Descargar como PDF, PPTX



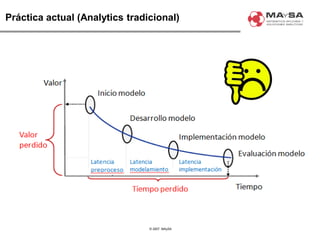


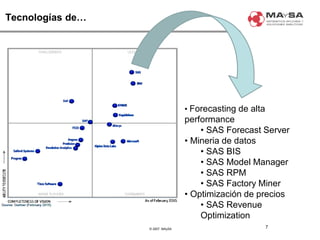

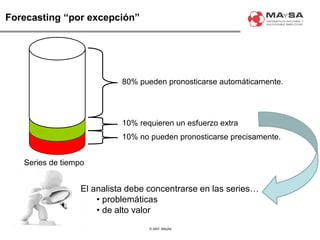


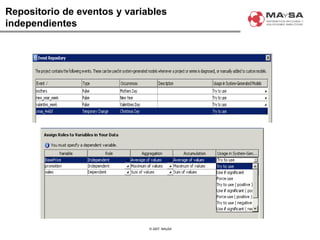

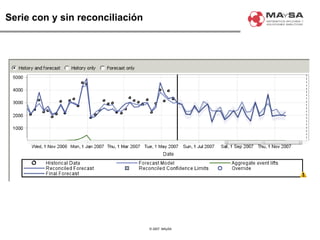

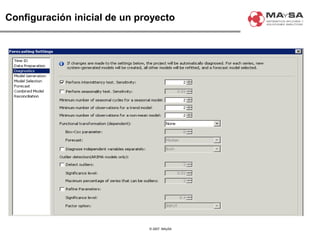



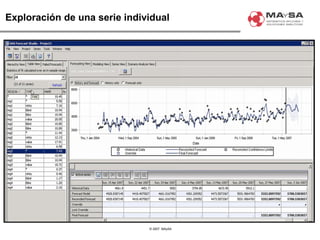



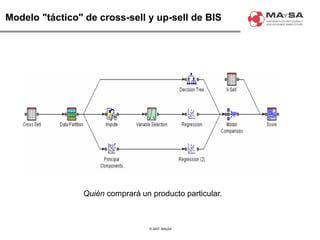

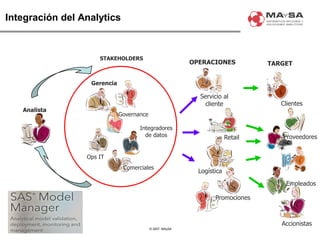





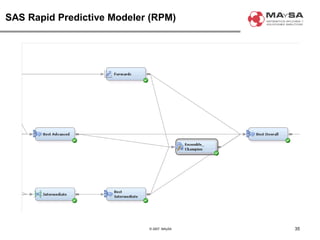




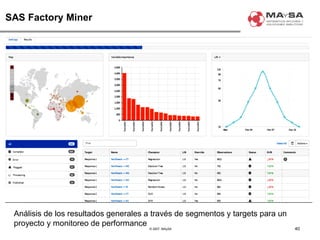





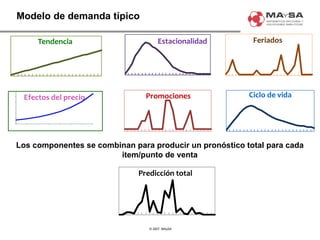














El documento aborda la automatización en el análisis de big data y la necesidad de agilizar el modelado predictivo para manejar grandes volúmenes de datos. Se discuten herramientas y tecnologías utilizadas en la automatización de modelos, así como el papel crucial del analista en la configuración y ajuste de estos modelos. También se identifican déficits en la automatización actual, como la necesidad de integrar diversas fuentes de datos y mejorar la sofisticación de los modelos utilizados.



























































![[Rosario] Soluciones de Análisis Predictivo - Adolfo Kvitca de SPSS](https://cdn.slidesharecdn.com/ss_thumbnails/9-120705105248-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































