Descargado 62 veces






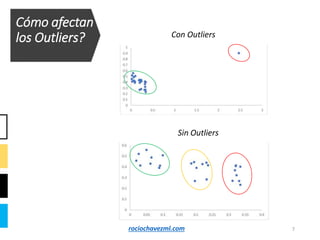
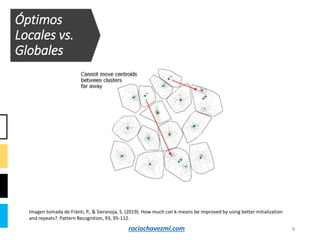



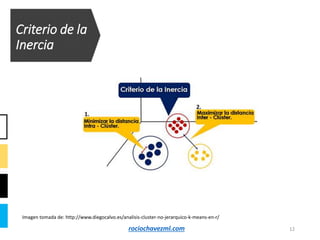


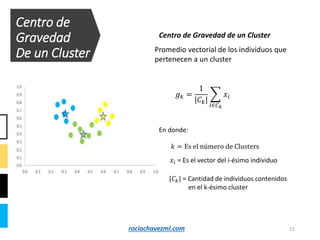
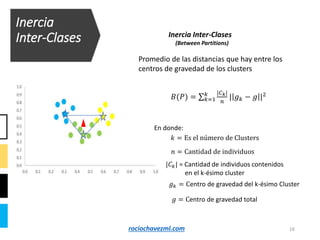

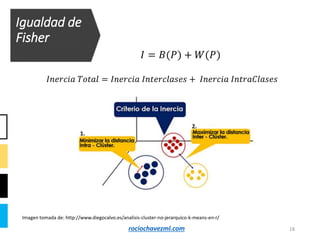

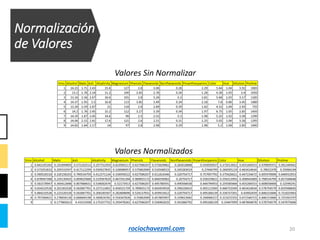



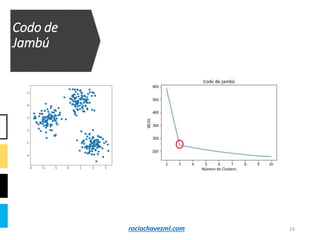



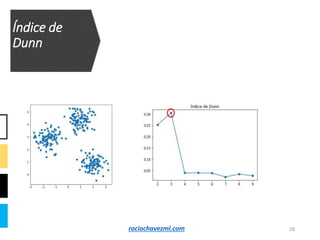


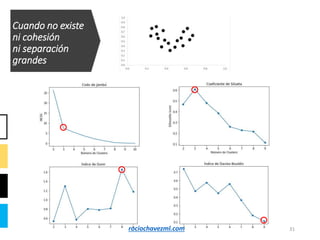



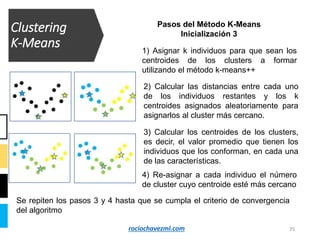



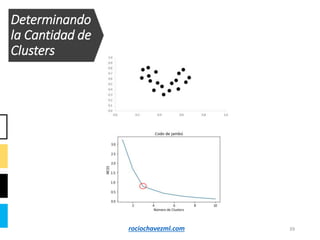




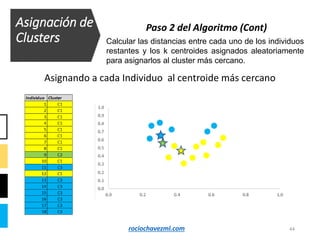

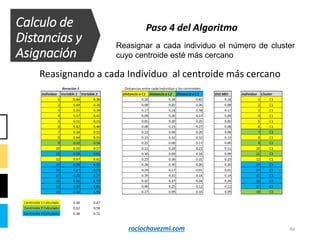

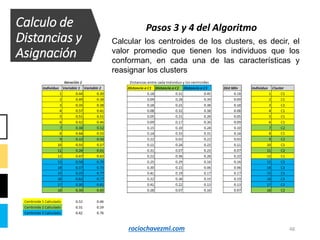




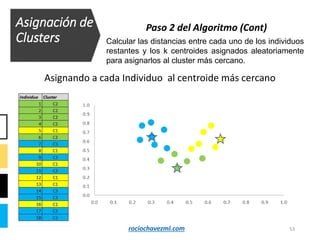
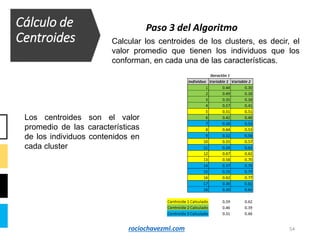



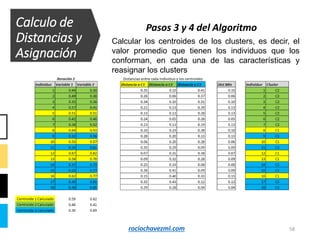



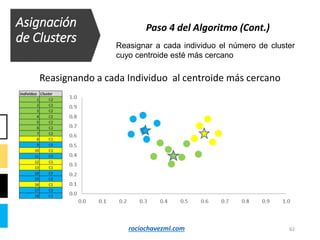
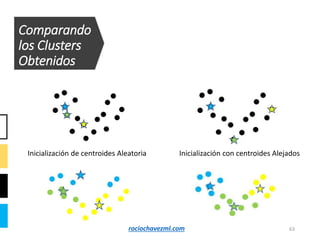

El documento detalla el método de clustering k-means, enfatizando sus aplicaciones y variaciones, así como sus ventajas y desventajas. Se abordan aspectos como la determinación del número de clusters, la cohesión y separación, y técnicas de normalización y eliminación de outliers. Además, se describen pasos y estrategias para optimizar la inicialización del algoritmo y los criterios de convergencia.



























































