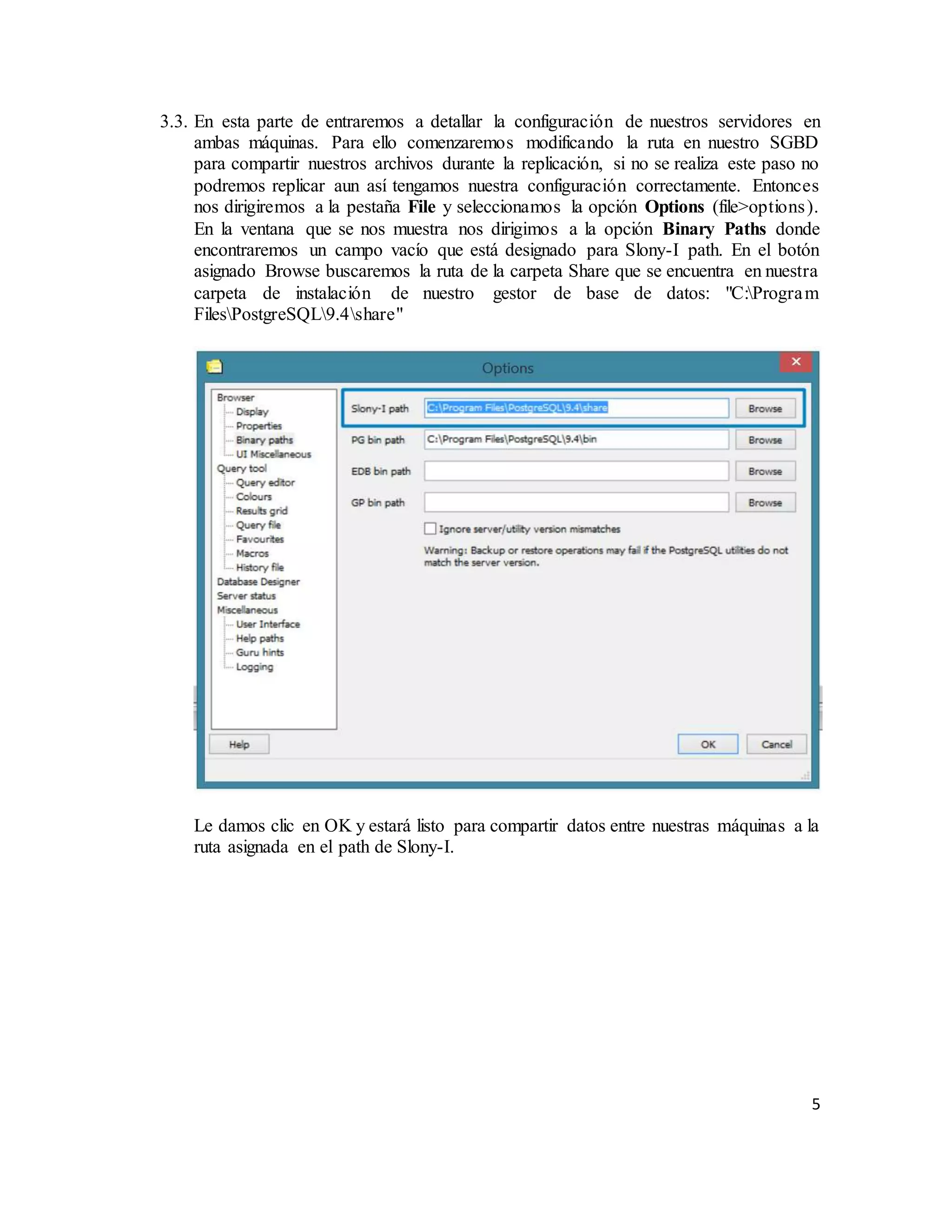

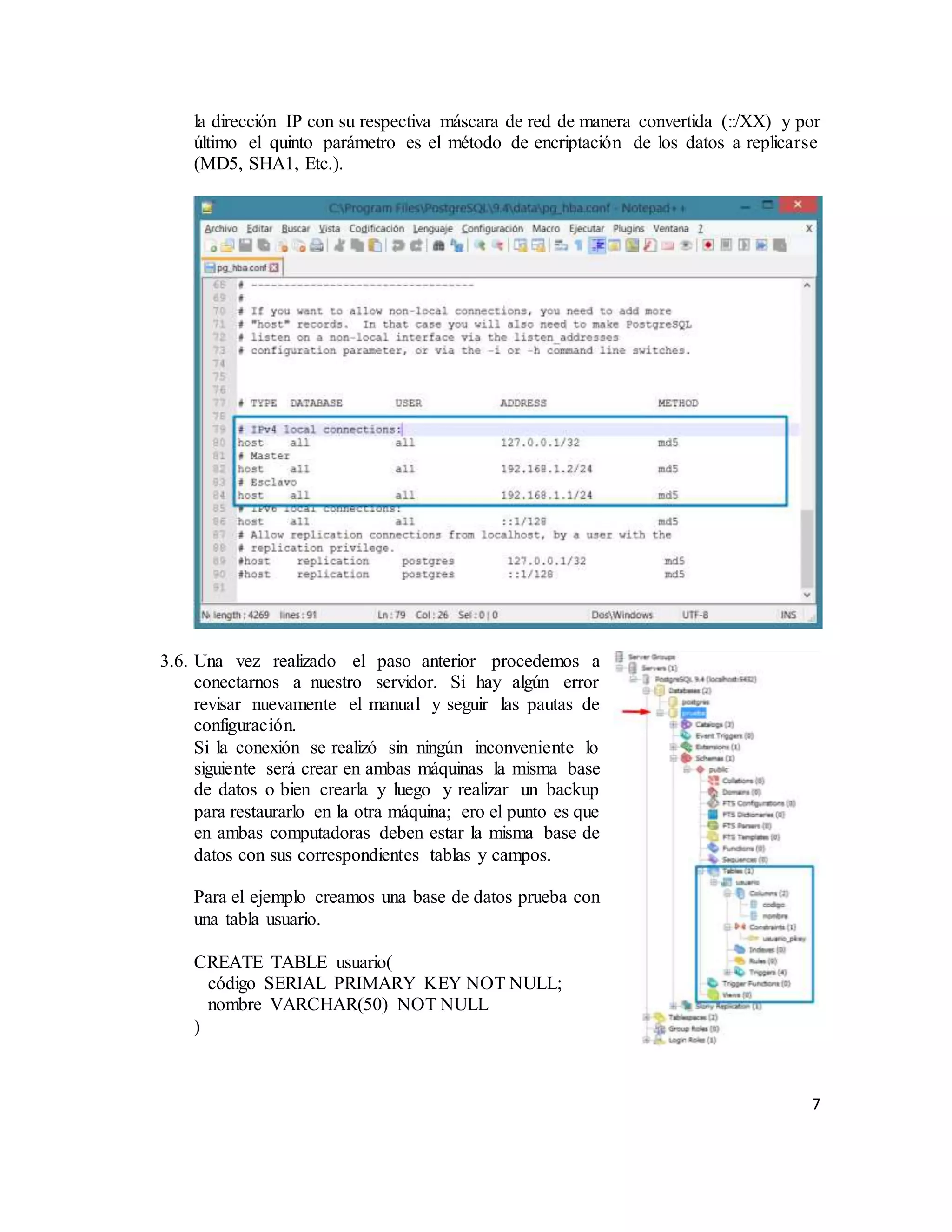
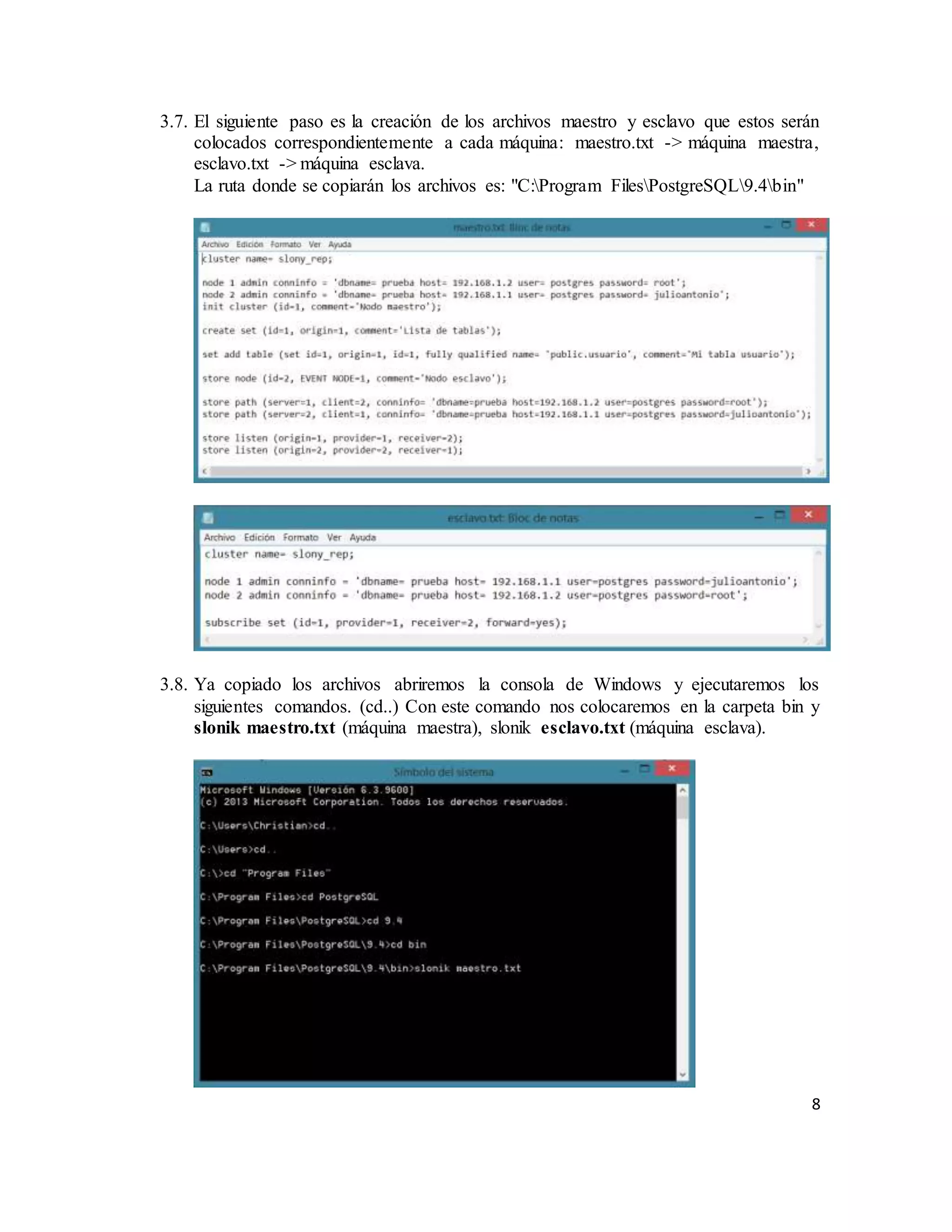
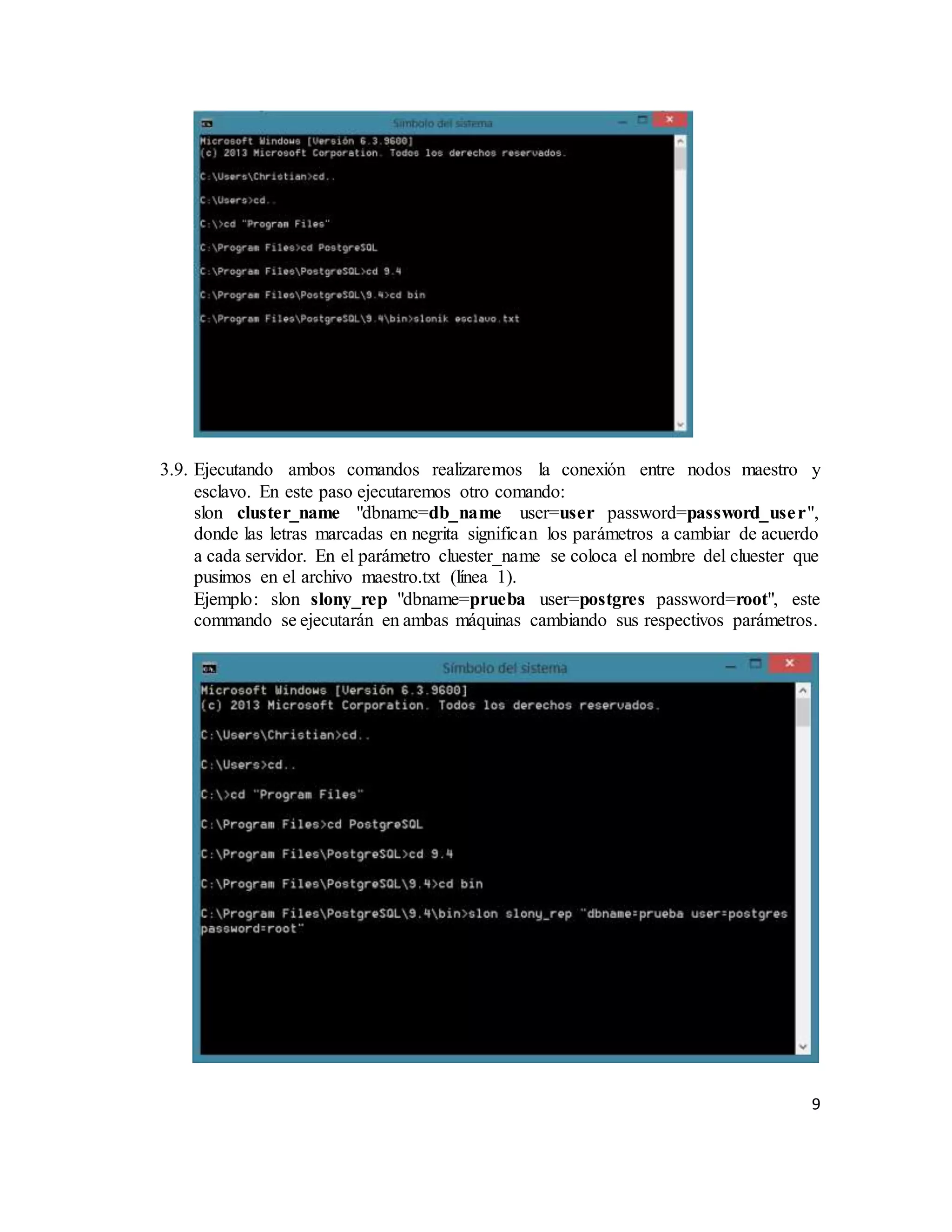
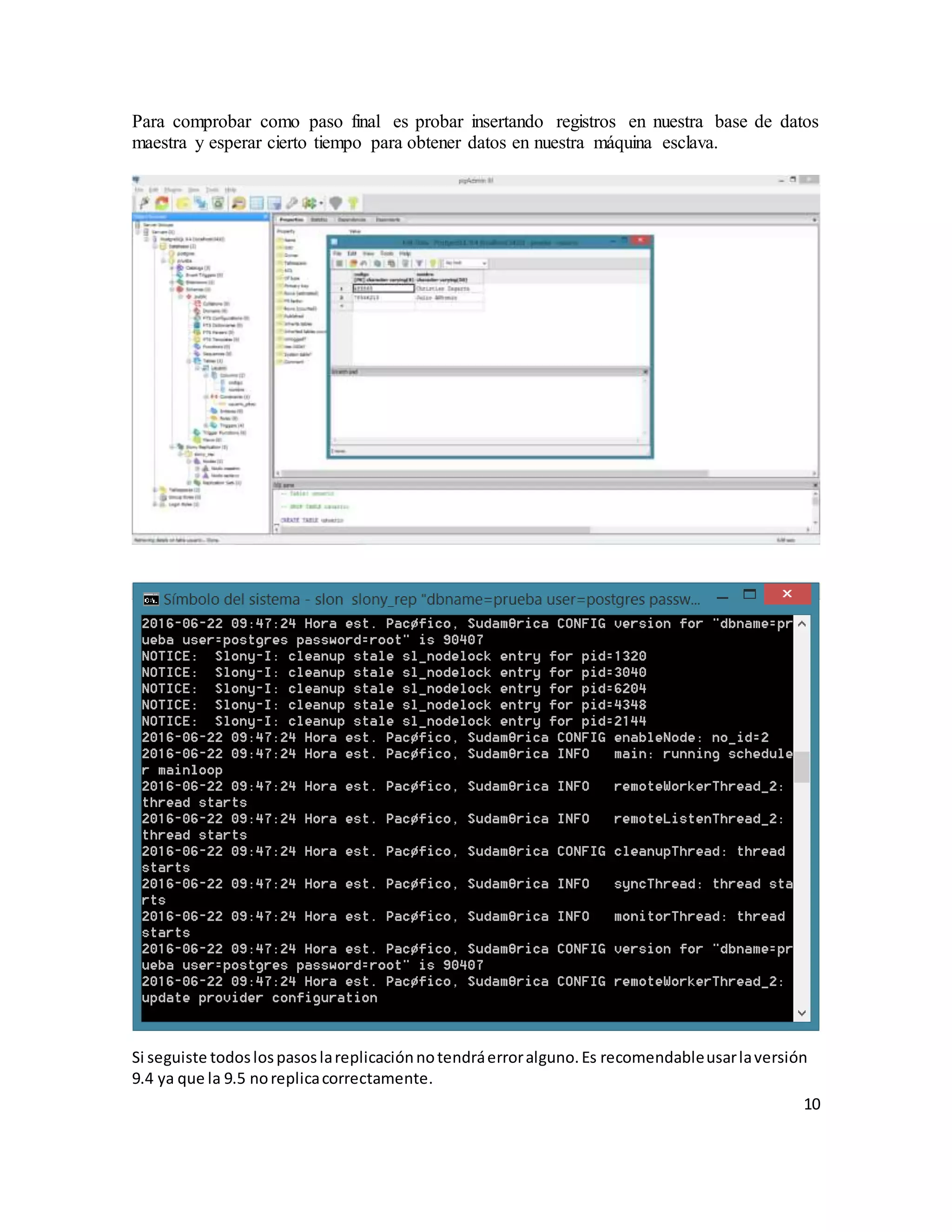

El documento describe la replicación de PostgreSQL 9.4 en sistemas operativos Windows, destacando su importancia para la disponibilidad, fiabilidad y rendimiento de aplicaciones distribuidas. Se explican los pasos necesarios para configurar la replicación entre dos computadoras utilizando el complemento Slony, desde la conexión de red hasta la configuración del sistema y la creación de bases de datos. Finalmente, se ofrecen instrucciones para comprobar la efectividad de la replicación al insertar datos en la base de datos maestra y verificar su aparición en la réplica esclava.



















































![Guía Aplicacion laserwayes_[GPON] [La Nueva Tendencia en Redes]](https://cdn.slidesharecdn.com/ss_thumbnails/2841guiaaplicacionlaserwayespjunho2015web-161026135123-thumbnail.jpg?width=640&height=640&fit=bounds)
![tcp_udp [Redes de Computadoras] [Semana 7]](https://cdn.slidesharecdn.com/ss_thumbnails/semana7tcpudp-161026133424-thumbnail.jpg?width=640&height=640&fit=bounds)
![api_de_socket [Explicación Completa]](https://cdn.slidesharecdn.com/ss_thumbnails/semana8apidesocket-161022124224-thumbnail.jpg?width=640&height=640&fit=bounds)

![Clase 01 - Introducción [Base de Datos Estratégica]](https://cdn.slidesharecdn.com/ss_thumbnails/clase01-bde-161016141739-thumbnail.jpg?width=640&height=640&fit=bounds)







![Bizagi [Descripción funcional]](https://cdn.slidesharecdn.com/ss_thumbnails/bizagidescripcionfuncional-160418150728-thumbnail.jpg?width=640&height=640&fit=bounds)























