

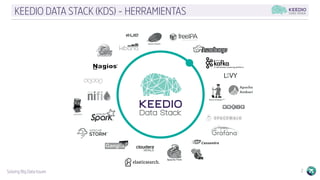
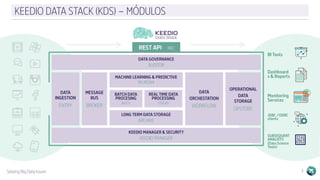



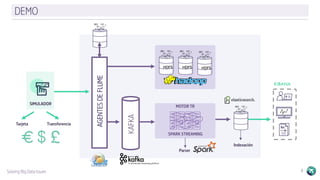
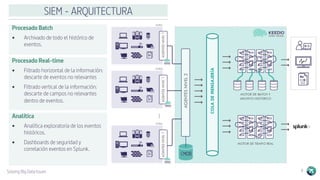


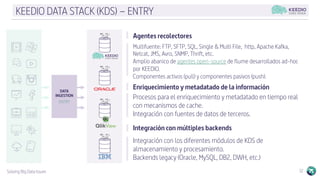
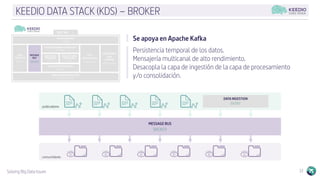
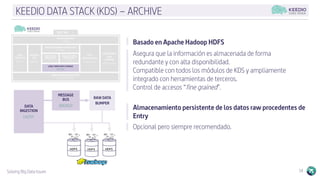







El documento describe la plataforma de datos Keedio Data Stack (KDS), que incluye múltiples módulos para la ingesta, almacenamiento, procesamiento y análisis de datos. Los módulos se basan en herramientas de código abierto como Apache Flume, HDFS, Kafka, Spark y Elasticsearch. La plataforma ofrece capacidades de ingesta de datos, procesamiento por lotes y en tiempo real, almacenamiento a largo plazo, orquestación de flujos de trabajo y análisis avanzado. La interfaz Keedio Manager



































































